Tips sobre la administración de Linux
Tips recogidos a lo largo de mi vida, que al no ser mucho uso, se van olvidando.
- Administración de usuarios
- Como eliminar kernels antiguos
- Seguridad, SSl, etc.
- Verificar versiones y ciphers soportados de TLS, SSL
- CSF error: *WARING* URLGET set to use LWP but perl module is not installed, fallback to using CURL/WGET
- Limitar en el tiempo (expirar en una fecha) una llave openSSH en el authorized_keys
- Comprobar una conexión SMTP autentificada en el shell con SSL o TLS
- CSF Firewall: añadir IPs al deny de forma definitiva.
- Certificados Letsencrypt sin servidor web o sin resolver en el servidor web
- Cambio de hostname permanentemente
- Hardware
- Conocer el hardware en linea de comandos (shell)
- Uso de UUID para montar particiones linux
- Instalación GPT con el instalador Centos 7 en discos < 2 TiB
- Parted mejor que fdisk
- Directadmin
- MySQL - MariaDb
- ERROR 1118 (42000) at line XXXXX: Row size too large (> 8126)
- Errores con MariaDB 10.3 al restaurar o hacer backups arrastrando versiones antiguas
- Como extraer de un backup de MySQL completo una base de datos y/o una tabla
- Como crear un usuario Mysql/MariaDB con Grant Privileges
- Restaurar mysqldump completo con problemas relacionados con VIEW y sus permisos
- Desactivación de las reglas de modos SQL de un sevidor MySQL/MariaDB/Percona
- ISPConfig
- Backups
- Rsync sobre sistemas remotos
- rsync-time-backup: include y exclude
- Diagnóstico y resolución de fallos en snapshots LVM durante backups en Proxmox
- Tips and Tricks
- Como convertir ficheros .flac a .mp3 en el shell de linux con ffmpeg
- Teclas Inicio (Home) y Final (End) en ZSH y oh-my-zsh con Powershell
- Linux, paquetes instalados desde el shell
- Cómo instalar y activar el repositorio EPEL en Centos 7/8
- Conocer el tamaño de unas carpetas ignorando los enlaces duros (rsync)
- Ssh se sale (break) de un ciclo (loop) en un script bash
- Redis Failed to start Advanced key-value store.
- Comando find con -maxdepth excluyendo el propio directorio
- Du y los ficheros o directorios ocultos
- Como vaciar o eliminar emails antiguos en dovecot sin usar find
- rc.local en systemas Debian usando systemd. Ejemplo redis
- Bad Bots y la pesadilla del tráfico. Htaccess en Apache 2.4
- Sudo sin contraseña
- Reparar el fichero .zsh_history: zsh: corrupt history file /home/USER/.zsh_history
- El archivo hosts para trabajar en un servidor o ip distinto del de la resolución DNS
- Cambiar repositorios de Ubuntu al mirror de OVH
- ## Guía Rápida de find - Búsquedas Avanzadas
- APT Upgrade - Modos Desatendido vs Manual
- Crear una unidad lógica con el 100%
- Búsqueda y reemplazo recursivo con sed en directorios
- Instalación de Node.js LTS 22 y npm en Ubuntu con CloudLinux CageFS
- PHP
- PHP log cuando usamos PHP-FPM con host virtuales
- PHP. Como instalar una nueva versión de PHP en un sistema basado DEB
- Activar PHP8.2 JIT Compiler - Just-In-Time compilation (JIT)
- Instalar una versión de PHP con módulos en Ubuntu con Ondrej copiando de otra versión ya instalada
- Proxmox
- Git pull, error: server certificate verification failed. CAfile: none CRLfile: none
- [PRIV] Instalar Proxmox desde 0
- LVM Práctico para Proxmox y OVH
- Red OVH vrack para Proxmox 7
- Como arreglar el error Sender address rejected: need fully-qualified address (in reply to RCPT TO command)
- Proxmox, Hetzner, y bloques de Ips adicionales en modo Routed
- Desactivar los mensajes de log en la consola (Proxmox)
- Proxmox: Servicios Colgados - Diagnóstico y Soluciones
- Ampliación de disco (basado en qcow2) en sistema virtualizado KVM (proxmox)
- Ampliación de disco en sistema virtualizado KVM (proxmox)
- IPv6 para VMs en Proxmox sobre OVH bare-metal (NDP proxy)
- NFS cliente en un sistema linux (rpm o debian)
- SSH
- Unable to negotiate with X.X.X.X.X port YY: no matching host key type found. Their offer: ssh-rsa,ssh-dss
- PasswordAuthentication yes pero no funciona
- Cambiar el puerto SSH en Ubuntu 24.04 y Debian Bookworm
- Apagando fuegos
- your CPU is missing AVX instruction set flag para instalar mongoDb Jetbackup entre otros
- Nginx
- Gestión de Versiones de PHP en Raspberry Pi
- Configuración correcta de Let's Encrypt en Webmin con
- Cosas de relays y postfix
- Zabbix
- Mysql-MariaDB
- Utilidades
Administración de usuarios
Administrar usuarios y grupos
Cambiar el username en linux
Cambiar el username o nombre de usuario
Muchas veces nos encontramos con situaciones en las que heredamos un sistema con usuarios, cuyo nombre queremos normalizar con nuestra infraestructura.
En un sistema Linux, sin panel de control, es una operación sencilla siempre que no exista ningún proceso del usuario ejecutandose.
sudo usermod -l nuevoNombreDeUsuario antiguoNombreDeUsuarioPero este comando solo cambiara el nombre del usuario, sin cambiar el nombre de su home.
Para cambiar el nombre del home del usuario ejecutaremos el código de abajo, después de haber ejecutado el anterior:
sudo usermod -d /home/nuevoHomeDir -m nuevoNombreDeUsuarioExplicación
Los sistemas Unix desacoplan el nombre de usuario de la identidad del usuario, por lo que es seguro cambiar el nombre del usuario sin afectar al ID. Todos los permisos, archivos, están vinculados a su identidad (uid), no a su nombre de usuario.
Para administrar todos los aspectos de la base de datos de usuarios, se utiliza la herramienta, usermod.
Tips
Algunos ficheros o programas pueden tener referencias absolutas a su antiguo directorio, por lo que se aconseja crear un enlace simbólico como forma de compatibilidad hacia atrás.
ln -s /home/nuevoNombre /home/viejoNombreAdvertencias
No usar con paneles de hosting, como cPanel, Directadmin, Plesk, porque el desastre puede ser mayúsculo. En su lugar tratar de localizar la documentación de ellos, y leer en sus foros, pues algunas veces sus propias herramientas pueden darte un buen disgusto.
Atención especial si el sistema esta encriptado. No he probado jamas este tip en esa situación.
Enlaces
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como esta, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Como eliminar kernels antiguos
Introducción
Algunas distribuciones suelen hacer una instalación por defecto con la particion /boot o incluso a nosotros nos guste hacerlo asi. Pero se el tamaño suele ser exiguo y con el paso del tiempo los kernels han ido cogiendo tamaño y nos podemos quedar con el espacio justo o incluso hacer un update que del kernel que falle por no poder grabarse el archivo de arranque.
Mejor dejarlo en lo justo.
Centos
Centos 7.X
Listado de kernels instalados
[root@fail401 ~]# rpm -q kernel
kernel-3.10.0-1160.11.1.el7.x86_64
kernel-3.10.0-1160.15.2.el7.x86_64
kernel-3.10.0-1160.21.1.el7.x86_64
kernel-3.10.0-1160.24.1.el7.x86_64
kernel-3.10.0-1160.25.1.el7.x86_64
Kernel en ejecución
[root@fail401 ~]# uname -a
Linux fail401.xxxxx.com 3.10.0-1160.15.2.el7.x86_64 #1 SMP Wed Feb 3 15:06:38 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Método con el comando package-cleanup
Este comnado esta dentro dle paquete yum-utils
[root@fail401 ~]# package-cleanup --oldkernels --count=2
Complementos cargados:fastestmirror
--> Ejecutando prueba de transacción
---> Paquete kernel.x86_64 0:3.10.0-1160.11.1.el7 debe ser eliminado
---> Paquete kernel.x86_64 0:3.10.0-1160.15.2.el7 debe ser eliminado
---> Paquete kernel.x86_64 0:3.10.0-1160.21.1.el7 debe ser eliminado
--> Resolución de dependencias finalizada
Dependencias resueltas
=============================================================================================
Package Arquitectura Versión Repositorio Tamaño
=============================================================================================
Eliminando:
kernel x86_64 3.10.0-1160.11.1.el7 @updates 64 M
kernel x86_64 3.10.0-1160.15.2.el7 @updates 64 M
kernel x86_64 3.10.0-1160.21.1.el7 @updates 64 M
Resumen de la transacción
=============================================================================================
Eliminar 3 Paquetes
Tamaño instalado: 193 M
Está de acuerdo [s/N]:s
Downloading packages:
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Eliminando : kernel.x86_64 1/3
Eliminando : kernel.x86_64 2/3
Eliminando : kernel.x86_64 3/3
Comprobando : kernel-3.10.0-1160.15.2.el7.x86_64 1/3
Comprobando : kernel-3.10.0-1160.11.1.el7.x86_64 2/3
Comprobando : kernel-3.10.0-1160.21.1.el7.x86_64 3/3
Eliminado(s):
kernel.x86_64 0:3.10.0-1160.11.1.el7 kernel.x86_64 0:3.10.0-1160.15.2.el7
kernel.x86_64 0:3.10.0-1160.21.1.el7
¡Listo!
Versión manual
Tendremos que usar el comando rpm -e
[root@fail401 ~]# rpm -e kernel-3.10.0-1160.11.1.el7.x86_64 kernel-3.1X.X0-XXXXX.XX.X.el7.x86_64 ...
Ubuntu
¿Cómo concoer la lista de kernels de linux instalados?
sudo dpkg --list | egrep -i --color 'linux-image|linux-headers'
Ubuntu Focal 20.04
sudo apt --purge autoremove
sudo apt-get --purge autoremove
Agrdecimientos y enlaces
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Seguridad, SSl, etc.
Todos sobre seguridad, certificados, comprobación de ciphers
Verificar versiones y ciphers soportados de TLS, SSL
Introducción
Una de los mayores problemas al que se enfrenta el soporte es lidiar con los clientes y los problemas derivados del uso de sistemas (windows, MacOSX, Ios, Android, ...) obsoletos.
Verificar TLS soportado por un protocolo
h=nombre_del_host
p=port
## Tls 1.2
openssl s_client -connect $h:$p -tls1_2
### Tls 1.1
openssl s_client -connect $h:$p -tls1_1
### Tls 1
openssl s_client -connect $h:$p -tls1
El retorno debe tener una linea como esta
Verification: OK
Enumerar los ciphers ssl
h=nombre_del_host
p=port
nmap --script ssl-enum-ciphers -p $p $h
Starting Nmap 7.80 ( https://nmap.org ) at 2021-05-15 17:43 CEST
Nmap scan report for kvm468.ceinor.com (5.135.93.99)
Host is up (0.056s latency).
PORT STATE SERVICE
465/tcp open smtps
| ssl-enum-ciphers:
| TLSv1.2:
| ciphers:
| TLS_DHE_RSA_WITH_AES_128_GCM_SHA256 (dh 2048) - A
| TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 (dh 2048) - A
| TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (secp256r1) - A
| TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (secp256r1) - A
| compressors:
| NULL
| cipher preference: client
|_ least strength: A
Nmap done: 1 IP address (1 host up) scanned in 2.81 seconds
Links y agradecimientos
- Command prompt to check TLS version requiere by a host
- Checking ssl tls Version Support of a Remnote Host from Command line
CSF error: *WARING* URLGET set to use LWP but perl module is not installed, fallback to using CURL/WGET
Introducción
Casi siempre que se instala CSF Firewall en una distribución linux tenemos el mismo problema relativo a la ausencia de las librerías de perl LWP requeridas por CSF o mejor dicho preferidas ya que el propio CSF nos ofrece 3 posibilidades de configuración para la descarga de listas u otros elementos desde sitios remotos vía HTTPS.
- HTTP::Tiny
- LWP::UserAgent
- CURL/WGET (set location at the bottom of csf.conf)
LWP::UserAgent
Es la opción deseada y configurada por CSF, y esta configuración al no encontrar disponible el binario correspondiente, te lanza la advertencia cada vez que ejecutes un comando de csf.
*WARNING* URLGET set to use LWP but perl module is not installed, fallback to using CURL/WGET
Realmente en su propio fichero de configuración se encuentra el cómo, pero si has llegado hasta aquí, es que no lo leiste. (Es lo normal. No solemos leer los LEAME.txt vamos a leer los cientos de comentarios de algunos ficheros de configuración)
Distribuciones basada en RPM (Centos, AlmaLinux, CloudLinux,..)
yum install perl-libwww-perl.noarch perl-LWP-Protocol-https.noarch
Distribuciones basadas en APT (Debian, Ubuntu,...)
apt-get install libwww-perl liblwp-protocol-https-perl libgd-graph-perl
Via cpan
# perl -MCPAN -eshell
cpan> install LWP LWP::Protocol::https
Documentación original CSF (ConfigServer Firewall)
# The following option can be used to select the method csf will use to
# retrieve URL data and files
#
# This can be set to use:
#
# 1. Perl module HTTP::Tiny
# 2. Perl module LWP::UserAgent
# 3. CURL/WGET (set location at the bottom of csf.conf if installed)
#
# HTTP::Tiny is much faster than LWP::UserAgent and is included in the csf
# distribution. LWP::UserAgent may have to be installed manually, but it can
# better support https:// URL's which also needs the LWP::Protocol::https perl
# module
#
# CURL/WGET uses the system binaries if installed but does not always provide
# good feedback when it fails. The script will first look for CURL, if that
# does not exist at the configured location it will then look for WGET
#
# Additionally, 1 or 2 are used and the retrieval fails, then if either CURL or
# WGET are available, an additional attempt will be using CURL/WGET. This is
# useful if the perl distribution has outdated modules that do not support
# modern SSL/TLS implementations
#
# To install the LWP perl modules required:
#
# On rpm based systems:
#
# yum install perl-libwww-perl.noarch perl-LWP-Protocol-https.noarch
#
# On APT based systems:
#
# apt-get install libwww-perl liblwp-protocol-https-perl
#
# Via cpan:
#
# perl -MCPAN -eshell
# cpan> install LWP LWP::Protocol::https
#
# We recommend setting this set to "2" or "3" as upgrades to csf will be
# performed over SSL as well as other URLs used when retrieving external data
#
# "1" = HTTP::Tiny
# "2" = LWP::UserAgent
# "3" = CURL/WGET (set location at the bottom of csf.conf)
URLGET = "2"
# If you need csf/lfd to use a proxy, then you can set this option to the URL
# of the proxy. The proxy provided will be used for both HTTP and HTTPS
# connections
URLPROXY = ""
Aviso Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Limitar en el tiempo (expirar en una fecha) una llave openSSH en el authorized_keys
Introducción
Un serio handicap en los modelos de administración de sistemas basados en el ser humano, es que un despiste puede ser fatal para nuestra seguridad.
Cuando necesitamos añadir una llave SSH a un servidor para el acceso del propietario de dicha llave, y necesitamos que sea temporal, suele ocurrir, que al final, la llave termina por olvidarse.
Por mi trabajo, muchas veces accedo a servidor en los que tengo que realizar trabajos de auditoría o de tunning, y me encuentro llaves autorizadas desde el principio de los tiempos.
Añadir un limite de tiempo a una llave OpenSSH autorizada
Al igual que podemos limitar los comandos que el propietario de dicha llave SSH pueda hacer en nuestro sistema, también podemos limitar la validez de la llave en el tiempo.
Si nuestro servidor esta ejecutando una version OpenSSH 7.7 o superior, podremos hacerlo añadiendo expiry-time a la entrada de la llave a la que queremos limitar en el tiempo el acceso con el formato expiry-time="YYYYMMDD" ssh-rsa AAAAB3Nz...w== Algun comentario
expiry-time="20210621" ssh-rsa AAAAB3NzaC1yc2.. ...MXhBut9HKkWI9/ root@prox03
También puedes especificar un tiempo más concreto, usando YYYYMMDDhhmm (la versión YYYYMMDD entiende como si fuera la media noche, 2020-06-21 00:00:00
Enlaces
Adding expiration date to SSH key
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Comprobar una conexión SMTP autentificada en el shell con SSL o TLS
Introducción
Muchas veces el soporte técnico o nosotros, tenemos que comprobar si los datos que tenemos y si el servidor SMTP remoto, están operando correctamente. No es necesario hacer como hacen algunos un cambalache creando una cuenta en el programa de correo electrónico, sino que como casi siempre podemos acudir a nuestra shell para realizar las pruebas pertinentes.
Comprobar la autenticación SMTP y la conexión SSL usando la línea de comandos o shell.
Autenticación SMTP
La autentificación (autenticación) es el mecanismo por el cual un usuario se identifica a sí mismo en un servicio de un servidor. En este caso el servicio es el correo electrónico saliente o SMTP y es necesario para que podamos enviar correo electrónico.
Preparación, prueba y verificación
Para hacer la prueba es necesario tener instalado el paquete openssl de nuestro ordenador.
Crear la cadena de autenticación para una login basado en PLAIN
Generalmente los servidores de correo electrónico, usan como medio de autenticación uno denominado **PLAIN**, que consiste en pasar un texto plano (ASCII) que contiene el par **usuario + contraseña**
Antes de realizar la prueba debemos obtener la cadena de caracteres ASCII que contiene el par usuario_smtp + contraseña.
Usando Bash
En el momento de escribir esto, el tip que tenía en mi entrada original Cómo comprobar la autenticación SMTP SMTP Auth y la conexión con StartTLS en el shell me da error. La verdad es que he comprobado si había un error en mi escritura, y revisado con otros colegas. Así que he optado por no hacer el comando en una línea sino dividirlo en dos que si me funciona
$ echo -ne usuario@servidor.smtp.com | base64
emFiYml4QQDlbnRyYWwuY2FzdHJpcy5jb20=
$ echo -ne 4Mmr8Hop3FsmQvKtb8Ei | base64
NE1tcjVUb3BhRnNtUXZLdGI4RWk=
Ahora conectamos vía openssl
h y p son variables de entorno para poder trabajar más fácilmente
El puerto deberá ser el apropiado a la conexión, en este caso startssl
$ h=servidor.smtp.com
$ p=455
$ openssl s_client -connect $h:$p -starttls smtp
CONNECTED(00000003)
depth=2 C = US, O = Internet Security Research Group, CN = ISRG Root X1
verify return:1
depth=1 C = US, O = Let's Encrypt, CN = R3
verify return:1
depth=0 CN = servidor.smtp.com
verify return:1
---
Certificate chain
0 s:CN = servidor.smtp.com
…
Extended master secret: no
Max Early Data: 0
---
read R BLOCK
Esto ya nos indica que el servidor está activo, escuchando en el puerto solicitado, y admitiendo la conexión vía startssl
Ahora podemos usar EHLO therepara obtener los comandos disponibles
EHLO there
250-servidor.smtp.com
250-PIPELINING
250-SIZE 10240000
250-VRFY
250-ETRN
250-AUTH PLAIN LOGIN
250-ENHANCEDSTATUSCODES
250-8BITMIME
250-DSN
250-SMTPUTF8
250 CHUNKING
O pasar directamente a la autenticación
AUTH LOGIN
334 VXNlcm5hbWU6
emFiYml4QQDlbnRyYWwuY2FzdHJpcy5jb20=
334 UGFzc3dvcmQ6
NE1tcjVUb3BhRnNtUXZLdGI4RWk=
235 2.7.0 Authentication successful
Usando Perl
Si el usuario contiene la @ esta deberá escaparse con la barra invertida (\) de otra manera perl interpretará un arreglo (array) en lugar de una cadena (string)
Con Perl no tengo problemas para hacer lo mismo pero en lugar de usar AUTH LOGIN usar AUTH PLAIN usando la única cadena codifica del par usuario y contraseña
$ perl -MMIME::Base64 -e 'print encode_base64("\000usuario\@servidor.remoto.tld\000PaSsW0rD")'
AHphYmJpeEBjZW50cmFsLkTgqW3RyaXMuY29tADRNbXI1VG9wM0ZzbVF2S3RiOEVp
$ h=servidor.smtp.com
$ p=455
$ openssl s_client -connect $h:$p -starttls smtp
…
---
read R BLOCK
AUTH PLAIN AHphYmJpeEBjZW50cmFsLkTgqW3RyaXMuY29tADRNbXI1VG9wM0ZzbVF2S3RiOEVp
235 2.7.0 Authentication successful
Enlaces relacionados
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
CSF Firewall: añadir IPs al deny de forma definitiva.
Firewall y bloqueo definitivo para indeseables
A veces, trabajando ves que hay algunas IP que pertenecen a alguien, o incluso a un grupo de IP del mismo proveedor, que no para de aparecer en tus logs.
Además, si manda un correo al abuse@ de l proveedor de servicios, se hace el loco y no te contesta.
Pues que mejor que banear la IP de forma definitiva.
CSF Firewall bloqueo permanente
Esta ahí, en los comentarios del /etc/csf/csf.deny, pero es una de los mas desconocidos del CSF.
# Note: If you add the text "do not delete" to the comments of an entry then
# DENY_IP_LIMIT will ignore those entries and not remove them
Maravilloso verdad?
Ya sólo queda banearle desde el shell.
❯ csf -d 179.43.128.0/18 "do not delete - Panama datacenter sin respuesta"
Adding 179.43.128.0/18 to csf.deny and iptables DROP...
csf: IPSET adding [179.43.128.0/18] to set [chain_DENY]
❯ cat /etc/csf/csf.deny | grep 179.43.128
179.43.128.0/18 # do not delete - Panama datacenter sin respuesta - Sat Aug 17 17:47:12 2024
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Certificados Letsencrypt sin servidor web o sin resolver en el servidor web
Como obtener el certificado Letsencrypt para un dominio que no resuelve aun en una migración o nuevo servidor
Algunas veces es necesario hacer pruebas antes de levantar una migración en un nuevo servidor en producción.
Para ello, deberemos de forma manual, obtener un nuevo certificado basándonos en el desafio llamado challenge en el que solicitaremos el certificado porque tenemos capacidad de administración de la zona DNS. También se conoce como acme-dns-certbot
Requisitos
En este doc presuponemos que:
- Tienes cierto nivel de usuario Linux.
- Que tienes instalado certbot con snap. Si no, acude a las Instrucciones de Cerbot
- Que tienes instalado Python 3, lo cual es ya lo mas común en una instalación de Linux.
Instalar acme-cerbot
Una vez instalado necesitamos descargar el script de phyton que nos permitirá trabajar con este tipo de desafío, o validación mediante DNS.
Antes descargar nada, es buena práctica revisar el repositorio desde el que vamos a descargar el script. Antiguamente, no había forma salvo que conocieras un poco el programa y los sistemas implicados. Hoy día puedes usar si no alcanzas a esto, una chat de IA para que te verifique el scripts y te lo explique, como si fueras un novato en sistemas Linux y Python.
wget https://github.com/joohoi/acme-dns-certbot-joohoi/raw/master/acme-dns-auth.py
Lo hacemos ejecutable
chmod +x acme-dns-auth.py
Lo editamos para decirle que use Python 3
nano acme-dns-auth.py
#!/usr/bin/env python3
...
Una vez que hallamos realizado el cambio, movemos el fichero
sudo mv acme-dns-auth.py /etc/letsencrypt/
Configurar y usar acem-dns-cerbot
La cuestión es hora simple
sudo certbot certonly --manual --manual-auth-hook /etc/letsencrypt/acme-dns-auth.py --preferred-challenges dns --debug-challenges -d \*.tu-dominio -d tu-dominio
Eso es una idea, basándonos en que tienes un * en tu zona dns. Pero puedes dejarlo en la simpleza del dominio normal, el que contiene www y otros como mail, etc. Pero el consejo es que todos resuelvan a la ip
Ejemplo ficticio que surge de tener todo lo que te pida respecto de la zona DNS del dominio solicitado.
Antes de darle a continuar Press Enter to Continue es evidente que ya has creado el registro en la zona del dominio, tal y como te solicitan, o de lo contrario fallará la generación del certificado Let's Encrypt.
certbot certonly --manual --manual-auth-hook /etc/letsencrypt/acme-dns-auth.py --preferred-challenges dns --debug-challenges -d nodo1.midominio.tld
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Requesting a certificate for nodo1.midominio.tld
Hook '--manual-auth-hook' for nodo1.midominio.tld ran with output:
Please add the following CNAME record to your main DNS zone:
_acme-challenge.nodo1.midominio.tld CNAME cc94069f-6419-4c31-b079-d4408ec2bac6.auth.acme-dns.io.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Challenges loaded. Press continue to submit to CA.
Pass "-v" for more info about challenges.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Press Enter to Continue
Successfully received certificate.
Certificate is saved at: /etc/letsencrypt/live/nodo1.midominio.tld/fullchain.pem
Key is saved at: /etc/letsencrypt/live/nodo1.midominio.tld/privkey.pem
This certificate expires on 2025-08-11.
These files will be updated when the certificate renews.
Certbot has set up a scheduled task to automatically renew this certificate in the background.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
If you like Certbot, please consider supporting our work by:
* Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate
* Donating to EFF: https://eff.org/donate-le
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Con esto ya puedes configurar el sitio de manera temporal, hasta que resuelva en la maquina. Después lo suyo seria revocarlo y comenzar un proceso normal, basado en web.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Cambio de hostname permanentemente
Introducción
Algunas veces nos equivocamos, no teníamos el hostname definitivo o bien hemos instalado un VPS desde una plantilla, y necesitamos cambiar de forma permanente el hostname.
El fichero habitual que controla el hostname habitualmente es /etc/hostname pero puedo y suele, haber más ficheros implicados
Conocer el hostname en el shell
Aquí tenemos el comando hostnamectl para ver los datos
# hostnamectl
Static hostname: template2004
Icon name: computer-vm
Chassis: vm
Machine ID: 1169e389ab834b238027f744b7cf1ae6
Boot ID: e47b8b52d7fe46bf9659f9758d475a73
Virtualization: kvm
Operating System: Ubuntu 20.04.2 LTS
Kernel: Linux 5.4.0-73-generic
Architecture: x86-64
Y también podemos ver el propio fichero
# cat /etc/hostname
template2004
Cambiar el hostname permanentemente en Ubuntu 20.04 LTS
Ejecutar hostname con opciones
sudo hostnamectl set-hostname newNameHere
Editar el fichero /etc/hosts reemplazando cualquier concurrencia del viejo nombre.
También podemos utilizar sed pero quizás sea mejor hacerlo manualmente con nuestro editor favorito.
sed -i -e ‘s/viejo_nombre/nuevo_nombre/g’ /etc/hosts
Cambiar el hostname sin reiniciar en Ubuntu 20.04 LTS
El procedimiento anterior es válido. Lo unico es que en el terminal seguiremos viendo el nombre antiguo en lugar del actual que podemos verificar con
# hostnamectl
Static hostname: kvm300
Icon name: computer-vm
Chassis: vm
Machine ID: 1169e389ab834b238027f744b7cf1ae6
Boot ID: e47b8b52d7fe46bf9659f9758d475a73
Virtualization: kvm
Operating System: Ubuntu 20.04.2 LTS
Kernel: Linux 5.4.0-73-generic
Architecture: x86-64
Para ver el cambio en el indicador del terminal, debemos salir de nuestra shell o hacer un reload de nuestro intérprete de comandos.
Otros ficheros
Si tenemos instalado Postfix u otros demonios que requieren el uso de su propia variable o línea con el nombre del host, puede ser interesante ejecutar el comando de abajo para ver si existe algún otro fichero que debemos corregir.
# find /etc/ -type f -exec grep -il 'template2004' {} \;
/etc/ssh/ssh_host_rsa_key.pub
/etc/ssh/ssh_host_dsa_key.pub
/etc/ssh/ssh_host_ecdsa_key.pub
/etc/ssh/ssh_host_ed25519_key.pub
/etc/postfix/main.cf
/etc/aliases.db
Algunos de ellos, requerirán un reinicio o la aplicación de algún comando para actualizarse.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Hardware
El trabajo con el hardware también es necesario y configurable.
Conocer el hardware en linea de comandos (shell)
Comandos para identificar hardware y configuraciones especificas
Hardware
Información procesador
# grep 'vendor_id' /proc/cpuinfo ; grep 'model name' /proc/cpuinfo ; grep 'cpu MHz' /proc/cpuinfo
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
vendor_id : GenuineIntel
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
model name : Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
cpu MHz : 848.767
cpu MHz : 950.482
cpu MHz : 800.024
cpu MHz : 869.512
cpu MHz : 823.590
cpu MHz : 800.024
cpu MHz : 799.822
cpu MHz : 851.184
cpu MHz : 802.642
cpu MHz : 1182.916
cpu MHz : 1121.081
cpu MHz : 802.441
Marca procesador
Si el procesdor es intel el comando de abajo devolvera algo
# grep -i vmx /proc/cpuinfo
Si el procesador es AMD el comnado de abjo devolverá algo
# grep -i svm /proc/cpuinfo
Discos duros
lsblk (info particiones)
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 3,7T 0 disk
├─sda1 8:1 0 511M 0 part /boot/efi
├─sda2 8:2 0 50G 0 part
│ └─md2 9:2 0 50G 0 raid1 /
├─sda3 8:3 0 511M 0 part [SWAP]
├─sda4 8:4 0 1000G 0 part
│ └─md4 9:4 0 1000G 0 raid1 /var
└─sda5 8:5 0 2,6T 0 part
└─md5 9:5 0 2,6T 0 raid1 /home
sdb 8:16 0 3,7T 0 disk
├─sdb1 8:17 0 511M 0 part
├─sdb2 8:18 0 50G 0 part
│ └─md2 9:2 0 50G 0 raid1 /
├─sdb3 8:19 0 511M 0 part [SWAP]
├─sdb4 8:20 0 1000G 0 part
│ └─md4 9:4 0 1000G 0 raid1 /var
└─sdb5 8:21 0 2,6T 0 part
└─md5 9:5 0 2,6T 0 raid1 /home
loop0 7:0 0 2,2G 0 loop /var/tmp
Discos duros (Atributos)
# blkid
/dev/md4: LABEL="/var" UUID="bfa920a1-48e4-4d4e-ad9a-1f5289ec630e" TYPE="ext4"
/dev/sdb4: UUID="0ceedb71-9478-ba95-a4d2-adc226fd5302" TYPE="linux_raid_member" PARTLABEL="logical" PARTUUID="9ba975e1-1b14-49d3-8971-b936e8d5e4e4"
/dev/sda4: UUID="0ceedb71-9478-ba95-a4d2-adc226fd5302" TYPE="linux_raid_member" PARTLABEL="logical" PARTUUID="66b5b2c5-7be1-49e5-a792-9f87e2f7b4f5"
/dev/sda1: LABEL="EFI_SYSPART" UUID="42B6-5CF2" TYPE="vfat" PARTLABEL="primary" PARTUUID="da4d4fc9-d837-41d9-a107-e742798f9335"
/dev/sda2: UUID="facf2df2-7b51-d62e-a4d2-adc226fd5302" TYPE="linux_raid_member" PARTLABEL="primary" PARTUUID="d9d59890-5495-4d5c-b1a1-9c7cb06ea760"
/dev/sda3: LABEL="swap-sda3" UUID="b3455011-b526-4882-9103-53aea1ba8861" TYPE="swap" PARTLABEL="primary" PARTUUID="b5bd8cbf-6bd4-484d-a66f-95e026322fe3"
/dev/sda5: UUID="8841cb2a-ce20-324b-a4d2-adc226fd5302" TYPE="linux_raid_member" PARTLABEL="logical" PARTUUID="0a0c4007-1aa6-4bbd-8c94-b059e5e47a0e"
/dev/sdb1: LABEL="EFI_SYSPART" UUID="42EC-11F4" TYPE="vfat" PARTLABEL="primary" PARTUUID="96828372-cc5c-4f44-bfc4-0758c394b1bb"
/dev/sdb2: UUID="facf2df2-7b51-d62e-a4d2-adc226fd5302" TYPE="linux_raid_member" PARTLABEL="primary" PARTUUID="ea54dfc3-e5c8-4436-be12-9515d1f1f0f1"
/dev/sdb3: LABEL="swap-sdb3" UUID="7bf2c3e0-e995-4dbf-9edf-de91db5cc4e0" TYPE="swap" PARTLABEL="primary" PARTUUID="0581737a-20c0-44b7-957c-6190b583f1af"
/dev/sdb5: UUID="8841cb2a-ce20-324b-a4d2-adc226fd5302" TYPE="linux_raid_member" PARTLABEL="logical" PARTUUID="c02afe0d-c242-4dd9-8ec7-77ecd90e510b"
/dev/md2: LABEL="/" UUID="424a9e66-51b2-4947-97b2-0d632d79a97f" TYPE="ext4"
/dev/md5: LABEL="/home" UUID="0de14a77-8d9e-4f25-9c1b-bec542d45f22" TYPE="ext4"
/dev/loop0: UUID="8fa0ffb8-aaa1-4321-9d4f-d55a9b021bcc" TYPE="ext3"
Estado solido o mecánico
Devuelve 0 por SSD y 1 por discos mencánicos
cat /sys/block/sda/queue/rotational
Discos NVMe
Necesitamos ewl paquete (Ubuntu) nmve-cli para comprobar discos de tipo NVMe
# nvme list
Node SN Model Namespace Usage Format FW Rev
---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------
/dev/nvme0n1 S439NE0N101969 SAMSUNG MZQLB1T9HAJR-00007 1 958.95 GB / 1.92 TB 512 B + 0 B EDA5202Q
/dev/nvme1n1 S439NE0N101968 SAMSUNG MZQLB1T9HAJR-00007 1 1.69 TB / 1.92 TB 512 B + 0 B EDA5202Q
Discos duros (hdparam)
El comando hdparm puede que no este instalado en tu distribución.
yum install hdparm -y
# hdparm -I /dev/sda
/dev/sda:
ATA device, with non-removable media
Model Number: HGST HUS726040ALA610
Serial Number: N8GNY2YY
Firmware Revision: A5GNT920
Transport: Serial, ATA8-AST, SATA 1.0a, SATA II Extensions, SATA Rev 2.5, SATA Rev 2.6, SATA Rev 3.0; Revision: ATA8-AST T13 Project D1697 Revision 0b
Standards:
Used: unknown (minor revision code 0x0029)
Supported: 9 8 7 6 5
Likely used: 9
Configuration:
Logical max current
cylinders 16383 16383
heads 16 16
sectors/track 63 63
--
CHS current addressable sectors: 16514064
LBA user addressable sectors: 268435455
LBA48 user addressable sectors: 7814037168
Logical Sector size: 512 bytes
Physical Sector size: 512 bytes
device size with M = 1024*1024: 3815447 MBytes
device size with M = 1000*1000: 4000787 MBytes (4000 GB)
cache/buffer size = unknown
Form Factor: 3.5 inch
Nominal Media Rotation Rate: 7200
Capabilities:
LBA, IORDY(can be disabled)
Queue depth: 32
Standby timer values: spec'd by Standard, no device specific minimum
R/W multiple sector transfer: Max = 16 Current = 16
Advanced power management level: 254
DMA: mdma0 mdma1 mdma2 udma0 udma1 udma2 udma3 udma4 udma5 *udma6
Cycle time: min=120ns recommended=120ns
PIO: pio0 pio1 pio2 pio3 pio4
Cycle time: no flow control=120ns IORDY flow control=120ns
Commands/features:
Enabled Supported:
* SMART feature set
Security Mode feature set
* Power Management feature set
* Write cache
* Look-ahead
* Host Protected Area feature set
* WRITE_BUFFER command
* READ_BUFFER command
* NOP cmd
* DOWNLOAD_MICROCODE
* Advanced Power Management feature set
Power-Up In Standby feature set
* SET_FEATURES required to spinup after power up
SET_MAX security extension
* 48-bit Address feature set
* Device Configuration Overlay feature set
* Mandatory FLUSH_CACHE
* FLUSH_CACHE_EXT
* SMART error logging
* SMART self-test
* Media Card Pass-Through
* General Purpose Logging feature set
* WRITE_{DMA|MULTIPLE}_FUA_EXT
* 64-bit World wide name
* URG for READ_STREAM[_DMA]_EXT
* URG for WRITE_STREAM[_DMA]_EXT
* WRITE_UNCORRECTABLE_EXT command
* {READ,WRITE}_DMA_EXT_GPL commands
* Segmented DOWNLOAD_MICROCODE
* unknown 119[6]
unknown 119[7]
* Gen1 signaling speed (1.5Gb/s)
* Gen2 signaling speed (3.0Gb/s)
* Gen3 signaling speed (6.0Gb/s)
* Native Command Queueing (NCQ)
* Host-initiated interface power management
* Phy event counters
* NCQ priority information
* unknown 76[15]
Non-Zero buffer offsets in DMA Setup FIS
* DMA Setup Auto-Activate optimization
Device-initiated interface power management
In-order data delivery
* Software settings preservation
unknown 78[7]
unknown 78[10]
unknown 78[11]
* SMART Command Transport (SCT) feature set
* SCT Write Same (AC2)
* SCT Error Recovery Control (AC3)
* SCT Features Control (AC4)
* SCT Data Tables (AC5)
* reserved 69[3]
* reserved 69[4]
* WRITE BUFFER DMA command
* READ BUFFER DMA command
Security:
Master password revision code = 65534
supported
not enabled
not locked
not frozen
not expired: security count
not supported: enhanced erase
Logical Unit WWN Device Identifier: 5000cca244c984a4
NAA : 5
IEEE OUI : 000cca
Unique ID : 244c984a4
Checksum: correct
lshw
lshw -class disk -class storage
*-sata
description: SATA controller
product: Cannon Lake PCH SATA AHCI Controller
vendor: Intel Corporation
physical id: 17
bus info: pci@0000:00:17.0
logical name: scsi0
logical name: scsi1
version: 10
width: 32 bits
clock: 66MHz
capabilities: sata msi pm ahci_1.0 bus_master cap_list emulated
configuration: driver=ahci latency=0
resources: irq:125 memory:91200000-91201fff memory:91203000-912030ff ioport:4050(size=8) ioport:4040(size=4) ioport:4020(size=32) memory:91202000-912027ff
*-disk:0
description: ATA Disk
product: HGST HUS726040AL
physical id: 0
bus info: scsi@0:0.0.0
logical name: /dev/sda
version: T920
serial: N8GNY2YY
size: 3726GiB (4TB)
capabilities: gpt-1.00 partitioned partitioned:gpt
configuration: ansiversion=5 guid=9aa4231a-644b-40c9-9105-0e980dbeeeaa logicalsectorsize=512 sectorsize=512
*-disk:1
description: ATA Disk
product: HGST HUS726040AL
physical id: 1
bus info: scsi@1:0.0.0
logical name: /dev/sdb
version: T920
serial: K4KRJ0KB
size: 3726GiB (4TB)
capabilities: gpt-1.00 partitioned partitioned:gpt
configuration: ansiversion=5 guid=2c1a29d1-8bb6-4d02-9990-b9f2fb7b3414 logicalsectorsize=512 sectorsize=512
# lshw -short -C disk
H/W path Device Class Description
====================================================
/0/100/17/0 /dev/sda disk 4TB HGST HUS726040AL
/0/100/17/1 /dev/sdb disk 4TB HGST HUS726040AL
smartctl
Importante para ver el estado de tus discos. Sobre todo cuando compras o alquilas hardware
smartctl -d ata -a -i /dev/sda
smartctl 7.0 2018-12-30 r4883 [x86_64-linux-3.10.0-962.3.2.lve1.5.49.el7.x86_64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: HGST Ultrastar 7K6000
Device Model: HGST HUS726040ALA610
Serial Number: N8GNY2YY
LU WWN Device Id: 5 000cca 244c984a4
Firmware Version: A5GNT920
User Capacity: 4.000.787.030.016 bytes [4,00 TB]
Sector Size: 512 bytes logical/physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2, ATA8-ACS T13/1699-D revision 4
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Sun May 16 17:57:14 2021 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 113) seconds.
Offline data collection
capabilities: (0x5b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 571) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 016 Pre-fail Always - 0
2 Throughput_Performance 0x0005 135 135 054 Pre-fail Offline - 112
3 Spin_Up_Time 0x0007 184 184 024 Pre-fail Always - 265 (Average 315)
4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 80
5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 0
7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always - 0
8 Seek_Time_Performance 0x0005 128 128 020 Pre-fail Offline - 18
9 Power_On_Hours 0x0012 097 097 000 Old_age Always - 27686
10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 75
192 Power-Off_Retract_Count 0x0032 080 080 000 Old_age Always - 24197
193 Load_Cycle_Count 0x0012 080 080 000 Old_age Always - 24197
194 Temperature_Celsius 0x0002 162 162 000 Old_age Always - 37 (Min/Max 19/52)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 26073 -
# 2 Short offline Completed without error 00% 26058 -
# 3 Short offline Completed without error 00% 26058 -
# 4 Short offline Completed without error 00% 16865 -
# 5 Short offline Completed without error 00% 16850 -
# 6 Short offline Completed without error 00% 16850 -
# 7 Short offline Completed without error 00% 15329 -
# 8 Short offline Completed without error 00% 15314 -
# 9 Short offline Completed without error 00% 15314 -
#10 Short offline Completed without error 00% 15288 -
#11 Short offline Completed without error 00% 15278 -
#12 Short offline Completed without error 00% 15264 -
#13 Short offline Completed without error 00% 15264 -
#14 Short offline Completed without error 00% 15249 -
#15 Short offline Completed without error 00% 15249 -
#16 Short offline Completed without error 00% 15099 -
#17 Short offline Completed without error 00% 29 -
#18 Short offline Completed without error 00% 23 -
#19 Short offline Completed without error 00% 23 -
#20 Short offline Completed without error 00% 2 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
Estado del RAID pro software
cat /proc/mdstat
Personalities : [raid1]
md5 : active raid1 sda5[0] sdb5[1]
2804960192 blocks [2/2] [UU]
bitmap: 12/21 pages [48KB], 65536KB chunk
md4 : active raid1 sdb4[1] sda4[0]
1048573888 blocks [2/2] [UU]
bitmap: 4/8 pages [16KB], 65536KB chunk
md2 : active raid1 sdb2[1] sda2[0]
52427712 blocks [2/2] [UU]
Hardware información general
Hardware información general resumida
# lshw -short
H/W path Device Class Description
====================================================
system To Be Filled By O.E.M. (To Be Filled By O.E.M.)
/0 bus E3C242D4U2-2T
/0/0 memory 64KiB BIOS
/0/9 memory 32GiB System Memory
/0/9/0 memory 16GiB DIMM DDR4 Synchronous 2666 MHz (0,4 ns)
/0/9/1 memory DIMM [empty]
/0/9/2 memory 16GiB DIMM DDR4 Synchronous 2666 MHz (0,4 ns)
/0/9/3 memory DIMM [empty]
/0/14 memory 384KiB L1 cache
/0/15 memory 1536KiB L2 cache
/0/16 memory 12MiB L3 cache
/0/17 processor Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz
/0/100 bridge 8th Gen Core Processor Host Bridge/DRAM Registers
/0/100/8 generic Xeon E3-1200 v5/v6 / E3-1500 v5 / 6th/7th/8th Gen Core Processor Gaussian Mixture Model
/0/100/12 generic Cannon Lake PCH Thermal Controller
/0/100/14 bus Cannon Lake PCH USB 3.1 xHCI Host Controller
/0/100/14/0 usb1 bus xHCI Host Controller
/0/100/14/1 usb2 bus xHCI Host Controller
/0/100/14.2 memory RAM memory
/0/100/15 bus Cannon Lake PCH Serial IO I2C Controller #0
/0/100/15.1 bus Cannon Lake PCH Serial IO I2C Controller #1
/0/100/16 communication Cannon Lake PCH HECI Controller
/0/100/16.4 communication Cannon Lake PCH HECI Controller #2
/0/100/17 scsi0 storage Cannon Lake PCH SATA AHCI Controller
/0/100/17/0 /dev/sda disk 4TB HGST HUS726040AL
/0/100/17/0/1 /dev/sda1 volume 510MiB Windows FAT volume
/0/100/17/0/2 /dev/sda2 volume 49GiB EXT4 volume
/0/100/17/0/3 /dev/sda3 volume 510MiB Linux swap volume
/0/100/17/0/4 /dev/sda4 volume 999GiB EXT4 volume
/0/100/17/0/5 /dev/sda5 volume 2675GiB EXT4 volume
/0/100/17/1 /dev/sdb disk 4TB HGST HUS726040AL
/0/100/17/1/1 /dev/sdb1 volume 510MiB Windows FAT volume
/0/100/17/1/2 /dev/sdb2 volume 49GiB EXT4 volume
/0/100/17/1/3 /dev/sdb3 volume 510MiB Linux swap volume
/0/100/17/1/4 /dev/sdb4 volume 999GiB EXT4 volume
/0/100/17/1/5 /dev/sdb5 volume 2675GiB EXT4 volume
/0/100/1b bridge Cannon Lake PCH PCI Express Root Port #21
/0/100/1b/0 eth0 network Ethernet Controller 10G X550T
/0/100/1b/0.1 eth1 network Ethernet Controller 10G X550T
/0/100/1c bridge Cannon Lake PCH PCI Express Root Port #1
/0/100/1c/0 bridge AST1150 PCI-to-PCI Bridge
/0/100/1c/0/0 display ASPEED Graphics Family
/0/100/1d bridge Cannon Lake PCH PCI Express Root Port #9
/0/100/1e communication Cannon Lake PCH Serial IO UART Host Controller
/0/100/1f bridge Intel Corporation
/0/100/1f.4 bus Cannon Lake PCH SMBus Controller
/0/100/1f.5 bus Cannon Lake PCH SPI Controller
/0/1 system PnP device PNP0c02
/0/2 system PnP device PNP0c02
/0/3 communication PnP device PNP0501
/0/4 communication PnP device PNP0501
/0/5 system PnP device PNP0c02
/0/6 generic PnP device INT3f0d
/0/7 system PnP device PNP0c02
/0/8 system PnP device PNP0c02
/0/a system PnP device PNP0c02
/0/b system PnP device PNP0c02
Hardware información general detallada
# lshw | less
MegaCli
MegaCli es una herramienta especifica de la familia de controladoras LSI MegaRaid
Auqne muchos manuales idtentifican los caomando unas veces en minusculas, otros con alternacia de mayúsculas y minúsculas, lo qmejor es crear un alias, apuntado al que corresponda. Si te falla alguna información en al gun tip, que ves por internet esa es la razón.
En mi caso uso MegaCli ya que hice en su día ln -s /usr/sbin/megacli MegaCli
Conocer el estado de la controladora
root@pro02:~# MegaCli -EncInfo -aALL
Number of enclosures on adapter 0 -- 1
Enclosure 0:
Device ID : 252
Number of Slots : 8
Number of Power Supplies : 0
Number of Fans : 0
Number of Temperature Sensors : 0
Number of Alarms : 0
Number of SIM Modules : 1
Number of Physical Drives : 8
Status : Normal
Position : 1
Connector Name : Unavailable
Enclosure type : SGPIO
FRU Part Number : N/A
Enclosure Serial Number : N/A
ESM Serial Number : N/A
Enclosure Zoning Mode : N/A
Partner Device Id : Unavailable
Inquiry data :
Vendor Identification : AVAGO
Product Identification : SGPIO
Product Revision Level : N/A
Vendor Specific :
Exit Code: 0x00
Sistema
Arquitectura
lshw no tiene porque estar disponible en tu distribucion. Si es asi instalalo o busca alternativa.
# sudo lshw -C CPU | grep width
width: 64 bits
Enlaces y agradecimientos
- How to find out Hard Disk Specks /Deatis on Linux
- Using NVMe Command Line Tools to Check NVMe Flash Health
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Uso de UUID para montar particiones linux
Introducción
El UUID (Identificador único universal) es un identificador estandarizado usado en el desarrollo del software por la OSF (Open Software Foundation) y es parte del Entorno de Distribución de Software (DCE).
El objetivo del uso del UUID es permitir que los sistemas distribuidos identifiquen de manera única y sin una coordinación central los elementos de hardware y software. Cualquier administrador puede crear un UUID y usarlo para identificar algo con confianza razonable que nadie involuntariamente usará el mismo identificador en otros elemento o dispositivo.
Beneficios del uso de UUID
Su uso es especialmente útil, en un entorno personal, para asignar por ejemplo, el montaje de discos externos o internos, sin temor a que por razones del hardware, la asignación numérica habitual, haga fracasar el montaje de discos, cuando añadimos o eliminamos algún dispositivo nuevo.
Dispositivos, SAN, iSCSI, DAS, volúmenes externos, son los mejores candidatos para el uso de UUID en el fichero fstab.
Comando blkid el sustituto de vol_id
Muchos de los tutoriales se han quedado obsoletos, ya que hacen uso del comando vol_id sustituido por blkid
sudo vol_id --uuid /dev/sdb2
sudo: vol_id: orden no encontrada
En su lugar podemos usar blkid
❯ sudo blkid
/dev/nvme0n1p1: UUID="9047-9E81" TYPE="vfat" PARTUUID="cb856993-8dff-48f8-8646-0a4f333d2e7a"
/dev/nvme0n1p2: UUID="dcV8h8-Ie6y-9yey-5RUE-YfPP-E0ra-fZAXSy" TYPE="LVM2_member" PARTUUID="d7a787ab-2143-46c5-b2aa-e46941a9210d"
/dev/sda1: UUID="8aa6c0d2-c18e-4606-b1da-f5f1f7617f00" TYPE="xfs" PARTLABEL="backup3t" PARTUUID="f6b13129-366f-4d3c-8b79-05514ebcaff5"
/dev/sdb1: LABEL="ssd" UUID="297ddd6c-f224-4385-8f89-e44f4a6912f3" TYPE="ext4" PARTUUID="57b4c3da-5bde-4a2f-83d5-fa43c13b63cb"
/dev/mapper/kubuntu--vg-root: UUID="3c55b16d-1ad7-4ced-a552-874cc97ba0d3" TYPE="ext4"
/dev/mapper/kubuntu--vg-swap_1: UUID="f6655751-5635-4acb-9ba6-5d3530aace9d" TYPE="swap
❯ sudo blkid /dev/nvme0n1p1
/dev/nvme0n1p1: UUID="9047-9E81" TYPE="vfat" PARTUUID="cb856993-8dff-48f8-8646-0a4f333d2e7a"
❯ sudo blkid /dev/sda1
/dev/sda1: UUID="8aa6c0d2-c18e-4606-b1da-f5f1f7617f00" TYPE="xfs" PARTLABEL="backup3t" PARTUUID="f6b13129-366f-4d3c-8b79-05514ebcaff5"
Uso de UUID en el fichero /etc/fstab
Sintaxis
UUID={YOUR-UID} {/path/to/mount/point} {file-system-type} defaults,errors=remount-ro 0 1
Ejemplo para discos XFS
Editamos el fichero /etc/fstab para que contenga el punto de montaje
❯ sudo cat /etc/fstab | grep 8aa6
UUID=8aa6c0d2-c18e-4606-b1da-f5f1f7617f00 /backups xfs rw,noquota,nofail 0 1
Comprobar
❯ sudo mount -a
❯ df -h |grep backups
/dev/sda1 2,8T 1,2T 1,6T 43% /backups
Yo uso habitualmente XFS ya que estoy más especializado en sistemas de backup y correo, donde el número de ficheros es mucho más elevado que otros, por lo que el uso de inodos es importante. XFS me permite un mayor control y calidad que ext4 para este tipo de sistemas. Por eso necesito usar
noquota,nofailen lugar de la sintaxis común de ext4
Enlaces
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Instalación GPT con el instalador Centos 7 en discos < 2 TiB
Introducción
Uno de los problemas comunes en la generación de templates e incluso en algunas instalaciones, es el uso del obsoleto MBR.
MBR es anticuado, y además presenta problemas en el caso de que en entornos virtuales, tengamos que hacer una ampliación de disco mayor de 2TiB. La eficiacia de GPT es muy superior y recomendable.
Además si algun día nuestro disco quiere crecer por encima de los 2 TiB, ya no lo podrá hacer con MBR.
Anaconda que es el sistema de Centos 7 para particionar el disco, hará lo siguiente:
- Si el disco ya está formateado, respetará el esquema de partición.
- Si el disco tiene más de 2 32 sectores (2 Tib) usará GPT
- Si el disco es de menor tamaño usará MBR.
Instalar Centos 7 con tabla de particiones GPT
Aviso
Si bien existen algunos artículos sobre cómo convertir una partición con esquema MBR a GPT, esto no es recomendable, ya que GPT sólo es válido en sistemas compatibles con UEFI, y por tanto requiere una partición EFI /boot/efi de al menos 50 MiB (recomendado 200 MiB) y aunque podemos hacerlo mejor comenzar bien desde el principio.
Discos menores de 2TiB
Al mostrarse el instalador, debemos pulsar Tab para poder añadir a la linea de arranque inst.gpt lo cual de forma silenciosa, hará que anaconda realice la instalación usando el esquema de particiones GPT.
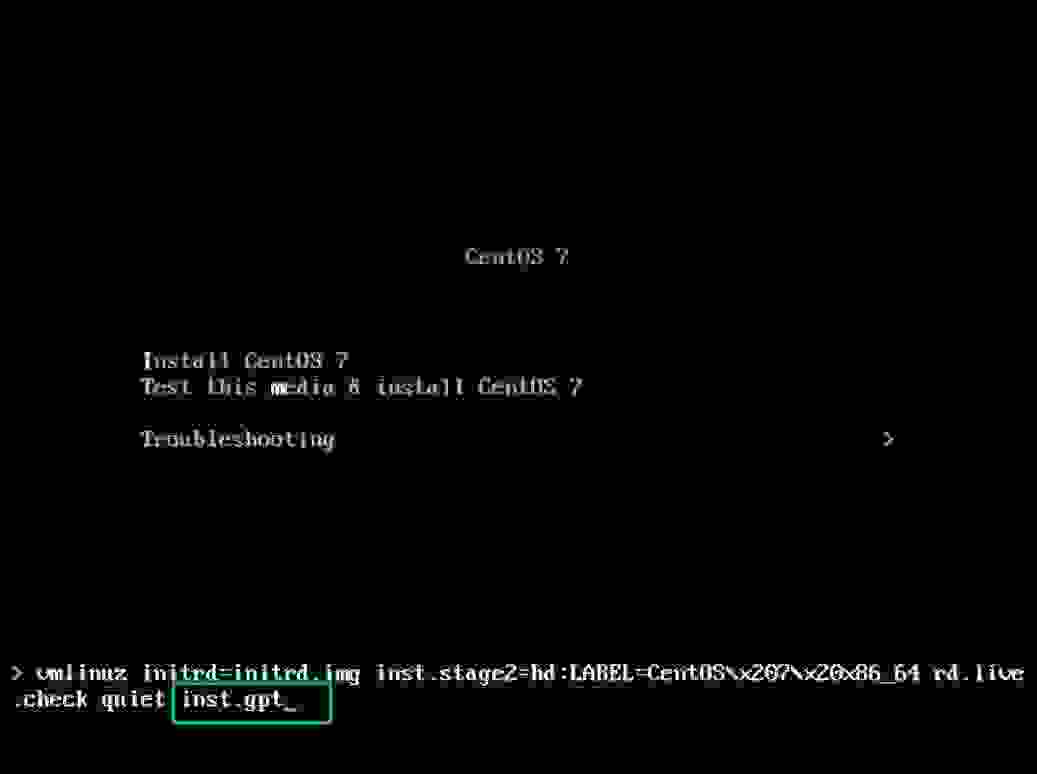
Una vez finalizada la instalación tu disco tendrá un esquema de particiones GPT, que podrás ampliar sin problema mas allá de los 2 TiB
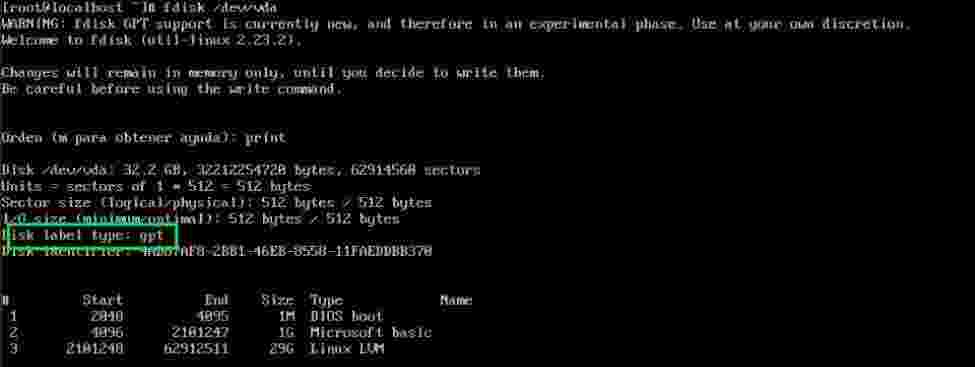
Enlaces
- CentOs - Installation Destination
- [Anaconda](https://es.wikipedia.org/wiki/Anaconda_(instalador)
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Parted mejor que fdisk
Introducción
Además de que fdisk no puede particionar creando particiones mayores de 2TB, es mucho mejor amigo del sysadmin parted.
En este artículo dejo escrito el cómo hacerlo en el caso de discos que uso en montajes de Proxmox con OVH.
Parted : Creando particiones
Label si esta no existe
Si no existe etiqueta del formato de disco es necesaria así que la creamos
# parted -s /dev/nvme1n1 mklabel gpt
Hacer la partición disponible al 100%
Cómo uso los discos para LVM es necesario crear una partición al 100% Recomendación LVM Howto
# parted -s /dev/nvme1n1 mkpart primary 0% 100%
# parted /dev/nvme1n1
GNU Parted 3.4
Using /dev/nvme1n1
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) print
Model: SAMSUNG MZVL2512HCJQ-00B07 (nvme)
Disk /dev/nvme1n1: 512GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 512GB 512GB primary
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Directadmin
Un panel como otro cualquiera.
Actualizar la licencia DirectAdmin en el shell
Introducción
Tratamos de entrar en nuestro servidor con DirectAdmin como administradores y nos encontramos con el problema de que no funciona y la licencia esta expirada, o la habiamos renovado o comprado, pero no esta actualizada. No hay problema, acudamos al shell.
Actualziación de la licencia DirectAdmin en shell
Automático
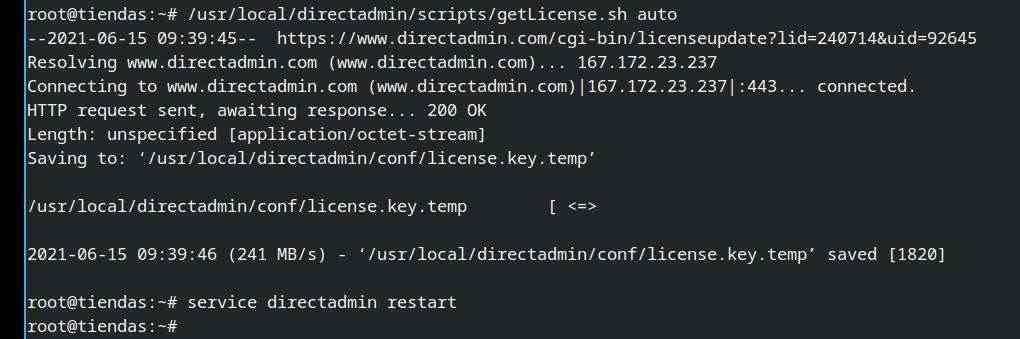
Accedemos a nuestro servidor via ssh y ejecutamos los dos comandos:
- Uno para descargar la licencia
- Otro para reiniciar DirectAdmin
~# /usr/local/directadmin/scripts/getLicense.sh auto
--2021-06-15 09:39:45-- https://www.directadmin.com/cgi-bin/licenseupdate?lid=240714&uid=92645
Resolving www.directadmin.com (www.directadmin.com)... 167.172.23.237
Connecting to www.directadmin.com (www.directadmin.com)|167.172.23.237|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [application/octet-stream]
Saving to: ‘/usr/local/directadmin/conf/license.key.temp’
/usr/local/directadmin/conf/license.key.temp [ <=> ] 1.78K --.-KB/s in 0s
2021-06-15 09:39:46 (241 MB/s) - ‘/usr/local/directadmin/conf/license.key.temp’ saved [1820]
root@tiendas:~# service directadmin restart
Enlace esxterno oficial con otras alternativas
Updating your DirectAdmin License manually
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
MySQL - MariaDb
Un mundo difícil, en el que las diferencias entre los motores SQL del tipo MySQL, comienzan a ser muy problemáticas. Incluso entre las versiones del mismo motor.
ERROR 1118 (42000) at line XXXXX: Row size too large (> 8126)
Introducción
Los upgrades de versión han sido un problema desde MySQL 5 y en MariaDB desde la 10. Muchas veces se quedan flecos que producen errores, que en caso de recuperación de desastres pueden ser un serio handicap.
Error
[root@servidor02b mysql]# bunzip2 < dbdump.db.bz2 | mysql
ERROR 1118 (42000) at line 13300: Row size too large (> 8126). Changing some columns to TEXT or BLOB may help. In current row format, BLOB prefix of 0 bytes is stored inline.
[root@servidor02b mysql]# bunzip2 < dbdump.db.bz2 | mysql
Solución
Editamos el fichero de configuración de mysql (generalmente /etc/my.cnf o dentro de /etc/mysql/) para añadir en la sección [mysqld] el siguiente contenido (puedes adaptarlo a tu sistema, necesidades o posibilidades)
[mysqld]
innodb_log_file_size=512M
innodb_strict_mode=0
Después realizamos un restart del servidor e intentamos de nuevo el restore.
Enlaces
- Troubleshooting Row Size Too Large Errors with InnoDB
- Row size too large (> 8126). Changing some columns to TEXT or BLOB may help. In current row format, BLOB prefix of 0 bytes is stored inline
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Errores con MariaDB 10.3 al restaurar o hacer backups arrastrando versiones antiguas
Introducción
Los síntomas son variados, pero afectan todos a la base de datos sys la cual existía con anterioridad a la versión 10.3 de MariaDB y que ya está en desuso.
mysqldump: Got error: 1356: "View 'sys.host_summary' references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them" when using LOCK TABLES
Base de datos sys
Esta base de datos, no se incluye desde la 10.3, pero ha sido incorporada en la versión 10.6.0 (Alpha) y 10.6.1 (Beta), bundle sys schema - MDEV-9077, y si no la usas (probablemente) es seguro eliminarla.
$ mysql
mysql > DROP DATABASE sys;
Si la necesitas, deberás intentar resolver los problemas descritos en los mensajes de error.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Como extraer de un backup de MySQL completo una base de datos y/o una tabla
Introducción
Lo habitual en sistemas es tener un backup de bases de datos, por database o esquema. Pero a veces, sólo tenemos un backup completo. Mucho menos habitual es tener backups por tablas, así que en esta entrada, te explicamos cómo obtener el backup de una base de datos obtenida de un backup completo de mysqldump, y/o como extraer una tabla de un backup completo o de un esquema de la base de datos.
Mysql --one-database
Una opción muy potente, que puede ser muy útil en ciertos escenarios (trabajo con logs binarios) pero que requiere un conocimiento profundo de MySQL. Así que mejor ir a lo práctico.
Filtrar el fichero mysqldump con sed
Para mi es la mejor opción para extraer una base de datos o una tabla de un fichero SQL de mysqldump.
$ sed -n '/^-- Current Database: `nombre_de_la_base_de_datos`/,/^-- Current Database: `/p' nombre_del_backup.sql > nombre_de_la_base_de_datos.sql
Tip sed. Pasar una variable a un comando sed
El mismo comando se puede pasar de forma más fácil, usando variables. En mi caso uso este tip, aunque existen otras fórmulas para pasar variables, en este caso muchas de ellas fallaran por las comillas simples invertidas.
$ bd=nombre_de_la_bd
$ mydump=nombre_del_fichero_dump_sql
$ sed -n '/^-- Current Database: `'"${bd}"'`/,/^-- Current Database: `/p' $mydump > ${bd}.sql
Extraer una tabla de un fichero mysqldump
¿Necesitas restaurar una sóla tabla? Sencillo. Cambiamos un poco la estructura de la consulta (trabajando sobre el fichero de una sola base de datos
$ tabla=nombre_de_la_tabla
$ sed -n '/^-- Table structure for table `'"${tabla}"'`/,/^-- Table structure for table /p' ${bd}.sql > ${tabla}.sql
Nota de actualización para MacOs 2024/11/23
Algunas veces a sed en macos le da por mostrar problemas derivados la codificación. (Eso de no ser POSIX al MacosX le mata a veces)
La solución (no lo intentes con las IA que a todas se les va la pinza...)
sed -i -n '/^-- Current Database: `'"${bd}"'`/,/^-- Current Database: `/p' $mydump > ${bd}.sql
sed: RE error: illegal byte sequence
Solución
LC_ALL=C sed -i -n '/^-- Current Database: `'"${bd}"'`/,/^-- Current Database: `/p' $mydump > ${bd}.sql
Renombrar el backup de la tabla extraída para usarlo en la misma base de datos
Atención porque si queremos usar ese backup para crear una copia clonada de la tabla con otro nombre hay que modificar el fichero, ya que de lo contrario volcaremos el contenido en la misma tabla, y si es un backup antiguo, el lío esta servido.
-- Table structure for table `nombre_de_la_tabla`
DROP TABLE IF EXISTS `nombre_de_la_tabla`;
CREATE TABLE `nombre_de_la_tabla` (
-- Dumping data for table `nombre_de_la_tabla`
LOCK TABLES `nombre_de_la_tabla` WRITE;
/*!40000 ALTER TABLE `nombre_de_la_tabla` DISABLE KEYS */;
Asi que debemos cambiarlo. Y una manía muy preocupante es la de usar editores de texto, sobre todo en windows, lo cual puede ser terrorífico, aparte de poco efectivo.
Usaremos sed otra vez.
# newtabla=nueva_tabla
# sed -i -e 's/'"${tabla}"'/'"${newtabla}"'/g' ${tabla}.sql
Enlaces
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Como crear un usuario Mysql/MariaDB con Grant Privileges
Introducción
La organización es muy adecuada en nuestro trabajo. Crear usuarios y bases de datos sin control alguno, y sin una nomenclatura es signo de desorganización, y el camino previo para las dificultades cuando necesitemos escalar nuestro proyecto. Además, a veces, no podemos dar permiso para todo (root) a todos. Eso sería un grave error en nuestra política de seguridad.
El siguiente artículo, ha sido creado con MariaDb 10.6 pero con algunas diferencias sutiles que podréis encontrar en la documentación de los respectivos motores y versiones.
Permite crear un usuario con privilegios suficientes para crear una base de datos y tener privilegios globales para es base de datos, siempre que cumpla, la nomenclatura de nombres basado en prefijo_
Crear una Database
Si no tienes una base de datos creada, tendrás que crearla.
Los comandos de este documento presuponen que tienes conocimientos básicos de MySQL.
# mysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 49
Server version: 10.6.3-MariaDB-1:10.6.3+maria~focal-log mariadb.org binary distribution
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> CREATE DATABASE mibasedatos_pre;
Query OK, 1 row affected (0.000 sec)
MariaDB [(none)]> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| mibasedatos_pre |
+--------------------+
6 rows in set (0.000 sec)
El comando accede como root porque lo tengo configurado a tal fin siendo root. Pude ser que en tu sistema tengas que usar `mysql -u root -p`
Crear un usuario nuevo de MariaDB
MariaDB [(none)]> CREATE USER 'mibasedatos_usr'@'localhost' IDENTIFIED BY 'UnACoNtRaSeñaAdECuADa';
Query OK, 0 rows affected (0.001 sec)
Comprobamos
MariaDB [(none)]> SELECT User FROM mysql.user;
+--------------+
| User |
+--------------+
| mariadb.sys |
| mysql |
| root |
| mibasedatos_pre |
+--------------+
4 rows in set (0.001 sec)
Otorgamos privilegios al user de MariaDB
GRANT CREATE USER, CREATE ON *.* TO 'mibasedatos_usr'@'localhost' IDENTIFIED BY 'CKWor4Jh9CC4UskUg';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON `mibasedatos\_%`.* TO 'mibasedatos_usr'@'localhost' WITH GRANT OPTION;
Query OK, 0 rows affected (0.001 sec)
Otorgamos privilegios al user en MySQL 8 +
CREATE USER, CREATE ON *.* TO 'mibasedatos_usr'@'localhost' IDENTIFIED BY 'CKWor4Jh9CC4UskUg';
GRANT ALL PRIVILEGES ON *.* TO 'myroot'@'localhost';
Comprobación
MariaDB [(none)]> USE mibasedatos_pre;
Database changed
MariaDB [mibasedatos_pre]> CREATE TABLE test (id INT);
Query OK, 0 rows affected (0.003 sec)
Esto permite al usuario **crear cualquier base de datos** pero solo **usar aquellas que comienzan por el prefijo** Si deseas algo más especifico en mi opinión, necesitas hacer un script que genere el usuario y los permisos sucesivos cuando cree una tabla, forzando al uso dle prefijo (estilo cpanel)
Enlaces
- How to Create MariaDB User and Grant Privileges
- MySQL granting privileges on wildcard database name to new user
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Restaurar mysqldump completo con problemas relacionados con VIEW y sus permisos
Mysqldump, restore, vistas y seguridad
Algunas veces, sobre todo cuando estamos trabajando con backups de otros servidores mysql, con problemas para restaurar un backup de una base de datos individual, que se hizo de forma completa.
Esta incluye las vistas, y por ende, los usuarios con permisos para las vistas, conocido en MySQL como SQL SECURITY DEFINER .
Si en nuestro sistema no existen esos usuarios, a los que hace referencia el fichero sql, obtendremos un fallo, en el volcado o restauración de la copia de seguridad, incluso si lo ejecutamos como root
Por ejemplo
ERROR 1356 (HY000) at line 1693: View 'database.view_condition_xx_table' references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them
Podemos intentar algunos tips, que hay por ahí, incluso hacer un restore forzado pero nos quedaríamos con la duda de si está todo bien.
Solución propuesta: desactivar al usuario afectado en su SQL SECURITY DEFINER
Primero para ver el tema y si este es el problema realmente (copiar y pegar artículos de internet no es buena idea si no se sabe lo que se hace) vamos a ver si los tiros van por ahí.
❯ cat my-database-dump.sql | grep -i DEFINER
/*!50013 DEFINER=`root`@`127.0.0.1` SQL SECURITY DEFINER */
/*!50013 DEFINER=`root`@`127.0.0.1` SQL SECURITY DEFINER */
/*!50013 DEFINER=`otrouser`@`%` SQL SECURITY DEFINER */
Vemos que existe un usuario que no existe en nuestro servidor, y ese el portanto el que produce el problema en el volcado.
La mejor opción en mi opinión, no es tratar de saltarse o modificar nada en el servidor, sino de obviar ese usuario, salvo que sea de interés crearlo en nuestro sistema, por otras causas.
Desactivación del SQL SECURITY DEFINER problemático
Usando sed podremos cambiar el definer que nos falla a root y volver a intentar la restauración de la copia de seguridad de mysql que nos falló a causa definer/invoker of view lack rights to use them
sed -i.bak 's/DEFINER\=\`otrouser/DEFINER\=\`root/g' my-database-dump.sql
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Desactivación de las reglas de modos SQL de un sevidor MySQL/MariaDB/Percona
Introducción
Hay una gran diferencia entre usar la desactivación de los modos SQL de un servidor SQL, por necesidad imperiosa, y otra muy distnta de persistir en la creencia de que es lo correcto.
Muchos de los modos SQL, cambia a lo largo de las vidas útiles de una versión de un sistemas de bases de datos, tipo SQL, y esto hace que en el momento más crucial ese cambio:
- Haga inservible, al menos rápidamente, un backup en un escenario de recuperación de desastres.
- No sepueda realziar una migración a un nuevo sistema por incompatibilidad de los datos contenidos.
- Por el fin de soporte de ese workaround que ha sido elminado de la ecuación en la versión nueva.
Consideraciones al Usar sql_mode="":
- Desactivación de Validaciones: Al establecer sql_mode="", se desactivan validaciones como:
-
STRICT_TRANS_TABLES: Permite que las inserciones y actualizaciones que no cumplen con los requisitos de tipo y tamaño se realicen, lo que potencialmente puede llevar a la corrupción de datos. - NO_ZERO_DATE: Previene la inserción de fechas nulas o cero que suelen considerarse inválidas.
- ONLY_FULL_GROUP_BY: Asegura que las consultas que usan GROUP BY cumplan con las reglas estándar SQL.
- Compatibilidad con PHP: Si estás trabajando con PHP y experimentas problemas con la inserción de datos, a veces desactivar modos restrictivos puede solucionar problemas. Sin embargo, esto puede llevar a que se introduzcan datos erróneos o inconsistencia. Es importante identificar por qué los datos no se estaban insertando correctamente en primer lugar.
- Prácticas Recomendadas: En lugar de desactivar todos los modos, es una buena práctica intentar configurar el sql_mode de manera más específica. Por ejemplo, podrías excluir ciertos modos según sea necesario, en lugar de dejarlo vacío completamente:
sql_mode="STRICT_TRANS_TABLES,NO_ZERO_DATE"
## Configuración en my.cnf
Para configurar esto en el archivo my.cnf, puedes agregar o modificar la línea en la sección [mysqld]:
[mysqld]
sql_mode=""
Reiniciar el Servidor
Después de realizar cambios en my.cnf, asegúrate de reiniciar el servidor de MySQL o MariaDB para que los cambios surtan efecto.
systemctl restart mariadb
Comprobación
Acceso a MySQL shell.
MariaDB [(none)]> SHOW VARIABLES LIKE 'sql_mode';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| sql_mode | |
+---------------+-------+
1 row in set (0.001 sec)
Conclusión
Si decides establecer sql_mode="", hazlo con precaución y asegúrate de revisar tu aplicación PHP para asegurarte de que todos los datos que se insertan sean válidos. También sería bueno investigar por qué ocurrían problemas sin establecer esto, ya que podrían haber soluciones más específicas y seguras sin necesidad de desactivar todas las validaciones.
Links interesantes
- Como ejecutar tu acceso a mysql en un Directadmin sin usar root
- Mysql conexión vía socket. Como saber donde está
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
ISPConfig
Un panel algo espartano, que tiene algunos tips que son importantes de conocer.
Desactivar el sistema de antispam y el antivirus en ISPConfig
Introducción
ISPConfig usa amavis junto a clamav comi sistema antivirus y antispam. En algunos escenarios esto puede ser innecesario o costos en términos de potencia, lo cual nos lleva al deseo de desactivar estos elementos de nuestro servidor
Desactivar amavis en postfix (DirectAdmin)
Editamos el fichero /etc/postfix/main.cf buscando y editando las líneas siguientes (añadir comentario #):
# content_filter = amavis:[127.0.0.1]:10024
# receive_override_options = no_address_mappings
Después debemos reiniciar postfix
systemctl restart postfix
Parar y desactivar el arranque automático de clamav y amavis
Tenemos que deshabilitar el arranque automático de estos servicios, según nuestro tipo de distribución.
Versiones ISPConfig 3.1 y superiores
Tenemos un trabajo adicional, en la edición de otros dos ficheros, que debemos comentar la línea que contienen.
/etc/postfix/tag_as_foreign.re
#/^/ FILTER amavis:[127.0.0.1]:10024
/etc/postfix/tag_as_originating.re
#/^/ FILTER amavis:[127.0.0.1]:10026
Otras posibilidades
Puede ser necesario revisar nuestro fichero master de postfix por si hubiera configuración antigua desde versiones anteriores.
/etc/postfix/master.cf
#amavis unix – – – – 2 smtp
# -o smtp_data_done_timeout=1200
# -o smtp_send_xforward_command=yes
# -o smtp_bind_address=
Enlaces
- How to disable spamfilter- and antivirus functions in ISPConfig 3
- Clamav-daemon and freshclam keep starting at bootime
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Backups
Cuestiones sobre backups, tips con rsync, etc.
Rsync sobre sistemas remotos
Introducción
rsync es una aplicación que ofrece un sistema de transmisión de ficheros, de forma incremental que permite la generación de sistemas de backups muy efectivos. Uno de los mejores ejemplos es Time Machine de Apple, que no es sino una interface visual de rsync
Sin embargo muchos sitios expresan o ponen a disposición de los usuarios ejemplos que usados en un escenario diferente del usado en un entorno personal o corporativo, son fuente de problemas.
Como norma general se usa el parámetro -a o --archive el cual es el equivalente a -rlptgoD lo cual supone que los parámetros de usuario y grupo, y los permisos de lectura, escritura y ejecución intentarán ser clonados, cosa que no funcionará e incluso creará problemas silenciosos en un entorno en el que los usuarios y grupos no son los mismos en origen que en destino.
Parámetros de rsync para usar en sistemas remotos no coincidentes
El escenario es el de realizar un backup de un sistema completo (disco principal) en un usuario remoto (no root)
# rsync --devices --specials --hard-links --one-file-system --recursive --links --times --no-perms --no-group --no-owner --itemize-changes / remote_user@remote.host:/remote/path
Parámetros con rsync-time-backup
Dado que es un programa basado en rsync con sus propias normas para anular su configuración debemos usar otro camino con --rsync-set-flags
--rsync-set-flags "-D --numeric-ids --links --hard-links -rlt --no-perms --no-group --no-owner --itemize-changes"
Parámetros
Deberás ajustar los parámetros a tu escenario, pero te explico los que he usado aquí.
| Corto | Normal | Descripción |
|---|---|---|
| -D | El mismo que --devices -aspecials | |
| -l | --links | copia los enlaces simbólicos como enlaces simbólicos |
| -H | --hard-links | preserva los enlaces duros |
| -x | --one-file-system | No copiará los dispositivos montados. Si tu sistemas tiene particiones como /var /usr y quieres copiar algo de aqui, esta opción NO debería estar aquí |
| -r | --recursive | Copiara recursivamente |
| -t | --times | Necesario sobre todo si no usamos -a, ya que será parte de la marca para saber si el fichero debe o no ser transferido o actualizado |
| --no-perms | No copiara los permisos originales. De esta forma no nos encontraremos con problemas de eliminación, uso, debidos a cuestiones de propietario /permisos. Como contrapartida, nos obliga a a tener un sistema de metadatos, que sí guarde esta información. | |
| --no-group | Para evitar el uso del grupo del propietario del fichero | |
| --no-owner | Para evitar actualizar el propietario del fichero |
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
rsync-time-backup: include y exclude
Introducción
rsync-time-backup es una buena herramienta con la salvedad de que no tiene limite por fechas de los backlups continuos basados en rsync. Es un clon de Time Machine de Mac.
Es un fork mantenido por Castrsi, con algunas mejoras.
Si trabajamos con sistemas completos hay muchos directorios y ficheros que debemos excluir e incluir.
Actualziacion 17/09/2025
Include and Exclude
Si trabajamos con sistemas remotos, deberías leer Rsync sobre sistemas remotos o tendrás problemas con los permisos y el pruning en las rotaciones de backups expirados.
Ejemplo que a mi me funciona, y que deja el orden correcto para evitar problemas.
Cualquier cambio, deberías probar si funciona.
# Primero incluir lo que quieres mantener
+ /home/***
+ /usr/local/directadmin/***
+ /var/www/***
# Luego excluir directorios del sistema
- /bin/***
- /boot/***
- /cdrom/***
- /dev/***
- /lib/***
- /lib32/***
- /lib64/***
- /libx32/***
- /media/***
- /mnt/***
- /opt/***
- /proc/***
- /run/***
- /sbin/***
- /sbin.usr-is-merged/***
- /snap/***
- /srv/***
- /swap.img
- /sys/***
- /tmp/***
- /usr/***
- /var/***
# Excluir patrones específicos
- *.git*
- */cache/*
- */usr/*
Una respuesta que ta ayudará a entender el RsyncTutorial que propone el desarrollador, algo lioso.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Diagnóstico y resolución de fallos en snapshots LVM durante backups en Proxmox
Contexto del problema
Síntomas iniciales
Durante la ejecución de backups automatizados en Proxmox 7.2.14, se producían fallos intermitentes al procesar el disco secundario (disco-1) de la VM 473, lo que causaba error en el tamaño de la copia.
Processing backup of disk 473-0
Transferring: kvm-473-0.2025-10-27-05-41-56.gz
25442648064 bytes (25 GB, 24 GiB) copied, 129 s, 197 MB/s
dd: error reading '/dev/lvm/snap-473-0': Input/output error
3051+1 records in
3051+1 records out
25594953728 bytes (26 GB, 24 GiB) copied, 130.739 s, 196 MB/s
Características del sistema
- Proxmox VE: 7.2.14
- Kernel: 5.15.74-1-pve
- Storage: LVM sobre NVMe
- Método backup: Scripts personalizados (no vzdump estándar)
- Patrón: Primera copia OK, segunda copia FAIL
Proceso de análisis
Fase 1: Verificación de espacio en VG
Descartado rápidamente. El Volume Group tenía espacio abundante:
pvs -o +pv_name,vg_name,pv_size,pv_free
PV VG Fmt Attr PSize PFree
/dev/nvme1n1p1 lvm lvm2 a-- <1.75t 757.49g
Conclusión: 757GB libres, suficiente para snapshots.
Fase 2: Revisión de logs del sistema
dmesg -T | grep -i "error\|fail\|i/o" | tail -50
Hallazgos:
[Mon Oct 27 05:38:02 2025] Buffer I/O error on dev dm-54, logical block 5923136, async page read
[Mon Oct 27 05:38:02 2025] Buffer I/O error on dev dm-54, logical block 5923136, async page read
[Mon Oct 27 05:38:02 2025] Buffer I/O error on dev dm-54, logical block 5923136, async page read
[Mon Oct 27 05:44:05 2025] Buffer I/O error on dev dm-51, logical block 6248768, async page read
- Errores en dispositivos dm-XX (device mapper → snapshots LVM)
- Tres reintentos por operación (patrón típico del kernel)
- Tipo: async page read (lectura desde snapshot)
Sospecha inicial: Problema de hardware en disco NVMe.
Fase 3: Verificación de salud del disco NVMe
smartctl -a /dev/nvme1n1p1
Resultado crítico:
SMART overall-health self-assessment test result: PASSED
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Available Spare: 100%
Percentage Used: 8%
Conclusión: El disco NVMe está perfectamente sano. No es problema de hardware.
Fase 4: Análisis de device mapper
Intentamos localizar los dispositivos dm-54 y dm-51 reportados en dmesg:
dmsetup ls --tree | grep -E "dm-5[14]"
ls -la /dev/dm-54 /dev/dm-51
# cannot access '/dev/dm-54': No such file or directory
# cannot access '/dev/dm-51': No such file or directory
Interpretación: Los snapshots temporales ya fueron destruidos tras el backup (comportamiento normal). Los errores ocurrieron durante la existencia efímera del snapshot.
Hipótesis evaluadas
Hipótesis 1: Sectores defectuosos en disco físico
- Estado: ❌ DESCARTADA
- Motivo: SMART sin errores, 0 sectores realojados
Hipótesis 2: Bug del kernel 5.15 con snapshots bajo carga
- Estado: ⚠️ POSIBLE (no confirmada)
- Motivo: Kernel antiguo con bugs conocidos en snapshot mechanism
Hipótesis 3: Snapshot COW lleno durante backup
- Estado: ✅ CONFIRMADA
- Método de validación: Monitorización en tiempo real
Diagnóstico definitivo
Herramienta de diagnóstico utilizada
Durante la ejecución del backup, se monitorizó en tiempo real el estado de los snapshots:
watch -n1 'lvs -a | grep snap'
Output revelador:
Every 1.0s: lvs -a | grep snap
snap-473-0 lvm swi-aos--- 1.00g vm-473-disk-0 7.61
snap-473-1 lvm swi-I-s--- 1.00g vm-473-disk-1 100.00
snap-999-0 vg swi-a-s--- 3.00g vm-999-disk-0 9.09
Interpretación de los flags LVM
| Campo | Valor | Significado |
|---|---|---|
| snap-473-0 | swi-aos--- | Snapshot activo, OK (7.61% uso) |
| snap-473-1 | swi-I-s--- | Snapshot INVÁLIDO (letra I mayúscula) |
| snap-473-1 | 100.00 | COW al 100% - completamente lleno |
Conclusión definitiva:
El snapshot del disco-1 alcanzó el 100% de su espacio Copy-On-Write (1GB), provocando:
- Marcado del snapshot como inválido por LVM
- Cualquier lectura posterior genera "Buffer I/O error"
- Fallo del proceso de backup
Causa raíz
¿Por qué el disco-1 y no el disco-0?
snap-473-0: 7.61% usado → VM escribe poco en este disco durante backup
snap-473-1: 100% usado → VM escribe intensivamente en este disco
El disco-1 contiene elementos con alta tasa de escritura:
- Bases de datos con logs activos
- Swap en uso
- Directorios /tmp o /var con actividad constante
- Logs del sistema operativo
El problema del tamaño de snapshot
Configuración problemática:
# Snapshot de 1GB para disco de 35GB = ~3% del tamaño del disco
lvcreate -L1G -s -n snap-473-1 /dev/lvm/vm-473-disk-1
Durante el backup (que puede tardar 2-3 minutos con 35GB):
- VM continúa funcionando
- Disco-1 recibe escrituras constantes
- Cada bloque modificado consume espacio COW
- 1GB se llena antes de completar el backup → snapshot inválido
Solución implementada
Ajuste del tamaño de snapshot en scripts de backup
Al ser un proceso solapado de hosts snapshots con creación aleatoria de marca de tiempo, y de mysqldump en el KVM, el cual por tamaños era causa del rpoblema (> 6G) no procede el aumento tan significativo de porcentaje de snapshot
Dado que hay incidentes similares, y ya habia alguna modifciaciones al script de backups de mysql, mysqldump_remote_utility.sh se procede a realizar una mejora en el script, para poder realizar los backup al vuelo, (directamente mysqldump + compresión sobre la conexión).
Consultar README_mysqldump_remote.md
Datos relevantes para otros cálculos
Cálculo del tamaño óptimo de snapshot
| Tamaño disco | Actividad VM | Snapshot recomendado |
|---|---|---|
| 35GB | Baja (logs, configs) | 10% = 3.5GB |
| 35GB | Media (servicios web) | 20% = 7GB |
| 35GB | Alta (BD, swap activo) | 30% = 10GB |
| 100GB+ | Alta | 20-30GB (límite práctico) |
Verificación del tamaño durante backup
Añadir monitorización al script de backup:
#!/bin/bash
# En paralelo durante el backup
watch -n5 "lvs -a | grep snap-473 | awk '{print \$1, \$6}'"
# O con alertas:
while true; do
USAGE=$(lvs --noheadings -o snap_percent snap-473-1 2>/dev/null | xargs)
if (( $(echo "$USAGE > 80" | bc -l) )); then
echo "WARNING: Snapshot at ${USAGE}%"
fi
sleep 5
done
Comandos útiles para diagnóstico
Monitorización en tiempo real
# Ver estado de snapshots activos
watch -n1 'lvs -a | grep snap'
# Ver uso específico con más detalle
lvs -a -o +chunksize,snap_percent | grep snap
# Logs en tiempo real
dmesg -wT | grep -i "error\|snapshot"
Post-mortem tras fallo
# Revisar logs del kernel
dmesg -T | grep -i "error\|fail\|i/o" | tail -50
# Estado de los VG
vgs -o +lv_metadata_size,metadata_percent
# Snapshots huérfanos o colgados
lvs -a | grep snap
# Salud del storage
smartctl -a /dev/nvmeXnY
Lecciones aprendidas
-
Los errores de I/O en dm-XX no siempre son hardware: Primero verificar el estado de snapshots LVM.
-
El tamaño de snapshot no es porcentaje fijo: Depende de la tasa de escritura durante el backup, no del tamaño del disco.
-
Herramienta clave:
watch -n1 'lvs -a | grep snap'permite ver en tiempo real el llenado del COW. -
Pattern recognition: "Primera copia OK, segunda FAIL" → indica recurso que se agota (no hardware defectuoso).
-
Flag 'I' en lvs: Snapshot inválido por COW lleno. Crítico para diagnóstico rápido.
Prevención futura
Script de validación pre-backup
#!/bin/bash
# validate_snapshot_size.sh
VM_ID=$1
DISK_NUM=$2
DISK_LV="/dev/lvm/vm-${VM_ID}-disk-${DISK_NUM}"
# Obtener tamaño del disco
DISK_SIZE_G=$(lvs --noheadings -o lv_size --units g "$DISK_LV" | tr -d 'g' | xargs)
# Calcular snapshot recomendado (30%)
RECOMMENDED_G=$(echo "$DISK_SIZE_G * 0.3 / 1" | bc)
# Obtener espacio libre en VG
VG_NAME=$(lvs --noheadings -o vg_name "$DISK_LV" | xargs)
FREE_G=$(vgs --noheadings -o vg_free --units g "$VG_NAME" | tr -d 'g' | xargs)
echo "Disco: $DISK_LV"
echo "Tamaño: ${DISK_SIZE_G}G"
echo "Snapshot recomendado: ${RECOMMENDED_G}G"
echo "Espacio libre en VG: ${FREE_G}G"
if (( $(echo "$FREE_G < $RECOMMENDED_G" | bc -l) )); then
echo "ERROR: Espacio insuficiente en VG"
exit 1
fi
echo "OK: Suficiente espacio disponible"
Monitorización automatizada
#!/bin/bash
# monitor_snapshots.sh
# Ejecutar en paralelo durante backups
THRESHOLD=85 # Alertar al 85% de uso
while true; do
lvs -a --noheadings -o lv_name,snap_percent 2>/dev/null | grep snap | while read name percent; do
if [ -n "$percent" ]; then
percent_int=$(echo "$percent" | cut -d'.' -f1)
if [ "$percent_int" -ge "$THRESHOLD" ]; then
logger -t backup-monitor "WARNING: Snapshot $name at ${percent}%"
# Opcional: enviar alerta email/telegram
fi
fi
done
sleep 10
done
Referencias
- LVM Snapshot documentation:
/usr/share/doc/lvm2/ - Device mapper errors:
man dmsetup
Fecha de resolución: 27 de octubre de 2025
Sistema: Proxmox VE 7.2.14
Causa raíz: Snapshot COW undersized para tasa de escritura de la VM
Solución: Mejora script cliente KVM para mysqldump en solución on-fly
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Tips and Tricks
Trucos para usuarios linux
Como convertir ficheros .flac a .mp3 en el shell de linux con ffmpeg
Introducción
Algunas veces me descargo o me pasan algun disco de música clasica en forma .flac y la verdad, ni tengo el equipo para tal audición, ni tanto espacio en mis saturados discos. Asi que lo mejor es convertirlos a .mp3 (también puedes hacerlo a .ogg si eres muy OpenSource (aunque mp3 ya es formato abierto)
Convertir todos los ficheros .flac de un directorio a .mp3 con ffmpeg en linux con el shell
Bueno, ni que decir tiene que debes tener instalado fmpeg y los codecs, pero eso lo dejo para otro momento.
Recursivo
find -name "*.flac" -exec ffmpeg -i {} -acodec libmp3lame -ab 128k {}.mp3 \;
Un solo nivel
find -maxdepth 1 -name "*.flac" -exec ffmpeg -i {} -acodec libmp3lame -ab 128k {}.mp3 \;
Enlaces
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Teclas Inicio (Home) y Final (End) en ZSH y oh-my-zsh con Powershell
Introducción
La verdad es que me encanta usar ZHS en combinación de Oh-My-Zsh y el tema PowerLevel10k pero tenía un problema con las teclas Inicio (Home) y Fin (End) que no funcionan. Al final lo solucioné y te cuento como lo hice.
Solución al problema
Para probar si te va a funcionar antes de editar el fichero de configuración de zsh, te aconsejo que ejecutes en el terminal y después pruebes las teclas:
❯ bindkey "\033[1~" beginning-of-line
❯ bindkey "\033[4~" end-of-line
Si te funciona (debería), es necesario editar el fichero ~/.zshrc y añadirlo.
Después ejecuta:
❯ source ~/.zshrc
Enlaces
- Candrew34 en github -> Cannot using home/end key after install oh-my-zsh
- List of zsh bindkey commands
- Binding Keys in Zsh – jdhaos’s blog
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Linux, paquetes instalados desde el shell
Introducción
A veces necesitamos conocer que paquetes tenemos instalados en nuestra distribución linux. Y no usamos un entorno gráfico.
Distribuciones basadas en .deb
Para conocer qué paquetes están instalados en nuestra distribución linux, desde el shell ejecutaremos
# apt list --installed | grep nginx
WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
nginx/stable,now 1.18.0-2~focal amd64 [installed,upgradable to: 1.20.1-1~focal]
Distribuciones basadas en .rpm
rpm -qa | grep apache
ea-apache24-mod_bwlimited-1.4-47.52.2.cpanel.x86_64
...
ea-apache24-2.4.48-3.12.1.cpanel.x86_64
...
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Cómo instalar y activar el repositorio EPEL en Centos 7/8
Introducción
El repositorio EPEL (Extra Packages for Enterprise Linux) es un repositorio de un grupo de Fedora que crea, mantiene y administra una serie de paquetes .rpm ausentes o presentes en versiones anticuadas, para mejorar las capacidades de las distros basadas en Redhat (RHEL, CentOs, Scientific Linux, Fedora)
Sus instalación en un servidor con cPanel requiere ciertas normas para evitar problemas posteriores, que algunas veces pueden ser bastante graves para nuestro sistema.
Instalación EPEL (CentOs 7/8)
[root@centos7 ~]# yum -y install epel-release
Complementos cargados:fastestmirror
Loading mirror speeds from cached hostfile
* base: mirror.tedra.es
* extras: mirror.tedra.es
* updates: mirror.tedra.es
Resolviendo dependencias
--> Ejecutando prueba de transacción
---> Paquete epel-release.noarch 0:7-11 debe ser instalado
--> Resolución de dependencias finalizada
Dependencias resueltas
=============================================================================================================================================================================================
Package Arquitectura Versión Repositorio Tamaño
=============================================================================================================================================================================================
Instalando:
epel-release noarch 7-11 extras 15 k
Resumen de la transacción
=============================================================================================================================================================================================
Instalar 1 Paquete
Tamaño total de la descarga: 15 k
Tamaño instalado: 24 k
Downloading packages:
epel-release-7-11.noarch.rpm | 15 kB 00:00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Instalando : epel-release-7-11.noarch 1/1
Comprobando : epel-release-7-11.noarch 1/1
Instalado:
epel-release.noarch 0:7-11
¡Listo!
Desactivación (cpanel consejo)
Por defecto un repositorio se instalan activados, lo cual es bastante peligroso en un servidor con cPanel o con otro panel intrusivo (el 99,9% lo son)
Deberemos editar el fichero de configuración del repositorio /etc/yum.repos.d/epel.repo editando la línea enable=1 a enable=0
[epel]
name=Extra Packages for Enterprise Linux 7 - $basearch
#baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch
metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch
failovermethod=priority
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
Cuando queramos instalar o actualizar algún paquete del repositorio epel deberemos usar la opción --enablerepo=epel en nuestro comando yum
Ejemplo
[root@centos7 ~]# yum --enablerepo=epel -y install snapd
Verificacion doble de desactivación
Como es importante, deberíamos hacer una doble verificación de que el repositorio no está activo, con el comando yum repolist que en caso de no estar activo, no lo mostrará.
[root@centos7 ~]# yum repolist
Complementos cargados:fastestmirror
Loading mirror speeds from cached hostfile
* base: mirror.tedra.es
* extras: mirror.tedra.es
* updates: mirror.tedra.es
id del repositorio nombre del repositorio estado
base/7/x86_64 CentOS-7 - Base 10.072
extras/7/x86_64 CentOS-7 - Extras 498
updates/7/x86_64 CentOS-7 - Updates 2.579
repolist: 13.149
Conocer los paquetes disponibles en EPEL
Es un comando sencillo que mostrará la lista de paquetes del repositorio.
[root@centos7 ~]# yum --disablerepo="*" --enablerepo="epel" list available
Complementos cargados:fastestmirror
Loading mirror speeds from cached hostfile
* epel: mirror.eixamcoop.cat
Paquetes disponibles
0ad.x86_64 0.0.22-1.el7 epel
0ad-data.noarch 0.0.22-1.el7 epel
0install.x86_64 2.11-1.el7 epel
2048-cli.x86_64 0.9.1-1.el7 epel
2048-cli-nocurses.x86_64 0.9.1-1.el7 epel
. . .
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Conocer el tamaño de unas carpetas ignorando los enlaces duros (rsync)
Rsync, enlaces duros y du
En mi trabajo uso rsync con un sistema de enlaces duros, como el Time Machine de Apple. Y a veces es bueno saber o conocer, el tamaño de las carpetas ignorando los enlaces duros, en los que esta basado este sistema de backup continuo.
du
$ du -hc --max-depth=1 path/
24G rsync/2022-03-17-065908
1.6M rsync/2022-03-17-072202
1.2G rsync/2022-03-17-105858
1.1G rsync/2022-03-17-074333
79.9G rsync/
79.9G total
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como esta, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Ssh se sale (break) de un ciclo (loop) en un script bash
Introducción
Uso Rsync time backup para algunos proyectos, pero el caso de uno en particular con más de 8TB de ficheros a mantener en backup, y con múltiples usuarios, prefiero usar una estrategia de copia de seguridad por usuario.
Cuando programé el script bash rápido para hacer este trabajo, me encontré que la finalización del script se alcanzaba tras leer el completar la primera copia de seguridad.
Tras finalizar correctamente el proceso de sincronización.
El problema es que ssh lee desde la entrada estándar, por lo tanto, se come todas las líneas restantes.
Solución al problema en ssh
ssh $USER@$SERVER "COMMAND_IN_REMOTE" < /dev/null
También podemos usar ssh -n en lugar de la redirección a ninguna parte.
-n' Redirects stdin from /dev/null (actually, prevents reading from stdin). This must be used when ssh is run in the background. A common trick is to use this to run X11 programs on a remote machine. For example, ssh -n shadows.cs.hut.fi emacs & will start an emacs on shadows.cs.hut.fi, and the X11 connection will be automatically forwarded over an encrypted channel. The ssh program will be put in the background. (This does not work if ssh needs to ask for a password or passphrase; see also the -f option.)
Solución en Rsync time backup
En este software no hay posibilidad de modificar o usar el parámetro -n asi que solo se puede hacer via redirección a ninguna parte < /dev/null
while IFS= read -r line
do
case $line in
appdata_ociz9efdik2y|transmission-daemon|updater-ociz9efdik2y)
continue
;;
*)
echo "$line"
/srv/mypath/diwan/rsync-time-backup/rsync_tmbackup.sh --rsync-set-flags "-D -zz --numeric-ids --links --hard-links -rlt --no-perms --no-group --no-owner --itemize-changes" --strate
gy "1:1 7:7 30:30" -p 9999 root@mypath.domain.net:/data/"$line" /srv/storage/mypath/rsync/"$line" < /dev/null
;;
esac
done < "$input"
Agradecimientos
- ssh breaks out of while-loop in bash - duplicate
- While loop stops reading after the first line in Bash
- ssh(1) - Linux man page
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Redis Failed to start Advanced key-value store.
Introducción
En algún momento nuestro servidor Redis falla, y deja de estar operativo. Reiniciamos pero no arranca y en su lugar muestra un error cuando hacemos un sudo systemctl status redis-server
jun 02 17:43:33 abkrim-nox systemd[1]: Failed to start Advanced key-value store.
Por más que lo intentamos no lo consigue. Veamos que podemos hacer.
Analizando el problema
Systemctl logs
journalctl -xeu redis-server.service
░░ The job identifier is 3699 and the job result is done.
jun 02 17:45:14 abkrim-nox systemd[1]: redis-server.service: Start request repeated too quickly.
jun 02 17:45:14 abkrim-nox systemd[1]: redis-server.service: Failed with result 'exit-code'.
░░ Subject: Unit failed
░░ Defined-By: systemd
░░ Support: http://www.ubuntu.com/support
░░
░░ The unit redis-server.service has entered the 'failed' state with result 'exit-code'.
jun 02 17:45:14 abkrim-nox systemd[1]: Failed to start Advanced key-value store.
Bueno ya tenemos una pista pero viendo los logs (bendita bitácora) podemos obtener más información.
sudo tail -n100 /var/log/redis/redis-server.log
…
7471:M 02 Jun 2022 17:48:00.413 * DB loaded from base file appendonly.aof.66.base.rdb: 0.000 seconds
7471:M 02 Jun 2022 17:48:00.893 # Bad file format reading the append only file appendonly.aof.66.incr.aof: make a backup of your AOF file, then use ./redis-check-aof --fix <filename.manifest>
Con esto vemos que nuestra configuración de redis esta configurado para usar una estrategia AOF (append-only file) para evitar perdidas de datos en caso de una terminación brusca (energía, kill -9,..) que no permita la escritura de los datos activos a disco.
appendonly yes
Y además de esto, nuestro fichero AOF esta corrupto. Así pues hay que recuperarlo.
Reparando el fichero AOF
El comando general es `redis-check-aof –fix
En mi caso un Ubuntu 22.04 con redis instalado vía repositorio, siendo la versión 6.7
❯ sudo ls -lisah /var/lib/redis
total 16K
17170880 4,0K drwxr-x--- 3 redis redis 4,0K jun 2 20:19 .
16777254 4,0K drwxr-xr-x 94 root root 4,0K may 31 10:43 ..
17170910 4,0K drwxr-x--- 2 redis redis 4,0K jun 2 18:34 appendonlydir
17170564 4,0K -rw-rw---- 1 redis redis 1,6K jun 2 20:19 dump.rdb
❯ sudo ls -lisah /var/lib/redis/appendonlydir
total 836K
17170910 4,0K drwxr-x--- 2 redis redis 4,0K jun 2 18:34 .
17170880 4,0K drwxr-x--- 3 redis redis 4,0K jun 2 20:19 ..
17171350 4,0K -rw-rw---- 1 redis redis 1,6K jun 2 18:34 appendonly.aof.67.base.rdb
17171130 820K -rw-r----- 1 redis redis 815K jun 2 20:21 appendonly.aof.67.incr.aof
17171294 4,0K -rw-r----- 1 redis redis 92 jun 2 18:34 appendonly.aof.manifest
Así pues el comando sería
sudo /usr/bin/redis-check-aof --fix /var/lib/redis/appendonlydir/appendonly.aof.manifest
Start checking Multi Part AOF
Start to check BASE AOF (RDB format).
[offset 0] Checking RDB file appendonly.aof.66.base.rdb
[offset 26] AUX FIELD redis-ver = '7.0.0'
[offset 40] AUX FIELD redis-bits = '64'
[offset 52] AUX FIELD ctime = '1653893946'
[offset 67] AUX FIELD used-mem = '5178616'
[offset 79] AUX FIELD aof-base = '1'
[offset 81] Selecting DB ID 0
[offset 3048] Checksum OK
[offset 3048] \o/ RDB looks OK! \o/
[info] 19 keys read
[info] 9 expires
[info] 9 already expired
RDB preamble is OK, proceeding with AOF tail...
AOF analyzed: filename=appendonly.aof.66.base.rdb, size=3048, ok_up_to=3048, ok_up_to_line=1, diff=0
BASE AOF appendonly.aof.66.base.rdb is valid
Start to check INCR files.
AOF appendonly.aof.66.incr.aof format error
AOF analyzed: filename=appendonly.aof.66.incr.aof, size=64241117, ok_up_to=64238121, ok_up_to_line=4261202, diff=2996
This will shrink the AOF appendonly.aof.66.incr.aof from 64241117 bytes, with 2996 bytes, to 64238121 bytes
Continue? [y/N]: y
Successfully truncated AOF appendonly.aof.66.incr.aof
All AOF files and manifest are valid
Después de esto ya podremos iniciar redis
❯ sudo systemctl restart redis-server
❯ sudo systemctl status redis-server
● redis-server.service - Advanced key-value store
Loaded: loaded (/lib/systemd/system/redis-server.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2022-06-02 17:56:19 CEST; 7min ago
Docs: http://redis.io/documentation,
man:redis-server(1)
Main PID: 12969 (redis-server)
Status: "Ready to accept connections"
Tasks: 6 (limit: 38330)
Memory: 3.9M
CPU: 1.538s
CGroup: /system.slice/redis-server.service
└─12969 "/usr/bin/redis-server 127.0.0.1:6379" "" "" "" "" "" "" ""
jun 02 17:56:18 abkrim-nox systemd[1]: Starting Advanced key-value store...
jun 02 17:56:19 abkrim-nox systemd[1]: Started Advanced key-value store.
Enlaces
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Comando find con -maxdepth excluyendo el propio directorio
Comando find con -maxdepth excluyendo el propio directorio
A veces es necesario ejecutar este comando de manera recursiva pero queremos obviar el propio directorio desde el que se ejecuta como por ejemplo para eliminar todos directorios de una carpeta de rsync con enlaces duros de forma ordenada.
find . -maxdepth 1 -type d | sed -r '/^\.$/d'
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Du y los ficheros o directorios ocultos
El comando du y los ficheros ocultos
Muchas veces al usar el comando du para localiza directorios con elevado o anormal consumo de espacio en disco nos topamos, con un directorio en el que la información que du nos ofrece no se ajusta a nivel directorio con el nivel subdirectorios.
❯ du -sh *
1,3G api
7,1G investigo
5,2G sitelight
1,4G sitelight2
❯ cd investigo
❯ du -sh *
179M investigo/backup
20K investigo/conf
408K investigo/logs
275M investigo/sitelight
3,2G investigo/web
Nos faltan casi 4 Gb.
Comando du incluyendo los directorios ocultos
du -hs investigo/.[^.]*
4,0K investigo/.bash_history
4,0K investigo/.bash_logout
4,0K investigo/.bashrc
3,4G investigo/.cache
604K investigo/.config
8,0K investigo/.emacs.d
4,0K investigo/.gitconfig
32K investigo/.java
96K investigo/.local
4,0K investigo/.mysql_history
32M investigo/.npm
18M investigo/.oh-my-zsh
92K investigo/.p10k.zsh
4,0K investigo/.profile
4,0K investigo/.shell.pre-oh-my-zsh
20K investigo/.ssh
4,0K investigo/.Xauthority
8,0K investigo/.yarn
4,0K investigo/.yarnrc
48K investigo/.zcompdump
52K investigo/.zcompdump-coresitelight-5.8
116K investigo/.zcompdump-coresitelight-5.8.zwc
28K investigo/.zsh_history
12K investigo/.zshrc
Alternativas
du -sh .[!.]* * 2>/dev/null | sort -rh
# con shopt:
shopt -s dotglob && du -sh */ | sort -rh
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como esta, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Como vaciar o eliminar emails antiguos en dovecot sin usar find
Dovecot y los comandos olvidados (Re-editado 2025/07/31)
Muchas veces, y me incluyó yo, por vaguería y algo de desconocimiento, pues una se acostumbra a los fácil, usamos una combinación de find para hacer un vaciado de alguna cuenta o carpeta de correo que se llenó.
Pues bien, eso es mejor hacerlo con las herramientas del propio Dovecot (si es este el sistema de servidor IMAP que usamos)
Eliminación de correos IMAP por antigüedad
Ejemplo
doveadm expunge -u jane.doe@example.org mailbox Spam before 2w
Redicción 2025/07/31
Diferencia entre savedbefore y before en Dovecot:
savedbefore:
- Fecha cuando Dovecot guardó físicamente el email en el servidor
- Se actualiza con migraciones, restores, reorganizaciones del maildir
- Problemático después de mantenimientos del servidor
before:
- Fecha real de recepción/entrega del email
- Corresponde a cuando el email llegó originalmente al buzón
- Más confiable para limpiezas por antigüedad
Resumen práctico:
before→ Usa la fecha real/original del email ✅savedbefore→ Usa fecha técnica de almacenamiento (evitar tras restores)
En tu caso: después del restore complicado que mencionaste, todos los emails tienen saved_date reciente, por eso savedbefore 7d no encontraba nada, pero before 7d sí encuentra los 86K emails realmente antiguos.
Usa siempre before para limpiezas normales.
Obtener la lista de buzones
Dado que los buzones se escriben en el shell de distinta manera, para usarse en el comando es bueno obtener la liista
doveadm mailbox list -u jane.doe@example.org
Archive
Mantenimientos
Mantenimientos/mysql
ASSP
Seguridad
Seguridad/inmunifyAV
Seguridad/Wordfence
Services
Services/Failed
LFD
[Gmail]
[Gmail]/Importantes
Junk
Trash
Sent
Drafts
INBOX
Conteo de mensajes
doveadm mailbox status -u jane.doe@example.orgm messages Sistemas.correo
Sistemas.correo messages=5267
Purgado por asunto
doveadm expunge -u jane.doe@example.org mailbox 'Mantenimientos/mysql' HEADER Subject "Palabra Clave"
Purgado mas complejo HEADER y BODY
doveadm expunge -u jane.doe@example.org mailbox 'Mantenimientos/mysql' HEADER Subject "Palabra Clave" BODY "Otro texto"
- Consulta la documentación de Dovecot - Expunge
- doveadm: Delete messages older than date
Eliminación por linea de asunto
Ejemplo
doveadm expunge -u jane.doe@example.org mailbox INBOX subject Cron
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
rc.local en systemas Debian usando systemd. Ejemplo redis
Introducción
Algunos servicios como redis pueden requerir de ciertas configuraciones del sistema para su mejor fucnionamiento, como puede ser Transparent Huge Pages (THP) desactivado. Si puedes desactivarlo porque no afecta a otros servicios de tu servidor (atento a esto, que no es salir por la calle del medio sin pensar en las implicaciones) es bueno hacerlo.
3336867:M 04 Dec 2023 18:05:32.941 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
Solución
La solución pasa por desactivarlo en el sistema
echo never > /sys/kernel/mm/transparent_hugepage/enabled
Pero necesitamos ejecutar esto al reinicio, o perdermos la configuración deseada. La opcion normal sería añadirl al scripot de arranque, como muchos dicen, en /etc/rc.local pero distors basadas en Debia, o otras basadas en RedHat, no tiene ese fiochero porque usan ya de hace tiempo systemd para la gestión de estas cuestiones.
Crear un Servicio systemd para Desactivar THP
Crear un Archivo de Servicio systemd: Abre un nuevo archivo en el directorio de servicios de systemd con un editor de texto como nano o vim. Por ejemplo:
sudo nano /etc/systemd/system/disable-thp.service
Donde añadimos
[Unit]
Description=Disable Transparent Huge Pages (THP)
[Service]
Type=oneshot
ExecStart=/bin/sh -c 'echo never > /sys/kernel/mm/transparent_hugepage/enabled'
[Install]
WantedBy=multi-user.target
Lo habilitamos
sudo systemctl daemon-reload
sudo systemctl enable disable-thp.service
sudo systemctl start disable-thp.service
Verificamos
cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Bad Bots y la pesadilla del tráfico. Htaccess en Apache 2.4
Cada vez esta pero el tema. Un ejercito de web scrappers, de personas dedicadas a vivir de crear contenido falso, indexable, o de robar imáganes, pulula por la red.
Una de las mejores formas de acabar con ellos es denegarles el acceso, en nuestro fichero .htaccess
.htaccess anti bad bots
La cuesgtión es añadir la lista de robots no deseados en nuestro fichero .htaccces usando para ello las directivas setenvif
# Start Bad Bot Prevention
<IfModule mod_setenvif.c>
# SetEnvIfNoCase User-Agent ^$ bad_bot
SetEnvIfNoCase User-Agent "^12soso.*" bad_bot
SetEnvIfNoCase User-Agent "^192.comAgent.*" bad_bot
SetEnvIfNoCase User-Agent "^1Noonbot.*" bad_bot
...
<Limit GET POST PUT>
Order Allow,Deny
Allow from all
Deny from env=bad_bot
</Limit>
</IfModule>
# End Bad Bot Prevention
-
<IfModule mod_setenvif.c>Esta directiva comprueba si el módulo mod_setenvif está habilitado. Si lo está, se ejecuta el código dentro de este bloque. -
SetEnvIfNoCase User-Agent "^12soso.*" bad_bot: Esta directiva establece una variable de entorno llamada bad_bot si el User-Agent comienza con "12soso". -
<Limit GET POST PUT>: Esta directiva limita las reglas dentro de este bloque a los métodos HTTP especificados (GET, POST y PUT). -
Order Allow,Deny: Define el orden en el que se aplican las reglas de acceso. Primero se aplican las reglasAllowy luego las reglasDeny -
Allow from all: Permite el acceso a todos por defecto. -
Deny from env=bad_bot: Deniega el acceso a cualquier solicitud que tenga la variable de entorno bad_bot establecida. - los
</cierra la directiva corrrespondiente
La lista
Hay muchas, pero esta lista es un buen punto de partida y se actualiza regularmente. Incluso puedes mantenerla con algun pequeño script.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Sudo sin contraseña
Configuración y uso de sudo en sistemas linux
Introducción sobre el comando sudo
¿Qué Hace sudo?
El comando sudo (Super User DO) permite a un usuario autorizado ejecutar comandos con privilegios de otro usuario, normalmente el usuario root. Es una herramienta fundamental para la administración de sistemas, ya que facilita la realización de tareas que requieren permisos elevados sin necesidad de cambiar de usuario.
Alcances en seguridad y confiabilidad
-
Seguridad:
sudomejora la seguridad al permitir un control granular sobre quién puede ejecutar qué comandos. Registra todas las actividades realizadas, lo que facilita la auditoría y el seguimiento de acciones administrativas. -
Confiabilidad: Reduce la necesidad de compartir la contraseña de root, limitando el acceso a privilegios elevados únicamente a usuarios específicos y comandos determinados.
Ubicación de su configuración
La configuración de sudo se encuentra principalmente en el archivo /etc/sudoers. Además, se pueden añadir configuraciones específicas en el directorio /etc/sudoers.d/.
En Macos lo ficheros
/etcrealmente estan en/private/etc/
Usar visudo para la edición (aconsejado)
Editar el archivo /etc/sudoers directamente puede ser arriegado, ya que un error de sintaxis puede bloquear el acceso administrativo. Por ello, se recomienda utilizar el comando visudo, que verifica la sintaxis antes de aplicar los cambios.
Hacer un backup antes de editar
Antes de modificar el archivo sudoers, es prudente realizar una copia de seguridad:
sudo cp /etc/sudoers /etc/sudoers.backup_$(date +%Y%m%d)
Este comando crea una copia del archivo sudoers con la fecha actual, facilitando la restauración en caso de errores.
Editar con visudo
Para editar el archivo sudoers de manera segura:
sudo visudo
Este comando abre el archivo en el editor predeterminado configurado para visudo (generalmente nano o vi) y verifica la sintaxis al guardar.
Diferentes posibilidades de configuración
Permitir sudo sin pedir contraseña
Para que un usuario pueda ejecutar comandos con sudo sin necesidad de ingresar una contraseña, añade la siguiente línea en el archivo sudoers:
usuario ALL=(ALL) NOPASSWD:ALL
Ejemplo:
javier ALL=(ALL) NOPASSWD:ALL
Permitir sudo sin pedir contraseña pero limitado a algunos comandos
Para otorgar permisos de sudo sin contraseña pero restringidos a comandos específicos:
usuario ALL=(ALL) NOPASSWD:/ruta/al/comando1, /ruta/al/comando2
Si tenemos mas d eun comando puede ser mas pratico usar una variable, un fichero de .conf especifico.
touch /etc/sudoers.d/mi_usuario_sudo
visudo -f /etc/sudoers.d/mi_usuario_sudo
Añade la configuración deseada (es un ejemplo)
Cmnd_Alias PRTG = /usr/sbin/csf, /usr/local/directadmin/scripts/letsencrypt.sh, /usr/bin/ls, /usr/bin/cat, /usr/bin/tail
admin ALL=(ALL) NOPASSWD: PRTG
Guadar y cerrar.
Ejemplo:
javier ALL=(ALL) NOPASSWD:/usr/bin/systemctl restart nginx, /usr/bin/systemctl status nginx
Atención: En sistemas como macOS, una configuración incorrecta que elimina la solicitud de contraseña puede bloquear el acceso administrativo si no existe otro usuario con privilegios de superadministrador.
Usar /etc/sudoers.d/ para configuraciones específicas de usuarios
En lugar de modificar directamente el archivo sudoers, es posible crear archivos individuales para cada usuario en el directorio /etc/sudoers.d/. Esto facilita la gestión y evita conflictos.
Creación de un Archivo de Configuración para un Usuario
-
Crear el Archivo:
sudo nano /etc/sudoers.d/usuario -
Añadir las Reglas de
sudo:Permitir
sudosin contraseña:usuario ALL=(ALL) NOPASSWD:ALLPermitir
sudosin contraseña pero limitado a ciertos comandos:usuario ALL=(ALL) NOPASSWD:/usr/bin/systemctl restart nginx, /usr/bin/systemctl status nginx -
Guardar y Cerrar el Archivo:
Presiona
Ctrl + X, luegoYyEnterpara guardar los cambios. -
Verificar la Sintaxis:
visudoautomáticamente verifica la sintaxis al editar el archivo. Sin embargo, puedes comprobar manualmente ejecutando:sudo visudo -cf /etc/sudoers.d/usuarioEste comando validará la configuración e inmformará de cualquier error.
Resumen de comandos clave
# Crear una copia de seguridad del archivo sudoers
sudo cp /etc/sudoers /etc/sudoers.backup_$(date +%Y%m%d)
# Editar el archivo sudoers de manera segura
sudo visudo
# Permitir a un usuario ejecutar todos los comandos sin contraseña
usuario ALL=(ALL) NOPASSWD:ALL
# Permitir a un usuario ejecutar comandos específicos sin contraseña
usuario ALL=(ALL) NOPASSWD:/ruta/al/comando1, /ruta/al/comando2
# Crear un archivo de configuración específico para un usuario
sudo nano /etc/sudoers.d/usuario
# Verificar la sintaxis de un archivo en sudoers.d
sudo visudo -cf /etc/sudoers.d/usuario
Consideraciones Adicionales
-
Permisos de Archivos: Asegúrate de que los archivos en
/etc/sudoers.d/tengan permisos correctos (generalmente 0440) para evitar problemas de seguridad.sudo chmod 0440 /etc/sudoers.d/usuario -
Evitar Errores de Sintaxis: Siempre utiliza
visudoo editores diseñados para manejar la configuración desudopara prevenir errores que puedan bloquear el acceso administrativo. -
Uso Responsable de
NOPASSWD: Otorgar permisos sin contraseña debe hacerse con cautela, limitando el acceso solo a los comandos estrictamente necesarios para minimizar riesgos de seguridad. -
Documentación y Auditoría: Mantén una documentación clara de las configuraciones realizadas y revisa periódicamente los permisos otorgados para asegurar que siguen siendo necesarios y seguros.
-
En MacOS una configuración erronea del usuario administrador puede ser fatal y muy complicada la recuperación del desastre. Se recomienda por esto y po rmuchas mas cosas, tener siempre un segundo usuario SuperAdmin en un sistema MacOs
Conclusión
El uso adecuado de sudo es esencial para la administración segura y eficiente de sistemas Linux. Configurarlo correctamente, utilizando herramientas como visudo y aplicando buenas prácticas de seguridad, garantiza que los usuarios puedan realizar tareas administrativas sin comprometer la integridad y seguridad del sistema.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Reparar el fichero .zsh_history: zsh: corrupt history file /home/USER/.zsh_history
Introducción
A ves por lo que sea se corrompe el fichero de historia de ZSH .zsh_historyy nos aparece el mensaje en el shell, cuando entramos al shell, actualizamos Oh My Zsh
zsh: corrupt history file /home/USER/.zsh_history
Se puede corregir el archivo de historial corrupto de Zsh (.zsh_history) siguiendo estos pasos. La corrupción del archivo de historial puede ocurrir por diversas razones, como cierres inesperados de la terminal o conflictos de escritura. Aquí te muestro cómo solucionarlo:
Pasos para Corregir un Archivo de Historial Corrupto en Zsh
-
Hacer una Copia de Seguridad: Antes de realizar cualquier cambio, es recomendable hacer una copia de seguridad del archivo de historial corrupto:
cp ~/.zsh_history ~/.zsh_history_backup -
Eliminar Líneas Corruptas: Abre el archivo de historial con un editor de texto como
nanoovimy elimina las líneas corruptas o caracteres extraños. Puedes usar el siguiente comando para abrirlo connano:nano ~/.zsh_historyBusca líneas que no tengan sentido o que estén incompletas y elimínalas.
-
Reparar el Archivo de Historial: Puedes intentar reparar el archivo de historial usando el siguiente comando, que eliminará líneas corruptas automáticamente:
strings ~/.zsh_history > ~/.zsh_history_clean mv ~/.zsh_history_clean ~/.zsh_historyEl comando
stringsextrae solo las cadenas de texto legibles, lo que puede ayudar a limpiar el archivo. -
Recargar el Historial: Después de limpiar el archivo, recarga el historial en la sesión actual de Zsh:
source ~/.zshrc -
Verificar el Historial: Asegúrate de que el historial se carga correctamente y que no hay mensajes de error al iniciar una nueva sesión de terminal.
Notas Adicionales
-
Permisos: Asegúrate de tener los permisos adecuados para editar el archivo
.zsh_history. - Consistencia: Si experimentas problemas frecuentes con el historial, verifica que no haya múltiples instancias de Zsh escribiendo en el archivo al mismo tiempo.
Siguiendo estos pasos, deberías poder corregir el archivo de historial corrupto de Zsh y evitar problemas futuros.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
El archivo hosts para trabajar en un servidor o ip distinto del de la resolución DNS
Introudccion fichero de sistema: hosts
El archivo hosts es un archivo de texto simple que se utiliza para mapear nombres de host a direcciones IP. Esto es útil para redirigir nombres de dominio a direcciones IP específicas, lo que puede ser especialmente útil durante las migraciones de sistemas para probar configuraciones antes de pasar a producción.
Ubicaciones del Archivo hosts
-
Windows:
C:\Windows\System32\drivers\etc\hosts -
Linux:
/etc/hosts -
MacOS:
/private//etc/hosts
Uso del Archivo hosts
El archivo hosts permite redirigir un nombre de dominio a una dirección IP específica. Esto es útil para pruebas locales o para verificar un sitio web en un servidor diferente antes de cambiar los registros DNS.
Formato del Archivo hosts
El archivo hosts tiene un formato simple, donde cada línea contiene una dirección IP seguida de uno o más nombres de host. Los comentarios se pueden agregar usando el símbolo #.
# Example of a hosts file entry
127.0.0.1 localhost
192.168.1.100 example.com www.example.com
Ejemplo de Uso para Migraciones
Supongamos que estás migrando un sitio web a un nuevo servidor con la dirección IP 192.168.1.100 y quieres probar el sitio antes de actualizar los registros DNS. Puedes editar el archivo hosts para redirigir el dominio a la nueva IP:
-
Abrir el Archivo
hosts:- Usa un editor de texto con privilegios de administrador para abrir el archivo
hostsen tu sistema operativo.
- Usa un editor de texto con privilegios de administrador para abrir el archivo
-
Agregar una Entrada para el Dominio:
- Añade una línea en el archivo
hostscon la nueva dirección IP y el dominio que deseas redirigir.
192.168.1.100 example.com www.example.com - Añade una línea en el archivo
-
Guardar los Cambios:
- Guarda el archivo y cierra el editor.
-
Verificar la Redirección:
- Abre un navegador web e ingresa el dominio
example.com. Deberías ser redirigido a la dirección IP especificada en el archivohosts.
- Abre un navegador web e ingresa el dominio
Consideraciones
-
Privilegios de Administrador: Necesitarás privilegios de administrador para editar el archivo
hosts.(uso de sudo, su...) -
Cache de DNS: Puede ser necesario limpiar la caché de DNS después de editar el archivo
hostspara que los cambios surtan efecto. En Windows, puedes usar el comandoipconfig /flushdns. En MacOS y Linux, puedes usardscacheutil -flushcacheosudo systemd-resolve --flush-caches. -
Temporalidad: Recuerda que los cambios en el archivo
hostsson locales a tu máquina y no afectan a otros usuarios o dispositivos.
Este método es muy útil para pruebas y verificaciones antes de realizar cambios en los registros DNS públicos.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Cambiar repositorios de Ubuntu al mirror de OVH
Objetivo
Actualizar los repositorios APT de Ubuntu para que utilicen el mirror de OVH:
- Mejora la velocidad y disponibilidad si el servidor está en OVH o cerca geográficamente
- Evita usar mirrors como
es.archive.ubuntu.comoarchive.ubuntu.com, que pueden tener latencias o caídas
Mirror recomendado para OVH el suyo propio
http://ubuntu.mirrors.ovh.net/ftp.ubuntu.com/ubuntu/
Sistemas con /etc/apt/sources.list (formato clásico)
Copia de seguridad
cp /etc/apt/sources.list /etc/apt/sources.list.bak
Sustitución automática del mirror
sed -i 's|http://.*\.archive\.ubuntu\.com/ubuntu|http://ubuntu.mirrors.ovh.net/ftp.ubuntu.com/ubuntu|g' /etc/apt/sources.list
sed -i 's|http://\([a-z]*\.\)\?archive\.ubuntu\.com/ubuntu|http://ubuntu.mirrors.ovh.net/ftp.ubuntu.com/ubuntu|g' /etc/apt/sources.list
- Cambia cualquier mirror genérico o regional por el de OVH
- Aplica a todas las entradas (main, security, updates, etc.)
Sistemas con /etc/apt/sources.list.d/ubuntu.sources (formato deb822)
Copia de seguridad
cp /etc/apt/sources.list.d/ubuntu.sources /etc/apt/sources.list.d/ubuntu.sources.bak
Sustitución automática del mirror
sed -i 's|URIs: http://.*\.archive\.ubuntu\.com/ubuntu|URIs: http://ubuntu.mirrors.ovh.net/ftp.ubuntu.com/ubuntu|g' /etc/apt/sources.list.d/ubuntu.sources
sed -i 's|URIs: http://security\.ubuntu\.com/ubuntu/|URIs: http://ubuntu.mirrors.ovh.net/ftp.ubuntu.com/ubuntu/|g' /etc/apt/sources.list.d/ubuntu.sources
- Cambia cualquier URI de mirror genérico o regional por el de OVH
- Aplica a todas las entradas del archivo formato deb822
Verificación
apt update
- Asegúrate de que todos los paquetes se descargan desde el mirror de OVH
- No deberían aparecer errores ni advertencias de conexión
Recomendaciones
- Este cambio puede repetirse en otros ficheros dentro de
/etc/apt/sources.list.d/ - En entornos con múltiples servidores, se recomienda automatizar la sustitución con:
- Scripts en bash
- Ansible
- Herramientas de orquestación o ejecución remota (como pssh)
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
## Guía Rápida de find - Búsquedas Avanzadas
🗂️ Buscar por Antigüedad
Archivos más antiguos que:
# Más de 1 año
find /directorio -type f -mtime +365
# Más de 1 mes (30 días)
find /directorio -type f -mtime +30
# Más de 1 semana
find /directorio -type f -mtime +7
# Más de 1 día
find /directorio -type f -mtime +1
Archivos modificados en los últimos:
# Últimas 24 horas
find /directorio -type f -mtime -1
# Últimos 7 días
find /directorio -type f -mtime -7
# Últimos 30 días
find /directorio -type f -mtime -30
Rango de fechas:
# Entre 7 y 30 días
find /directorio -type f -mtime +7 -mtime -30
# Entre 1 y 6 meses
find /directorio -type f -mtime +30 -mtime -180
📏 Buscar por Tamaño
Mayor que:
# Mayor que 100MB
find /directorio -type f -size +100M
# Mayor que 1GB
find /directorio -type f -size +1G
# Mayor que 10KB
find /directorio -type f -size +10k
Menor que:
# Menor que 1MB
find /directorio -type f -size -1M
# Menor que 100KB
find /directorio -type f -size -100k
Tamaño exacto:
# Exactamente 1MB
find /directorio -type f -size 1M
Rangos de tamaño:
# Entre 1MB y 10MB
find /directorio -type f -size +1M -size -10M
# Entre 100KB y 1MB
find /directorio -type f -size +100k -size -1M
🔄 Combinaciones Útiles
Archivos grandes y antiguos:
# Archivos > 100MB y > 1 año
find /directorio -type f -size +100M -mtime +365
# Archivos > 1GB y > 30 días
find /directorio -type f -size +1G -mtime +30
Con acciones:
# Listar con detalles
find /directorio -type f -size +100M -mtime +30 -ls
# Eliminar archivos (¡CUIDADO!)
find /directorio -type f -size +1G -mtime +365 -delete
# Listar tamaños legibles
find /directorio -type f -size +100M -exec ls -lh {} \;
📊 Unidades de Medida
| Unidad | Significado |
|---|---|
c |
bytes |
k |
KB (1024 bytes) |
M |
MB (1024 KB) |
G |
GB (1024 MB) |
⏰ Tipos de Tiempo
| Opción | Significado |
|---|---|
-mtime |
Modificación |
-atime |
Acceso |
-ctime |
Cambio de atributos |
💡 Ejemplos Prácticos
# Logs antiguos y grandes
find /var/log -name "*.log" -size +10M -mtime +7
# Archivos temporales antiguos
find /tmp -type f -mtime +1 -delete
# Archivos grandes en home
find /home -type f -size +500M -mtime +30 -ls
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
APT Upgrade - Modos Desatendido vs Manual
Problema común
Por defecto, apt upgrade -y se queda colgado esperando input cuando hay conflictos en archivos de configuración modificados, rompiendo la automatización en servidores. En situaciones de mantenimiento desatendido, es necesario obviarlo.
Tipos de preguntas en apt upgrade
1. Confirmación inicial (lista de paquetes)
The following packages will be upgraded:
zabbix-agent2 nginx mysql-server (y otros 25 paquetes)
Do you want to continue? [Y/n]
2. Conflictos de configuración (el problema real)
Configuration file '/etc/zabbix/zabbix_agent2.conf'
==> Modified (by you or by a script) since installation.
==> Package distributor has shipped an updated version.
What would you like to do about it ? Your options are:
Y or I : install the package maintainer's version
N or O : keep your currently-installed version
D : show the differences between the versions
Z : start a shell to examine the situation
Soluciones para upgrades desatendidos
Método 1: Opciones en línea de comandos (puntual)
# Mantener siempre la configuración actual (recomendado)
sudo apt -o Dpkg::Options::="--force-confold" upgrade -y
# Usar siempre la nueva configuración del paquete
sudo apt -o Dpkg::Options::="--force-confnew" upgrade -y
# Comando más completo (recomendado para scripts)
sudo DEBIAN_FRONTEND=noninteractive apt \
-o Dpkg::Options::="--force-confold" \
-o Dpkg::Options::="--force-confdef" \
upgrade -y
Cada uno de los métodos tiene su necesidad de entenderlo. La opcion usar la nueva configuración, puede ser muy problemática, pues por norma general, muchos o simplemenet algunos ficheros de configuración pueden estar modificados y su reseteo a la versión nueva, puede dejar el servicio inconsistente e incluso en algunos casos, perder la accesibilidad al servidor (sshd). El desatendido, en el que queremos conservar el fichero atcual, es lo más común, pero puede hacernos olvidar que a veces hay cambios que hay que aplicarlos. Vivimos tiempos de inmediatez, y de pocos recursos para administración de sistemas, y esto puede ser un problema.
Método 2: Configuración global permanente (recomendado)
# Crear archivo de configuración global
sudo tee /etc/apt/apt.conf.d/50unattended-upgrades << 'EOF'
Dpkg::Options {
"--force-confold";
"--force-confdef";
}
EOF
Resultado después de crear el archivo:
sudo apt upgrade -y→ Totalmente desatendidosudo apt upgrade→ Solo pregunta confirmación inicial, conflictos automáticos
Método 3: Variable de entorno (temporal)
# Para la sesión actual
export DEBIAN_FRONTEND=noninteractive
sudo -E apt upgrade -y
# Para un comando específico
sudo DEBIAN_FRONTEND=noninteractive apt upgrade -y
Opciones de dpkg explicadas
| Opción | Descripción | Equivale a presionar |
|---|---|---|
--force-confold |
Mantener configuración actual | N (No) |
--force-confnew |
Usar nueva configuración del paquete | Y (Yes) |
--force-confdef |
Usar respuesta por defecto si existe | Automático |
--force-confask |
Preguntar siempre (modo interactivo) | Pregunta manual |
--force-confmiss |
Instalar archivos de configuración faltantes | Automático |
Sobreescribir configuración global (uso manual)
Cuando tienes configuración global pero quieres control manual
# Desactivar todas las opciones automáticas (preguntará todo)
sudo apt -o Dpkg::Options::="" upgrade
# Forzar modo interactivo completo
sudo apt -o Dpkg::Options::="--force-confask" upgrade
# Usar nuevas configuraciones temporalmente
sudo apt -o Dpkg::Options::="--force-confnew" upgrade
# Modo interactivo con interfaz gráfica
sudo DEBIAN_FRONTEND=dialog apt upgrade
Para casos específicos
# Solo preguntar en conflictos (recomendado para revisión)
sudo apt -o Dpkg::Options::="--force-confask" -o Dpkg::Options::="--force-confdef" upgrade
# Mostrar diferencias antes de decidir
sudo apt -o Dpkg::Options::="--force-confask" upgrade
# (Luego presionar 'D' para ver diferencias)
Verificar configuración actual
# Ver toda la configuración de apt
apt-config dump
# Ver solo opciones de dpkg
apt-config dump | grep -i dpkg
# Ver archivos de configuración de apt
ls -la /etc/apt/apt.conf.d/
# Verificar contenido del archivo personalizado
cat /etc/apt/apt.conf.d/50unattended-upgrades
Casos de uso recomendados
Para servidores de producción
Conservará el fichero original
# Configuración global permanente (Método 2)
sudo tee /etc/apt/apt.conf.d/50unattended-upgrades << 'EOF'
Dpkg::Options {
"--force-confold";
"--force-confdef";
}
EOF
# Uso diario
sudo apt update && sudo apt upgrade -y
Para actualizaciones críticas o manuales
# Revisar manualmente cada conflicto
sudo apt -o Dpkg::Options::="--force-confask" upgrade
# Ver diferencias antes de decidir
# Presionar 'D' cuando aparezca el conflicto
Para scripts automatizados
#!/bin/bash
# Script de actualización desatendida
sudo DEBIAN_FRONTEND=noninteractive apt update
sudo DEBIAN_FRONTEND=noninteractive apt \
-o Dpkg::Options::="--force-confold" \
-o Dpkg::Options::="--force-confdef" \
upgrade -y
# Log de cambios
echo "Upgrade completed at $(date)" >> /var/log/auto-upgrade.log
Para desarrollo/testing
# Aplicar siempre nuevas configuraciones
sudo apt -o Dpkg::Options::="--force-confnew" upgrade -y
# O mantener configuraciones personalizadas
sudo apt -o Dpkg::Options::="--force-confold" upgrade -y
Comandos de emergencia
Si apt se cuelga durante upgrade
# En otra terminal/SSH
sudo killall apt apt-get dpkg
# Reparar estado de paquetes
sudo dpkg --configure -a
sudo apt --fix-broken install
Limpiar locks si es necesario
sudo rm /var/lib/dpkg/lock-frontend
sudo rm /var/cache/apt/archives/lock
sudo dpkg --configure -a
Configuración recomendada paso a paso
Instalación inicial (una sola vez)
# 1. Crear configuración global
sudo tee /etc/apt/apt.conf.d/50unattended-upgrades << 'EOF'
Dpkg::Options {
"--force-confold";
"--force-confdef";
}
EOF
# 2. Verificar que funciona
sudo apt update
apt-config dump | grep -i dpkg
Uso diario
# Actualización desatendida completa
sudo apt update && sudo apt upgrade -y
# Actualización con revisión manual ocasional
sudo apt update
sudo apt -o Dpkg::Options::="--force-confask" upgrade
Notas importantes
--force-confoldes la opción más segura para producción (mantiene tus configuraciones)--force-confnewpuede sobreescribir configuraciones importantes- Siempre hacer backup de configuraciones críticas antes de upgrades mayores
- La configuración global se aplica a todos los usuarios del sistema
- Puedes combinar opciones para casos específicos
- Las opciones de línea de comandos siempre sobreescriben la configuración global
Hacer backups regulares de /etc son altamente reomendables (como todos los backups o copias de respaldo)
Troubleshooting común
Problema: "dpkg was interrupted"
sudo dpkg --configure -a
sudo apt --fix-broken install
Problema: "Could not get lock"
sudo lsof /var/lib/dpkg/lock-frontend
sudo killall apt apt-get
sudo rm /var/lib/dpkg/lock-frontend
Problema: Paquetes retenidos (held back)
# Ver paquetes retenidos
apt list --upgradable
# Forzar actualización
sudo apt full-upgrade
Esta configuración te permitirá tener upgrades completamente automatizados por defecto, pero con la flexibilidad de tomar control manual cuando sea necesario.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Crear una unidad lógica con el 100%
A veces, voy con prisa. Se me olvida siempre.
lvcreate -n [NOMBRE] -l 100%FREE [NOMBRE_VOLUMEN_A_USAR]
mkfs.xfs /dev/[NOMBRE_VOLUMEN_A_USAR]/[NOMBRE]
blkid -s UUID -o value /dev/[NOMBRE_VOLUMEN_A_USAR]/[NOMBRE]
# editar fstab
# UUID=[UUID] /[PUNTO_DE_MONTAJE] xfs defaults,nofail 0 2
Búsqueda y reemplazo recursivo con sed en directorios
Contexto
Estrategias para localizar y modificar cadenas de texto en múltiples archivos de forma recursiva, con capacidad de filtrar por tipo de archivo y excluir líneas comentadas.
Escenario típico
- Necesidad de cambiar nombres de variables, funciones o constantes en toda una base de código
- Refactorización de nombres de configuración
- Migración de valores legacy a nuevas nomenclaturas
- Requiere precisión para no modificar comentarios ni código inactivo
Estrategias de búsqueda
1. Localización básica (análisis previo)
# Buscar en todos los archivos
find . -type f -exec grep -l "PATRON_BUSQUEDA" {} \;
# Con contexto (3 líneas antes y después)
find . -type f -exec grep -n -B3 -A3 "PATRON_BUSQUEDA" {} + | less
# Múltiples patrones (OR lógico)
find . -type f -exec grep -l "PATRON_1\|PATRON_2\|PATRON_3" {} \;
2. Filtrado por tipo de archivo
# Solo archivos con extensión específica
find . -type f -name "*.php" -exec grep -l "PATRON" {} \;
find . -type f -name "*.js" -exec grep -l "PATRON" {} \;
find . -type f -name "*.py" -exec grep -l "PATRON" {} \;
# Múltiples extensiones
find . -type f \( -name "*.php" -o -name "*.inc" \) -exec grep -l "PATRON" {} \;
# Excluir directorios específicos
find . -type f -name "*.php" -not -path "*/vendor/*" -not -path "*/node_modules/*" \
-exec grep -l "PATRON" {} \;
3. Análisis con numeración de líneas
# Ver archivo:línea:contenido
find . -type f -name "*.php" -exec grep -Hn "PATRON" {} \;
# Con AWK para formato personalizado
find . -type f -name "*.php" -exec awk '/PATRON/ {print FILENAME ":" NR ":" $0}' {} +
Estrategias de reemplazo
1. Reemplazo básico (SIN backup automático)
# Reemplazar en todos los archivos de un tipo
find . -type f -name "*.php" -exec sed -i 's/PATRON_VIEJO/PATRON_NUEVO/g' {} \;
# Múltiples reemplazos en una pasada
find . -type f -name "*.php" -exec sed -i '
s/PATRON_1/NUEVO_1/g
s/PATRON_2/NUEVO_2/g
s/PATRON_3/NUEVO_3/g
' {} \;
Nota: -i modifica archivos en sitio. En BSD/macOS usar sed -i ''
2. Reemplazo CON backup automático
# Crea archivo.php.bak antes de modificar
find . -type f -name "*.php" -exec sed -i.bak 's/PATRON_VIEJO/PATRON_NUEVO/g' {} \;
# Limpiar backups después de verificar
find . -type f -name "*.php.bak" -delete
3. Excluir líneas comentadas
PHP/JavaScript/C-style
# Excluir líneas que empiezan por #, //, /* o *
find . -type f -name "*.php" -exec sed -i.bak '/^\s*[#*\/]/! s/PATRON/NUEVO/g' {} \;
Desglose del patrón:
/^\s*[#*\/]/!→ Negación: aplica solo si NO cumple^\s*→ Inicio de línea con posibles espacios/tabs[#*\/]→ Caracteres de comentario:#,*,/!→ Negación lógica
Versión robusta (múltiples tipos de comentario)
find . -type f -name "*.php" -exec sed -i.bak '
/^\s*#/! {
/^\s*\/\//! {
/^\s*\/\*/! {
/^\s*\*/! {
s/PATRON_1/NUEVO_1/g
s/PATRON_2/NUEVO_2/g
}
}
}
}
' {} \;
Esto excluye:
# comentario estilo shell/Python// comentario estilo C++/JavaScript/* inicio de bloque comentario */* líneas dentro de bloque comentario
Python
# Excluir líneas que empiezan por #
find . -type f -name "*.py" -exec sed -i.bak '/^\s*#/! s/PATRON/NUEVO/g' {} \;
Shell scripts
# Excluir líneas que empiezan por #
find . -type f -name "*.sh" -exec sed -i.bak '/^\s*#/! s/PATRON/NUEVO/g' {} \;
4. Alternativa con Perl (más flexible)
# Perl permite regex más complejas
find . -type f -name "*.php" -exec perl -i.bak -pe '
s/PATRON_VIEJO/PATRON_NUEVO/g unless /^\s*[#*\/]/
' {} \;
# Múltiples patrones con hash de sustituciones
find . -type f -name "*.php" -exec perl -i.bak -pe '
BEGIN {
%replace = (
"PATRON_1" => "NUEVO_1",
"PATRON_2" => "NUEVO_2",
"PATRON_3" => "NUEVO_3"
);
}
unless (/^\s*[#*\/]/) {
s/$_/$replace{$_}/g for keys %replace;
}
' {} \;
Flujo de trabajo recomendado
# PASO 1: Análisis inicial (¿qué se va a cambiar?)
find . -type f -name "*.php" -exec grep -Hn "PATRON_VIEJO" {} \; | less
# PASO 2: Análisis excluyendo comentarios
find . -type f -name "*.php" -exec awk '
!/^\s*[#*\/]/ && /PATRON_VIEJO/ {
print FILENAME ":" NR ":" $0
}
' {} + | less
# PASO 3: Prueba en un solo archivo
sed -i.test '/^\s*[#*\/]/! s/PATRON_VIEJO/PATRON_NUEVO/g' ruta/archivo_prueba.php
diff ruta/archivo_prueba.php ruta/archivo_prueba.php.test
# PASO 4: Aplicar con backup (EJECUTAR)
find . -type f -name "*.php" -exec sed -i.bak '/^\s*[#*\/]/! s/PATRON_VIEJO/PATRON_NUEVO/g' {} \;
# PASO 5: Revisar cambios (si hay control de versiones)
git diff
git status
# PASO 6: Validar funcionamiento
# [Ejecutar tests, verificar aplicación]
# PASO 7: Limpiar backups si todo OK
find . -name "*.php.bak" -delete
Casos de uso comunes
Cambio de prefijo de base de datos
# MySQL/MariaDB: cambiar prefijo de tablas en dumps
find . -type f -name "*.sql" -exec sed -i.bak 's/prefijo_viejo_/prefijo_nuevo_/g' {} \;
Refactorización de nombres de clase
# PHP: cambiar nombre de clase
find . -type f -name "*.php" -exec sed -i.bak '/^\s*[#*\/]/! {
s/class OldClassName/class NewClassName/g
s/OldClassName::/NewClassName::/g
s/new OldClassName/new NewClassName/g
}' {} \;
Migración de configuración
# Cambiar nombres de constantes de configuración
find . -type f \( -name "*.php" -o -name "*.inc" \) -exec sed -i.bak '/^\s*[#*\/]/! {
s/OLD_CONFIG_NAME/NEW_CONFIG_NAME/g
s/OLD_DB_HOST/NEW_DB_HOST/g
s/OLD_API_KEY/NEW_API_KEY/g
}' {} \;
Actualización de rutas
# Cambiar rutas legacy
find . -type f -name "*.php" -exec sed -i.bak '/^\s*[#*\/]/! {
s|/var/www/old_path/|/var/www/new_path/|g
s|old-domain\.com|new-domain.com|g
}' {} \;
Limitaciones conocidas
1. Comentarios multilínea
El método basado en ^\s* solo detecta comentarios al inicio de línea. No detecta:
$var = "value"; /* comentario inline */ $otra = "PATRON"; // no se excluirá
Para estos casos, considerar un parser específico del lenguaje.
2. Cadenas literales
Si PATRON aparece dentro de strings, será reemplazado:
$sql = "SELECT * FROM old_table"; // se cambiará "old_table"
Para evitarlo se requiere análisis sintáctico completo.
3. Bloques multilínea
Comentarios que abarcan múltiples líneas:
/*
* Este es un comentario
* con PATRON_VIEJO que
* no será detectado en líneas 2-3
*/
Solo la primera línea (/*) se excluirá.
Alternativas avanzadas
Ripgrep (rg) + sd
# Búsqueda ultrarrápida
rg "PATRON" --type php
# Reemplazo con sd (más intuitivo que sed)
find . -name "*.php" -exec sd "PATRON_VIEJO" "PATRON_NUEVO" {} \;
Usando AG (The Silver Searcher)
# Listar archivos
ag -l "PATRON" --php
# Con contexto
ag "PATRON" --php -C 3
Scripts dedicados por lenguaje
Para refactorizaciones complejas, usar herramientas especializadas:
- PHP: PHP-CS-Fixer, Rector
- JavaScript: jscodeshift, lebab
- Python: rope, bowler
Verificación post-cambio
# Contar ocurrencias antes y después
echo "Antes:"
find . -name "*.php" -exec grep -o "PATRON_VIEJO" {} \; | wc -l
echo "Después:"
find . -name "*.php" -exec grep -o "PATRON_NUEVO" {} \; | wc -l
# Verificar que no quedan ocurrencias del patrón viejo
find . -name "*.php" -exec grep -H "PATRON_VIEJO" {} \;
# Si hay control de versiones
git diff --stat
git diff | grep -E "^\+.*PATRON_NUEVO" | wc -l
Consejos de seguridad
- Siempre hacer backup antes de modificaciones masivas
- Usar control de versiones (git commit antes de ejecutar)
- Probar en un archivo antes de aplicar a todo el proyecto
- Revisar diff completo antes de commit final
- Ejecutar suite de tests después de cambios
- Considerar crear rama temporal para refactorizaciones grandes
Troubleshooting
"Device or resource busy"
# Puede ocurrir con archivos abiertos. Solución: cerrar editores
lsof | grep nombre_archivo
"Permission denied"
# Verificar permisos
find . -type f -name "*.php" ! -writable
# Corregir si es necesario
find . -type f -name "*.php" -exec chmod u+w {} \;
Sed no modifica archivos
# Verificar sintaxis específica del sistema
sed --version # GNU sed
sed -i.bak ... # funciona en GNU
# En macOS/BSD
sed -i '' ... # requiere argumento vacío
Última actualización: Octubre 2025
Compatibilidad: Linux (GNU sed), *BSD/macOS (requiere ajustes en -i)
Herramientas: find, sed, grep, awk, perl
Instalación de Node.js LTS 22 y npm en Ubuntu con CloudLinux CageFS
Contexto
Guía para instalar Node.js 22 LTS en Ubuntu cuando el servidor utiliza CloudLinux con CageFS. La documentación oficial de CloudLinux está orientada a RPM, pero este proceso está validado para sistemas Debian/Ubuntu.
Prerequisitos
- Ubuntu (validado en versiones 20.04+)
- CloudLinux con CageFS activo
- Acceso root
- Usuario con configuración mysql/mariadb ya tuneada (socket o .my.cnf)
Parte 1: Instalación base de Node.js
1. Verificar estado actual (opcional)
# Ver si ya tienes Node instalado
node --version
npm --version
# Ver repositorios de Node configurados
grep -r "nodesource" /etc/apt/sources.list.d/
2. Limpiar instalaciones previas (si existen)
# Eliminar repositorios antiguos de NodeSource
sudo rm -f /etc/apt/sources.list.d/nodesource.list
sudo rm -f /etc/apt/keyrings/nodesource.gpg
# Eliminar versiones antiguas
sudo apt remove nodejs npm -y
sudo apt autoremove -y
3. Instalar Node.js 22 LTS desde NodeSource
# Descargar e instalar el script de setup oficial
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
# Instalar Node.js (incluye npm automáticamente)
sudo apt install -y nodejs
# Verificar instalación en sistema base
node --version # Debería mostrar v22.x.x
npm --version # Debería mostrar 10.x.x
4. Instalar herramientas de compilación
# Necesarias para compilar módulos nativos de npm
sudo apt install -y build-essential
Parte 2: Integración con CloudLinux CageFS
Contexto de CageFS
CageFS crea un sistema de archivos virtualizado para cada usuario, aislándolos del sistema real. Los binarios instalados en el sistema base no son visibles automáticamente dentro de las jaulas de los usuarios.
5. Registrar Node.js en CageFS
# Añadir nodejs como paquete conocido por CageFS
# Esto le indica a CageFS que debe copiar estos binarios al skeleton
cagefsctl --addrpm nodejs
Nota: El parámetro --addrpm funciona correctamente en Ubuntu aunque el nombre sugiera RPM. CageFS detecta automáticamente el gestor de paquetes del sistema.
6. Actualizar el skeleton de CageFS
# Forzar actualización del skeleton (estructura base de las jaulas)
cagefsctl --force-update
Salida esperada:
Copying /usr/bin/node to /usr/share/cagefs-skeleton/usr/bin/node
Creating symlink /usr/share/cagefs-skeleton/usr/bin/corepack to ../lib/node_modules/corepack/dist/corepack.js
Creating symlink /usr/share/cagefs-skeleton/usr/bin/npm to ../lib/node_modules/npm/bin/npm-cli.js
Creating symlink /usr/share/cagefs-skeleton/usr/bin/npx to ../lib/node_modules/npm/bin/npx-cli.js
Updating users ...
Updating user user1 ...
Updating user user2 ...
Updating user user3 ...
Qué hace este comando
- Copia binarios:
/usr/bin/node→/usr/share/cagefs-skeleton/usr/bin/node - Crea symlinks: npm, npx, corepack dentro del skeleton
- Actualiza jaulas: Propaga los cambios a todos los usuarios enjaulados
- Preserva aislamiento: Cada usuario ve su propia copia independiente
Verificación
7. Probar en usuario enjaulado
# Cambiar a un usuario con CageFS activo
su - user1
# Verificar disponibilidad de Node.js
node -v
# Output esperado: v22.11.0 (o versión actual de la rama 22.x)
npm -v
# Output esperado: 10.9.0 (o superior)
# Verificar ubicación (dentro de la jaula)
which node
# Output esperado: /usr/bin/node
8. Verificación adicional desde root
# Ver qué binarios están en el skeleton
ls -la /usr/share/cagefs-skeleton/usr/bin/ | grep node
# Verificar symlinks
ls -la /usr/share/cagefs-skeleton/usr/bin/{npm,npx,corepack}
# Ver usuarios con CageFS activo
cagefsctl --list-enabled
Troubleshooting
Node no visible dentro de CageFS
# Verificar que el usuario tiene CageFS activo
cagefsctl --user user1
# Forzar actualización de un usuario específico
cagefsctl --force-update-user user1
# Reinicializar completamente CageFS (último recurso)
cagefsctl --reinit
Permisos incorrectos
# Verificar permisos del binario en skeleton
ls -la /usr/share/cagefs-skeleton/usr/bin/node
# Debería ser ejecutable (755 o similar)
# Si no lo es:
chmod 755 /usr/share/cagefs-skeleton/usr/bin/node
cagefsctl --force-update
Actualización de Node.js
# Cuando NodeSource publique una nueva versión 22.x
sudo apt update
sudo apt upgrade nodejs
# IMPORTANTE: Después de actualizar, regenerar skeleton
cagefsctl --force-update
Diferencias Ubuntu vs CentOS/RPM
| Aspecto | Ubuntu (DEB) | CentOS (RPM) |
|---|---|---|
| Instalación | apt + NodeSource | yum/dnf + NodeSource |
| Comando CageFS | Mismo (--addrpm funciona) |
Mismo |
| Ubicación binarios | /usr/bin/node |
/usr/bin/node |
| Documentación oficial | Escasa para DEB | Abundante para RPM |
| Funcionamiento | Idéntico una vez instalado | Idéntico |
Notas importantes
- Node 22 LTS tiene soporte hasta abril 2027
- npm viene incluido con Node.js
- CageFS es transparente para el usuario final
- Actualizaciones automáticas: NodeSource mantiene la rama 22.x
- Sin sudo para usuarios: Los usuarios no necesitan permisos especiales
- Aislamiento preservado: Cada usuario ve su propia instancia
Resultado esperado
- ✅ Node.js disponible en sistema base
- ✅ Node.js disponible dentro de todas las jaulas CageFS
- ✅ npm y npx funcionales para todos los usuarios
- ✅ Actualizaciones automáticas del sistema afectan a todas las jaulas
Comandos de verificación rápida
# Desde root
node --version && npm --version
# Desde usuario enjaulado
su - user1 -c "node --version && npm --version"
# Listar paquetes registrados en CageFS
cagefsctl --list-packages | grep node
Validado en: Ubuntu 22.04 LTS con CloudLinux + CageFS
Fecha: Octubre 2025
Node.js: v22.11.0 LTS (Iron)
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
PHP
PHP es indispensable para un servidor con capacidades Web. Pero existen muchas variantes de como configurar PHP para ser usado en con un servidor web.
PHP log cuando usamos PHP-FPM con host virtuales
Introducción
Uno de esos tips que está infravalorado. Podremos ver, decenas de páginas, y cientos de respuestas, en las que todos hablan de cómo configurar el log, de si el path es incorrecto, o de si estas en linux o en windows. Al final el tema está en otro lugar, pues muchos de ellos, contestan si ni siquiera saber qué es PHP-FPM o cuando menos, sin verificar los que dicen que hace lo que escriben.
Problema
En una instalación estándar de PHP-FPM en sistemas Linux, es posible que los errores de PHP no se registren correctamente en los logs de los dominios virtuales. Esto dificulta enormemente la depuración de problemas, ya que los mensajes de error críticos pueden perderse o no quedar registrados en los archivos de log esperados.
Causa
Por defecto, PHP-FPM captura la salida estándar y de error de los workers (procesos de trabajo), pero no la redirige automáticamente a los logs. La directiva catch_workers_output está configurada como no en la configuración predeterminada, no existir o están simplemente comentada, lo que impide que los errores generados por los scripts PHP se registren adecuadamente.
Solución
Para resolver este problema, es necesario modificar el archivo de configuración del pool de PHP-FPM:
-
Abrir el archivo de configuración del pool (normalmente ubicado en
/etc/php/X.X/fpm/pool.d/www.conf, donde X.X es la versión de PHP, por ejemplo 7.4, 8.0, 8.1, etc.) -
Buscar la directiva
catch_workers_output -
Cambiar su valor de
noayes:catch_workers_output = yes -
Guardar el archivo y reiniciar el servicio PHP-FPM:
sudo systemctl restart php7.4-fpm.service # Ajustar según la versión de PHP
Explicación técnica
Cuando catch_workers_output = yes está activado, PHP-FPM captura la salida de los procesos worker y la redirige adecuadamente al sistema de logs. Esto asegura que:
- Los errores de PHP aparezcan en los logs específicos del dominio virtual
- Los mensajes críticos no se pierdan
- Sea más fácil identificar y solucionar problemas en aplicaciones PHP
Consideraciones adicionales
En versiones más recientes de PHP-FPM (7.3+), se recomienda usar las siguientes directivas en lugar de catch_workers_output:
php_admin_flag[log_errors] = on
php_admin_value[error_log] = /ruta/a/error.log
Estas opciones ofrecen un mejor rendimiento y mayor control sobre el destino de los logs.
Importancia
Configurar correctamente los logs de error es un paso crucial para:
- Facilitar la depuración de aplicaciones
- Detectar problemas de seguridad
- Monitorizar el rendimiento del servidor
- Cumplir con buenas prácticas de administración de sistemas
Sin esta configuración, podrías estar operando tus aplicaciones PHP "a ciegas", sin visibilidad sobre los errores que ocurren.
Otros enlaces
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
PHP. Como instalar una nueva versión de PHP en un sistema basado DEB
PHP. Como instalar una nueva versión de PHP en un sistema DEB basado
Lo habitual en mis máquinas es tener varias versiones de PHP usando el paquete de XXXXXX. Cuando sale una nueva versión suelo clonar la configuración de módulos, ya que a fin de cuentas luego será la nueva versión en los sitios cuando los actualice y verifique que pueden usar la nuevas version de PHP:
Proceso de clonado de PHP a otra versión
### Obtener la lista de paquetes de la versión actual
Para obtener la lista de todos los paquetes de PHP 8.2 instalados en tu sistema Debian (Raspberry Pi), puedes usar dpkg con grep:
dpkg -l | grep php8.2 | awk '{print $2}' > php8.2-packages.txt
Esto creará un archivo php8.2-packages.txt que contiene todos los paquetes instalados relacionados con PHP 8.2.
Crear un fichero con los nombres de paquete actualizados a la nueva versión
Ahora, necesitas cambiar 'php8.2' por 'php8.3' en todos los nombres de los paquetes para preparar la instalación de la nueva versión. Puedes hacerlo con sed:
sed 's/php8.2/php8.3/g' php8.2-packages.txt > php8.3-packages.txt
Esto generará un nuevo archivo php8.3-packages.txt con los nombres de los paquetes modificados para PHP 8.3.
Script para instalar los paquetes de PHP 8.3
Ahora puedes crear un script que lea el archivo php8.3-packages.txt y use apt para instalar cada paquete. Aquí tienes un ejemplo de cómo podría ser este script:
#!/bin/bash
# Asegúrate de que el script se ejecute con privilegios de superusuario
if [ "$(id -u)" != "0" ]; then
echo "Este script debe ser ejecutado como root" 1>&2
exit 1
fi
# Actualiza los repositorios e instala los paquetes
apt update
while read package; do
apt install -y $package
done < php8.3-packages.txt
Guarda este script como upgrade_to_php8.3.sh, por ejemplo.
Ejecutar el script
Antes de ejecutar el script, asegúrate de que es ejecutable:
chmod +x upgrade_to_php8.3.sh
Luego, ejecútalo como root o utilizando sudo:
sudo ./upgrade_to_php8.3.sh
Este script actualizará tus paquetes a la versión 8.3 de PHP, asegurándose de mantener las mismas extensiones y configuraciones que tenías para la versión 8.2.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Activar PHP8.2 JIT Compiler - Just-In-Time compilation (JIT)
PHP8.2 JIT Compiler
Los lenguajes de programación puramente interpretados no tienen una fase de compilación y ejecutan directamente el código en una máquina virtual. La mayoría de los lenguajes interpretados, incluyendo PHP, de hecho, tienen una ligera fase de compilación para mejorar su rendimiento.
Por otro lado, los lenguajes de programación con compilación anticipada (AOT) requieren que el código sea compilado antes de su ejecución.
La compilación Just-In-Time (JIT) es un modelo híbrido entre el intérprete y la compilación anticipada, donde parte o todo el código se compila, a menudo en tiempo de ejecución, sin que el desarrollador tenga que compilarlo manualmente.
Históricamente, PHP fue un lenguaje interpretado, donde todo el código era interpretado por una máquina virtual (Zend VM). Esto cambió con la introducción de Opcache y los Opcodes, que se generaban a partir del código PHP y podían ser almacenados en memoria caché. PHP 7.0 introdujo el concepto de AST (Árbol de Sintaxis Abstracta), que separó aún más el analizador sintáctico del compilador.
El JIT de PHP utiliza internamente DynASM de LuaJIT y está implementado como parte del Opcache.
El uso de JIT en PHP es altamente recomendable, no solo para propósito general, sino más aun, es aconsejable producir código de acuerdo a los cambios implementado desde PHP 8.0 que van mucho más allá de la activación de una forma de procesar en el servidor.
En particular lo uso en mis servidores en los que hago despliegues con Laravel y francamente, es impresionante.
Activarlo en el servidor
En un servidor con PHP, en múltiples versiones, y con el modo FPM entre otros como uso con el servidor Web, y como ejemplo una Ubuntu, debemos activar JIT que por defecto no esta activado.
Encontraremos sus variables disponibles en el fichero php.ini de la versión en la que queremos activar JIT, pero como consejo, es mejor no hacerlo ahí.
En su lugar debemos hacerlo en /etc/php/8.2/mods-available/ ya que es ahí donde están los ficheros parciales de cada modulo, y su configuración, tanto para PHP-FPM, como para PHP en modo cli.
Esta es una buena práctica que existe en Ubuntu y otras distribuciones de Linux.
El fichero en cuestión es /etc/php/8.2/mods-available/opcache.ini y contiene por defecto. Esto no activará JIT sino que lo cargará pero lo mostrará apagado, por ejemplo usando phpinfo()
; configuration for php opcache module
; priority=10
zend_extension=opcache.so
Si cambias los valores en el
php.inigeneral es probable que todo este activado menos el parJIT On
Configuración ejemplo
Bien, os dejo una configuración bastante funcional en un sistema con uso muy intensivo tanto de php vía colas de Laravel usando php-cli y vía API externa en producción.
Las mejoras son de 8,2 segundos en operaciones intensas a solo 1,2s.
zend_extension=opcache.so
opcache.jit=on
opcache.interned_strings_buffer=8
opcache.max_accelerated_files=10000
opcache.max_wasted_percentage=5
opcache.validate_timestamps=1
opcache.revalidate_freq=2
opcache.jit_buffer_size=100M
opcache.jit=tracing
opcache.jit=1255
opcache.save_comments=0
opcache.file_cache=/var/cache/php/opcache
Tras el reinicio de PHP-FPM verás algo parecido a esto:
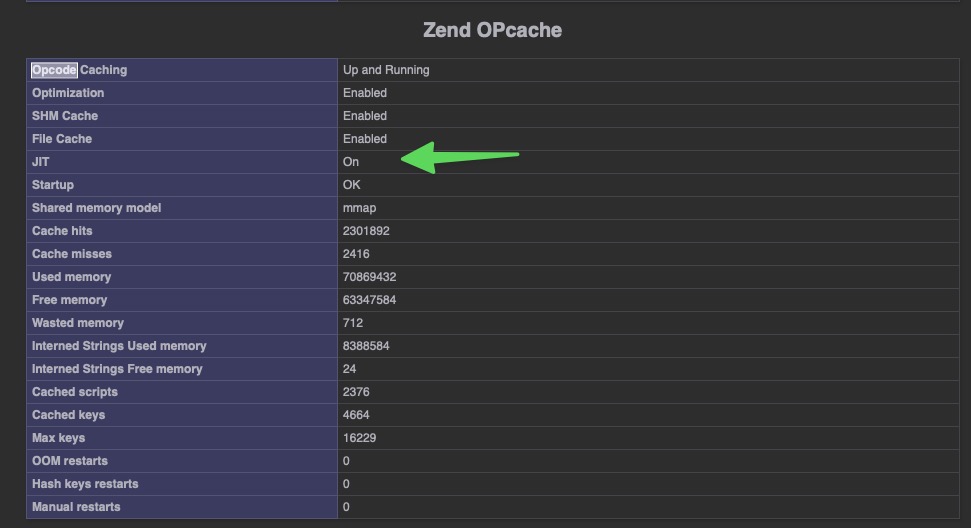
Esta configuración
opcache.file_cacherequiere que exista/var/cache/php/opcachepara servir de segundo nivel de cache (o el que tu definas), y que tenga los permisos para el ejecutor. En algunos sitios veo de usarwww-dataque es el que usa en una Ubuntu con Nginx. Puedes dejarlo vacío, si eres generoso con la memoriza asignada. En realidad, es algo así como el swap en linux.
Te aconsejo una vuelta por el fichero php.ini principal, para que veas todos los comentarios de cada uno delos valores. Ya sabes, el copia y pega, puede ser fatal, pues lo que a mi me funciona puede que a ti no.
Enlaces
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Instalar una versión de PHP con módulos en Ubuntu con Ondrej copiando de otra versión ya instalada
Introducción
Un sistema rápido para clonar, por asi decirlo, la instalación actual de PHP en modo PHP-FPM con el repositorio Ondřej Surý
En este caso vamos a describir el instala la 8.0 teniendo una 8.2 instalada
Paso 1: Obtener la Lista de Paquetes de PHP 8.2
-
Listar los Paquetes de PHP 8.2 Instalados:
-
Usa el siguiente comando para listar los paquetes de PHP 8.2 y guardarlos en un archivo de texto:
dpkg -l | grep php8.2 | awk '{print $2}' > php8.2-packages.txt -
Esto creará un archivo
php8.2-packages.txtcon los nombres de los paquetes instalados.
-
Paso 2: Modificar la Lista para PHP 8.0
-
Modificar el Archivo para Usar PHP 8.0:
-
Usa
sedpara reemplazarphp8.2porphp8.0en el archivo:sed 's/php8.2/php8.0/g' php8.2-packages.txt > php8.0-packages.txt -
Ahora tendrás un archivo
php8.0-packages.txtcon los nombres de los paquetes que necesitas instalar para PHP 8.0.
-
Paso 3: Instalar los Paquetes de PHP 8.0
-
Instalar los Paquetes Usando el Archivo:
-
Usa el siguiente comando para instalar todos los paquetes listados en
php8.0-packages.txt:sudo xargs -a php8.0-packages.txt apt-get install -y -
Este comando usará
xargspara pasar cada paquete listado en el archivo al comandoapt-get install.
-
Consideraciones Adicionales
- Verificar la Instalación: Después de la instalación, verifica que PHP 8.0 y sus módulos estén correctamente instalados y configurados.
- Dependencias Adicionales: Algunos módulos pueden requerir dependencias adicionales que no estén cubiertas por los paquetes listados. Asegúrate de revisar cualquier mensaje de error durante la instalación.
Siguiendo estos pasos, podrás automatizar el proceso de instalación de PHP 8.0 y sus módulos basándote en los paquetes de PHP 8.2 que ya tienes instalados.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Proxmox
Cosas sobre Proxmox
Git pull, error: server certificate verification failed. CAfile: none CRLfile: none
Introducción
El problema me apareció en un proxmox desactualizado, cuando quise hacer un pull de mis utilidades.
git pull fatal: unable to access 'https://*****.castris.com/root/utilidades.git/': server certificate verification failed. CAfile: none CRLfile: none
Tras verificar que el problema no estaba del lado de mi gitlab, sospeche de la desactualización de Proxmox. Como nunca actualizo un Proxmox, ya la solución de actualizar sólo los ca-certificates y paquetes relacionados, no funcionó opte por una tip rápido.
No actualizo los proxmox, porque desde la versión 3, que ya son años, he tenido 4 incidentes de actualización, con sus correspondientes problemas derivados. Así que prefiero hacer un un turn-over en mi proveedor, coger una máquina nueva cada dos o tres años, y dejarme de tonterías. Atención, a mis máquinas proxmox no se acceden sino es desde mis ips, otra imposición que me puse dado que he visto muchos proxmox hackeados vía web. Así que al estar capado, no tengo miedo a no "actualizar"
Modificación de Git para no verificar ssl
root@pro12:~/utilidades# git config --global http.sslverify false
root@pro12:~/utilidades# git pull
remote: Enumerating objects: 23, done.
remote: Counting objects: 100% (23/23), done.
remote: Compressing objects: 100% (14/14), done.
remote: Total 18 (delta 9), reused 12 (delta 4), pack-reused 0
Unpacking objects: 100% (18/18), done.
From https://gitlab.castris.com/root/utilidades
10bda88..c93d331 master -> origin/master
Updating 10bda88..c93d331
Fast-forward
.gitignore | 2 +
actualiza.sh | 2 +-
basura.sh | 4 +
compress-dovecot.sh | 164 ++++++++++
csf/proxmox.csf.conf | 2678 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
fixpermisions.sh | 164 ++++++++++
6 files changed, 3013 insertions(+), 1 deletion(-)
create mode 100644 compress-dovecot.sh
create mode 100644 csf/proxmox.csf.conf
create mode 100644 fixpermisions.sh
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
[PRIV] Instalar Proxmox desde 0
OVH
Seguridad
mkdir /root/soft;cd /root/soft/; wget https://download.configserver.com/csf.tgz; tar xvfz csf.tgz; cd csf; sh install.sh; cd ..; rm -Rf csf/ csf.tgz; \
echo '.cpanel.net
.googlebot.com
.crawl.yahoo.net
.search.msn.com
.paypal.com
.paypal.es' > /etc/csf/csf.rignore;\
wget -O /etc/csf/csf.conf https://gitlab.castris.com/root/utilidades/-/raw/main/csf/proxmox.csf.conf; \
wget -O /etc/csf/csf.blocklists https://gitlab.castris.com/root/utilidades/-/raw/main/csf/csf.blocklists; \
wget -O /etc/csf/csf.allow ttps://gitlab.castris.com/root/utilidades/-/raw/main/csf/csf.allow; \
wget -O /etc/csf/csf.dyndns https://gitlab.castris.com/root/utilidades/-/raw/main/csf/csf.dyndns
Discos
Utilidades
cd ~ && git clone https://gitlab.castris.com/root/utilidades.git
Red
zabbix
Discos remotos
LVM Práctico para Proxmox y OVH
Introducción
Es un tip que uso para mis necesidades. Entre otras, no uso ZSF por la carga que supone para el sistema, y porque suplo sus bondades por decisión propia con otros mecanismo de salvaguarda.
Cada modelo de máquina de OVH y cada instalación deja diferencias sutiles que pueden hacer que uno tenga que modificar los datos de particiones, discos, interfaces de red.
LVM
En una instalación sin uso de RAID por software del instalador tenemos en la versión del instalador de OVH que instala 7.2-14 de Proxmox un volumen llamado vg en el disco primario
pvs
PV VG Fmt Attr PSize PFree
/dev/nvme0n1p5 vg lvm2 a-- 1.72t 0
lvscan
ACTIVE '/dev/vg/data' [1.72 TiB] inherit
Sobre el cual ha creado un volume llamado vg y un volumen lógico llamado data con el tamaño máximo
Mal por todo, porque asigna todo el espacio y no permite hacer snapshots.
Este modelo no me sirve pues yo nunca uso virtualización por OpenVZ así que hay que eliminar y reconstruir
Copia de la partición
Parada de proxmox
AVISO IMPORTANTE — Proxmox VE 7 y posteriores
/etc/pvees un sistema de ficheros FUSE (pmxcfs) montado porpve-cluster.service. Al pararpve-clusterse desmonta/etc/pveentero, lo que rompe/root/.ssh/authorized_keys— que es un symlink a/etc/pve/priv/authorized_keys. Resultado: sshd deja de aceptar tu clave pública y pierdes el acceso remoto hasta arrancarpve-clusterde nuevo.Para tocar
/var/lib/vz(lo que hace este tip) NO es necesario pararpve-cluster. Basta conpvedaemonypveproxy. Mantenerpve-clusterarriba preserva el acceso SSH durante toda la operación.
Versiones anteriores a la 7
systemctl stop pve-cluster pvedaemon pveproxy pvestatsd
Versiones 7 / 8 / 9 (recomendado)
systemctl stop pvedaemon pveproxy
Si por algún motivo necesitas parar también pve-cluster (raro), hazlo dentro de un único batch que lo levante antes de terminar, y no te desconectes de la sesión SSH viva mientras esté parado:
systemctl stop pve-cluster pvedaemon pveproxy
# ... operaciones rápidas sobre /var/lib/vz ...
systemctl start pve-cluster pvedaemon pveproxy
Copia de /var/lib/vz
mkdir /old_vz
rsync -avv --progress /var/lib/vz/ /old_vz/
umount /var/lib/vz
Debemos por seguridad editar /etc/fstab para eliminar o comentar el punto de montaje de /var/lib/vz/ por si ocurriera algún reinicio por despiste
Eliminación del volumen
lvchange -an /dev/vg/data
lvremove /dev/vg/data
Logical volume "data" successfully removed
Creación de un volumen menor
Por si acaso, un dia queremos una instancia tipo OpenVZ crearemos un volumen lógico pequeño pero suficiente para que esté ahí, por si un día lo queremos usar.
lvcreate -n data --size 20GB vg
WARNING: ext4 signature detected on /dev/vg/data at offset 1080. Wipe it? [y/n]: y
Wiping ext4 signature on /dev/vg/data.
Logical volume "data" created.
pvscan
PV /dev/nvme0n1p5 VG vg lvm2 [1.72 TiB / <1.71 TiB free]
Total: 1 [1.72 TiB] / in use: 1 [1.72 TiB] / in no VG: 0 [0 ]
mkfs.xfs /dev/vg/data
meta-data=/dev/vg/data isize=512 agcount=16, agsize=327680 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=0
data = bsize=4096 blocks=5242880, imaxpct=25
= sunit=32 swidth=32 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Discarding blocks...Done.
Obtención del UUID
blkid
…
/dev/mapper/vg-data: UUID="c0ede30d-f8a6-4897-a392-39c9dfc542a6" BLOCK_SIZE="4096" TYPE="xfs"
Edición de fstab
UUID=c0ede30d-f8a6-4897-a392-39c9dfc542a6 /var/lib/vz xfs defaults 0 0
Restauración de ficheros del directorio
rsync -avv --progress /old_vz/ /var/lib/vz/
systemctl restart pve-cluster pvedaemon pveproxy pvestatsd
Creación de volúmenes LVM
En mi caso, y en este en particular, no deseo ampliar el volumen, sino que prefiero tener 3 volúmenes independientes, por el tipo de máquina que uso y el uso que se va a dar, ya que la velocidad y cargas en el proceso, me son más interesante con 3 volúmenes, que con uno, a la par que la posibilidad de una rotura de LVM es mayor y un riesgo que llevo años sin querer sufrirlo (que alguna vez lo he sufrido) y en los últimos 8 años, no he tenido ningún percance con varias máquinas con este aprovechamiento.
Reconocimiento de discos
fdisk -l
Disk /dev/nvme1n1: 1.75 TiB, 1920383410176 bytes, 3750748848 sectors
Disk model: SAMSUNG MZQL21T9HCJR-00A07
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 131072 bytes / 131072 bytes
Disk /dev/nvme2n1: 1.75 TiB, 1920383410176 bytes, 3750748848 sectors
Disk model: SAMSUNG MZQL21T9HCJR-00A07
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 131072 bytes / 131072 bytes
Disk /dev/nvme0n1: 1.75 TiB, 1920383410176 bytes, 3750748848 sectors
Disk model: SAMSUNG MZQL21T9HCJR-00A07
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 131072 bytes / 131072 bytes
Disklabel type: gpt
Disk identifier: 991EADF9-826A-4A35-B37C-5A1C3D255A5D
Device Start End Sectors Size Type
/dev/nvme0n1p1 2048 1048575 1046528 511M EFI System
/dev/nvme0n1p2 1048576 3145727 2097152 1G Linux filesystem
/dev/nvme0n1p3 3145728 45088767 41943040 20G Linux filesystem
/dev/nvme0n1p4 45088768 47185919 2097152 1G Linux filesystem
/dev/nvme0n1p5 47185920 3750739967 3703554048 1.7T Linux LVM
/dev/nvme0n1p6 3750744752 3750748814 4063 2M Linux filesystem
Partition 6 does not start on physical sector boundary. // No importante
Disk /dev/mapper/vg-data: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 131072 bytes / 131072 bytes
Tenemos pues los discos nvme1n1y nvme2n1 disponibles
Creación de los grupos de volúmenes
Como uso una dinámica de nombres para así hacer más fácil las migraciones entre máquinas Proxmox, haré lo mismo.
Es importante crear los volúmenes de almacenamiento en particiones y no sobre el disco completo.
Partición
Usare mi Parted mejor que fdisk
Creamos las etiquetas
parted -s /dev/nvme1n1 mklabel gpt
parted -s /dev/nvme2n1 mklabel gpt
Creamos las particiones
parted -s /dev/nvme1n1 mkpart primary 0% 100%
parted -s /dev/nvme2n1 mkpart primary 0% 100%
Creación de los volúmenes
vgcreate lvm /dev/nvme1n1p1
Physical volume "/dev/nvme1n1p1" successfully created.
Volume group "lvm" successfully created
vgcreate lvm2 /dev/nvme2n1p1
Physical volume "/dev/nvme2n1p1" successfully created.
Volume group "lvm2" successfully created
pvscan
PV /dev/nvme1n1p1 VG lvm lvm2 [<1.75 TiB / <1.75 TiB free]
PV /dev/nvme2n1p1 VG lvm2 lvm2 [<1.75 TiB / <1.75 TiB free]
PV /dev/nvme0n1p5 VG vg lvm2 [1.72 TiB / <1.71 TiB free]
Total: 3 [<5.22 TiB] / in use: 3 [<5.22 TiB] / in no VG: 0 [0 ]
Final
A partir de aquí, ya tenemos nuestra estructura deseada en LVM para Proxmox.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Red OVH vrack para Proxmox 7
Introducción
El artículo es para un escenario de uso del vrack de OVH en un escenario específico. El alcance es dejar un tip, que uso muy a menudo, y en el que pongo énfasis en poder utilizar asegurándome de que si algo falla, puedo volver atrás con facilidad.
Configurar la red para OVH Rack con Proxmox 7
Copiar configuracion original
rsync -avv /etc/network/interfaces /root/interfaces.bak
Editar la configuración
Editamos la interface que puede ser diferente en cada caso pues con el tiempo cambian, y con los modelos de OVH cambian su forma de conexión a OVH
Es importante entender que hay dos interfaces de red y que esas son las que debemos configurar para usar vrack.
El modelo que uso, es particular, para mis necesidades. Hay muchas formas de configurar la red con vrack dependiendo de que estemos desplegando en nuestra máquina Proxmox y la red que queremos.
auto lo
iface lo inet loopback
iface eno1 inet manual
#auto vmbr0
#iface vmbr0 inet static
# address IP.IP.IP.2/24
# gateway IP.IP.IP.254
# bridge-ports eno1
# bridge-stp off
# bridge-fd 0
# hwaddress XX:XX:XX:XX:XX:XX
# nuevo modelo OVH DHCP
auto vmbr0
iface vmbr0 inet dhcp
address IP.IP.IP.IP/24
gateway IP.IP.IP.254
bridge-ports eno1
bridge-stp off
bridge-fd 0
# for routing
auto vmbr1
iface vmbr1 inet manual
bridge_ports dummy0
bridge_stp off
bridge_fd 0
# Bridge vrack 1.5
auto vmbr2
iface vmbr2 inet manual
bridge_ports eno2
bridge_stp off
bridge_fd 0
Un consejo por si hay que reiniciar y usar el IPMI para arreglarlo si la cosa no ha funcionado. Cambiar la contraseña por una sin signos ya que el IPMI no es precisamente amigable con los teclados nacionales.
Reinicio
Hacemos un shutdown de la máquina, y ya tendríamos nuestra red con vrack instalada.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Como arreglar el error Sender address rejected: need fully-qualified address (in reply to RCPT TO command)
Introducción
Algunas veces tenemos hosts (máquinas) de servicio, como Proxmox, en las que las peculiaridades y operativas, nos dejan con ciertos problemas de envío de correo, como los enviados por root (alertas, etc) que son enviados con el nombre corto de hosten lugar del FQDN. Están configurados con Postfix, y el servidor remoto, no permite este tipo de envío de correos (normal) por lo que debemos hacer un mapping en el servidor que está enviando los correos con el hostname corto.
Jan 29 00:00:19 smtp postfix/smtpd[389410]: NOQUEUE: reject: RCPT from pro18.XXX.XXX[Z.Z.Z.Z]: 504 5.5.2 <root@pro18>: Sender address rejected: need fully-qualified address; from=<root@pro18> to=<sistemas@mydomain.com> proto=ESMTP helo=<pro18.XXX.XXX>
Solución
Crear el fichero /etc/postfix/canonical
@local @pro18.mydomain.tld
@pro18 @pro18.mydomain.tld
Añadir la referencia a este fichero de hash
canonical_maps = hash:/etc/postfix/canonical
Activar el fichero de hash
postmap /etc/postfix/canonical
service postfix restart
Documentación
Postfix :: Canonical address mapping
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Proxmox, Hetzner, y bloques de Ips adicionales en modo Routed
Introducción
Tra una experiencia desastrosa con el proveedor Scaleway y su sistema Elastic Metal decidí que lo mejor era marcharme. Dado que lo único que me queda allí, era una máquina de Proxmox con failover de máquinas en #OVH, revise los requerimientos de tráfico (Hetzner te da solo 20 TB de tráfico de salida) y me sobraba, ya que la mayoría casi 24TB es tráfico de entrada.
Aunque ya había estado allí hace muchos años, nunca lo hice con Proxmox. Os dejo aquí mi experiencia, ya que sus manuales son un poco cuadriculados y ausente para ciertas cosas, y su soporte es nulo, más allá de enviarte a sus manuales.
Casi todos los soportes de grandes proveedores de Hosting y Colo, son parecidos. En cierta manera les entiendo, pero si dan 0 soporte sus manuales tienen que ser impecables.
Proxmox Modo Routed en lugar de bridge
El porqué es claro. Hetzner solo te permite 7 ips por servidor o pasas por caja para coger un bloque, y sus bloques no funcionan en modo bridge.
El modo bridge es como el OVH para IP Failover. Tienes que asignar un MAC vía ticket, robot, api.. El método routed no.
El Manual Hetztner es necesario leerlo, o puedes llevarte una sorpresa.
En mi caso, la instalación estaba clara: Sin raid (por software es una patata, y además, el alcance de este servidor no requiere de raid), modelo de Routed forzado por el sistema de Hetzner para bloques de IPS adicionales.
Bien lo primero que observe y que produjo un choque,m fue que las imágenes de las acciones en el frontend de Proxmox para crear y modificar la red, no concuerdan con lo que luego graba en el fichero /etc/network/interfaces
Además hay algunos puntos sutiles respecto a la notación de algunas IP.
IPV4/CIDR
El ejemplo te puede llevar a error porque te pone un CIDR /26 tanto en el texto como el gráfico, si mayor explicación.
Resulta que Hetzner no te entrega toda la información en su Robot, y por tanto te aconsejo que calcules tu red.
Por si te olvidaste cómo hacerlo mejor te dejo esta calculadora de redes aunque es posible que sea mejor que Hetzner te lo diga en un ticket.
Fichero /etc/network/interfaces
En vez del frontend pasamos a modo shell
Notas sobe algunos elementos usados
- CIDR Classless Inter-Domain Routing
- enp41s0 es la interfaz de red que puede ser distinta según modelo.
source /etc/network/interfaces.d/*
auto lo
iface lo inet loopback
iface lo inet6 loopback
auto enp41s0
iface enp41s0 inet static
address IP_SERVIDOR/CIDR
gateway GATEWAY_IP_SERVIDOR
up route add -net IP_BLOQUE_IPS netmask 255.255.NETMASK_BLOQUE gw IP_SERVIDOR/ dev enp41s0
#Routed mode
iface enp41s0 inet6 static
address SUBNET_IPV6::2/64 # Atención al 2
gateway fe80::1 # Revisar al gateway que te da Hetzner para el bloque IPv6
auto vmbr0
iface vmbr0 inet static
address IP_SERVIDOR/32
bridge-ports none
bridge-stp off
bridge-fd 0
iface vmbr0 inet6 static
address SUBNET_IPV6::2/64
/etc/network/interfaces.d/vm-routes
iface vmbr0 inet static
#up ip route add IP_BLOQUE_IPS/28 dev vmbr0 # no me funciono
up ip route add IP_BLOQUE_IPS.193/32 dev vmbr0
up ip route add BLOQUE_IPS.194/32 dev vmbr0
up ip route add BLOQUE_IPS.195/32 dev vmbr0
up ip route add BLOQUE_IPS.196/32 dev vmbr0
up ip route add BLOQUE_IPS.197/32 dev vmbr0
up ip route add BLOQUE_IPS.198/32 dev vmbr0
up ip route add BLOQUE_IPS.199/32 dev vmbr0
up ip route add BLOQUE_IPS.200/32 dev vmbr0
up ip route add BLOQUE_IPS.201/32 dev vmbr0
up ip route add BLOQUE_IPS.202/32 dev vmbr0
up ip route add BLOQUE_IPS.203/32 dev vmbr0
up ip route add BLOQUE_IPS.204/32 dev vmbr0
up ip route add BLOQUE_IPS.205/32 dev vmbr0
up ip route add BLOQUE_IPS.206/32 dev vmbr0
iface vmbr0 inet6 static
up ip -6 route add SUBNET_IPV6::/64 dev vmbr0
Configserver Firewall
A mi no me gusta nada el firewall que usa Proxmox, así que sigo usando Configserver CSF, pero esto requiere ciertos añadidos
Necesitamos pasarle a CSF la interfaz que hace de Bridge o enrutador.
Para ello añadimos el fichero /etc/csf/csfpre.sh con los siguientes datos.
#!/bin/sh
iptables -A INPUT -i vmbr0 -j ACCEPT
iptables -A OUTPUT -o vmbr0 -j ACCEPT
iptables -A FORWARD -j ACCEPT -p all -s 0/0 -i vmbr0
iptables -A FORWARD -j ACCEPT -p all -s 0/0 -o vmbr0
Y reiniciamos CSF con csf -ra
Ahora el tráfico funcionará hacia los hosts.
VPS KVM
Centos 7
De momento solo he migrado dos máquinas con Centos 7, más adelante pondré los datos de máquinas con modelo Ubuntu y Debian.
cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=none
IPADDR=BLOQUE_IPS.XXX
NETMASK=255.255.255.255
SCOPE="peer IP_SERVIDOR_PROXMOX"
IPV6INIT=no
GATEWAY=peer IP_SERVIDOR_PROXMOX
Nota importante
Tras dos problemas con sod VPS, he encontrado que esta configuración sólo funciona usando NetworkManager. (fecha: 26/02/2023). Espero el lunes o martes tener una respuesta distinta, ya que el NetworkManager nio debe estar axctivo con el pesado de cPanel.
El problema reside en que no levanta la tabla de rutas de forma correcta, por lo que no hay enrutamiento correcto hacia internet
Importante revisar por si venimos de algún proveedor con otro sistema, que no tengan algún fichero de rutas especificado de su despliegue.
Lecturas por si acaso
Por ejemplo si usas un Centos 6 que teneia el sistema udev antiguo, y cargaba las tarejtas de red con su mac
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Desactivar los mensajes de log en la consola (Proxmox)
Introducción
Una de las cosas que hago al comenzar con una nueva máquina de Proxmox, es desactivar la redirección de los mensajes de kernel log hacia la consola virtual. Es una pesadilla si te olvidas de de hacerlo, pues el próximo día que necesites acceder a tu servidor Proxmox, vía KVM a distancia (no la con sola de Proxmox si no la de OVH por ejemplo, la de Hetzner) sufrirás la continua emisión de logs a la consola virtual, lo cual hace muchas veces imnposible el trabajo en la consola.
Solución para desactivar los mensajes del log en la consola virtual
/etc/sysctl.conf
Bien como Proxmox se ejecuta sobre una Debian, edita el fichero /etc/sysctl.conf y dejalo como esta aquí debajo:
# Uncomment the following to stop low-level messages on console
kernel.printk = 3 3 3 3
No necesitas hacer un restart si no quieres.
Puedes activar la configuración como siempre que modificas ese fichero con:
sudo sysctl -p
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Proxmox: Servicios Colgados - Diagnóstico y Soluciones
Descripción del Problema
Proxmox ocasionalmente experimenta un estado donde los servicios del sistema de gestión se "cuelgan", resultando en:
- Frontend web inaccesible o extremadamente lento
- Comandos de Proxmox no responden (pvesh, pvecm, qm, pct)
- VMs/Containers siguen funcionando pero sin gestión
- SSH funciona pero utilidades de Proxmox fallan
- Contenedores fucionales pero lenbtos y pesados sin presentar cargar que lo explique.
Diagnóstico
Verificación del Estado de Servicios
# Comprobar posibles problemas con NFS
df -h
# Comprobar estado de servicios críticos
systemctl status pve-cluster
systemctl status pvedaemon
systemctl status pvestatd
systemctl status pveproxy
# Verificar logs para identificar errores
journalctl -u pve-cluster -f
journalctl -u pvedaemon -f
tail -f /var/log/pve/tasks/active
Indicadores Comunes
- pve-cluster: Estado "failed" o "timeout"
- pvedaemon: No responde a peticiones API
- pveproxy: Error 502/503 en interfaz web
- Alta carga del sistema sin razón aparente
Verificación de Recursos
# Comprobar memoria y CPU
free -h
top -n 1
# Estado del almacenamiento
df -h
iostat -x 1 3
# Conectividad de cluster (si aplica)
pvecm status
Soluciones
Solución Rápida (Restart de Servicios)
# Secuencia de reinicio recomendada
service pve-cluster restart && \
service pvedaemon restart && \
service pvestatd restart && \
service pveproxy restart
# Verificar que los servicios han iniciado correctamente
systemctl status pve-cluster pvedaemon pvestatd pveproxy
Solución Alternativa por Pasos
# Si el comando conjunto falla, reiniciar individualmente
systemctl stop pveproxy
systemctl stop pvestatd
systemctl stop pvedaemon
systemctl stop pve-cluster
# Esperar unos segundos y reiniciar en orden
systemctl start pve-cluster
sleep 5
systemctl start pvedaemon
sleep 3
systemctl start pvestatd
systemctl start pveproxy
Troubleshooting Avanzado
Si pve-cluster no inicia:
# Verificar quorum (en clusters)
pvecm expected 1
# Limpiar archivos de lock problemáticos
rm -f /var/lib/pve-cluster/.pmxcfs.lockfile
systemctl start pve-cluster
Si persisten problemas:
# Reinicio completo del stack de Proxmox
systemctl restart pve-cluster pvedaemon pvestatd pveproxy
# Reinicio completo del stack de Proxmox completo. Opción más dura.
systemctl restart pve-cluster pvedaemon pvestatd pveproxy corosync
# Como último recurso (CUIDADO: puede afectar VMs)
# Si tienes un KVM remoto para la máquina baremetal es el momento de activarl y tenerla abierta
reboot
Prevención
Monitoreo Proactivo
# Script de verificación periódica
#!/bin/bash
services=("pve-cluster" "pvedaemon" "pvestatd" "pveproxy")
for service in "${services[@]}"; do
if ! systemctl is-active --quiet $service; then
echo "$(date): $service is down" >> /var/log/pve-health.log
systemctl restart $service
fi
done
Configuración de Cron
# Añadir al crontab (cada 5 minutos)
*/5 * * * * /path/to/pve-health-check.sh
Causas Comunes
- Sobrecarga de memoria en el host Proxmox
- Problemas de red en configuraciones de cluster
- Almacenamiento lento o con alta latencia
- Actualizaciones parciales o interrumpidas
- Configuraciones de firewall bloqueando puertos internos
- Problemas con monatajes NFS bloquenado el subsistema de ficheros PVE
Puertos Críticos de Proxmox
- 8006: Interfaz web HTTPS
- 5404/5405: Corosync (cluster)
- 111/2049: NFS (si se usa)
- 3128: Proxy de descarga
Logs Importantes
/var/log/pve/tasks/active- Tareas en ejecución/var/log/daemon.log- Servicios del sistema/var/log/pve/cluster.log- Información del clusterjournalctl -u pve-*- Logs específicos de servicios
Notas Adicionales
⚠️ Importante: Los VMs y containers continúan ejecutándose durante estos problemas, solo se ve afectada la gestión.
✅ Tip: Mantener siempre acceso SSH alternativo para poder ejecutar estos comandos de recuperación.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Ampliación de disco (basado en qcow2) en sistema virtualizado KVM (proxmox)
Contexto
Proceso para ampliar un disco virtual qcow2 en Proxmox cuando el sistema operativo invitado usa LVM y la tabla de particiones GPT no reconoce el nuevo tamaño tras la ampliación.
Escenario inicial
- Disco qcow2 ampliado desde ~36GB a 46GB en Proxmox
- Sistema operativo no reconoce el espacio adicional
- Estructura: sda1 (BIOS boot), sda2 (boot), sda3 (LVM PV)
Síntomas
fdisk /dev/sda
Welcome to fdisk (util-linux 2.39.3).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
GPT PMBR size mismatch (75497471 != 96468991) will be corrected by write.
The backup GPT table is not on the end of the device. This problem will be corrected by write.
This disk is currently in use - repartitioning is probably a bad idea.
It's recommended to umount all file systems, and swapoff all swap
partitions on this disk.
Command (m for help): p
Disk /dev/sda: 46 GiB, 49392123904 bytes, 96468992 sectors
Disk model: QEMU HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: EBD99DE4-BA1E-4F14-9EFF-FE7FE140CF1A
Device Start End Sectors Size Type
/dev/sda1 2048 4095 2048 1M BIOS boot
/dev/sda2 4096 3674111 3670016 1.8G Linux filesystem
/dev/sda3 3674112 75497438 71823327 34.2G Linux filesystem
Command (m for help): q
Observamos el mensaje de problemas y el de la capacidad de discos, que no es renocido pese a que su tamaño si lo es, 46Gib vs 36Gib
Prerequisitos
- Backup: Crear snapshot en Proxmox antes de proceder
- Acceso: Conexión SSH o consola al sistema invitado
- Herramientas: gdisk, parted, lvm2 (generalmente preinstalados)
Proceso paso a paso
1. Verificar estado inicial
❯ pvscan
PV /dev/sda3 VG ubuntu-vg lvm2 [<34.25 GiB / 0 free]
Total: 1 [<34.25 GiB] / in use: 1 [<34.25 GiB] / in no VG: 0 [0 ]
2. Corregir estructura GPT
gdisk /dev/sda
GPT fdisk (gdisk) version 1.0.10
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): v
Problem: The secondary header's self-pointer indicates that it doesn't reside
at the end of the disk. If you've added a disk to a RAID array, use the 'e'
option on the experts' menu to adjust the secondary header's and partition
table's locations.
Warning: There is a gap between the secondary partition table (ending at sector
75497470) and the secondary metadata (sector 75497471).
This is helpful in some exotic configurations, but is generally ill-advised.
Using 'k' on the experts' menu can adjust this gap.
Caution: Partition 3 doesn't end on a 2048-sector boundary. This may
result in problems with some disk encryption tools.
Identified 1 problems!
Command (? for help): x
Expert command (? for help): e
Relocating backup data structures to the end of the disk
Expert command (? for help): w
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y
OK; writing new GUID partition table (GPT) to /dev/sda.
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot or after you
run partprobe(8) or kpartx(8)
The operation has completed successfully.
3. Redimensionar partición
# Expandir la partición al 100% del disco disponible
parted /dev/sda resizepart 3 100%
4. Expandir Physical Volume
# Redimensionar el PV para usar todo el espacio de la partición
❯ pvresize /dev/sda3
Physical volume "/dev/sda3" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
# Verificar el resultado
> pvdisplay /dev/sda3
--- Physical volume ---
PV Name /dev/sda3
VG Name ubuntu-vg
PV Size <44.25 GiB / not usable 16.50 KiB
Allocatable yes (but full)
PE Size 4.00 MiB
Total PE 11327
Free PE 0
Allocated PE 11327
PV UUID NzNz30-KIRH-bWmQ-aSFy-N0mU-x1lt-hQ62uH
5. Expandir Logical Volume y filesystem
# Conocer el VL de aplicación (Pueden ser varios, y cada uno una cnatidad)
❯ lvscan
ACTIVE '/dev/ubuntu-vg/ubuntu-lv' [<34.25 GiB] inherit
# Expandir el LV usando todo el espacio libre disponible (ejemplo)
❯ lvresize --extents +100%FREE --resizefs /dev/ubuntu-vg/ubuntu-lv
Size of logical volume ubuntu-vg/ubuntu-lv changed from <34.25 GiB (8767 extents) to <44.25 GiB (11327 extents).
Logical volume ubuntu-vg/ubuntu-lv successfully resized.
resize2fs 1.47.0 (5-Feb-2023)
Filesystem at /dev/mapper/ubuntu--vg-ubuntu--lv is mounted on /; on-line resizing required
old_desc_blocks = 5, new_desc_blocks = 6
The filesystem on /dev/mapper/ubuntu--vg-ubuntu--lv is now 11598848 (4k) blocks long.
# El flag --resizefs ejecuta automáticamente resize2fs
6. Verificación final
# Verificar espacio disponible
df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ubuntu--vg-ubuntu--lv 44G 32G 10G 77% /
# Vista general de la estructura
lsblk
...
sda 8:0 0 46G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 1.8G 0 part /boot
└─sda3 8:3 0 44.2G 0 part
└─ubuntu--vg-ubuntu--lv 252:0 0 44.2G 0 lvm /
sr0 11:0 1 1024M 0 rom
...
# Verificar estado LVM
vgdisplay
lvdisplay
Mensajes esperados
Durante gdisk verify (v)
Problem: The secondary header's self-pointer indicates that it doesn't reside at the end of the disk
Warning: There is a gap between the secondary partition table and secondary metadata
Caution: Partition 3 doesn't end on a 2048-sector boundary
Nota: Estos son problemas esperados tras ampliar el disco y se corrigen con el comando e en expert mode.
Durante lvresize
Physical volume "/dev/sda3" changed
Size of logical volume changed from <34.25 GiB to <44.25 GiB
resize2fs: on-line resizing required
The filesystem is now XXXXXX (4k) blocks long.
Consideraciones importantes
Seguridad
- Sin downtime: Todo el proceso se ejecuta en caliente
- Solo crecimiento: No se mueven ni reducen datos existentes
- LVM como protección: Añade capa adicional de seguridad
Orden crítico
- Corregir GPT antes que redimensionar particiones
- Redimensionar partición antes que PV
- Expandir PV antes que LV
Troubleshooting común
- "Disk in use" warning: Normal, se puede ignorar en operaciones de crecimiento
- GPT mismatch: Esperado tras resize de qcow2, se corrige con gdisk
- Alignment warnings: Generalmente no críticos en discos virtuales
Comandos de verificación post-proceso
# Verificar que no quedan problemas GPT
gdisk /dev/sda
v
q
# Estado final del disco
fdisk -l /dev/sda
# Estado LVM completo
pvs && vgs && lvs
# Espacio en filesystem
df -h /
Resultado esperado
- Disco reconocido con nuevo tamaño completo
- Sin mensajes de error en GPT
- Espacio adicional disponible en el filesystem raíz
- Sistema operativo funcionando normalmente
- Proceso validado en Ubuntu 22.04 sobre Proxmox VE con discos qcow2
- Generado el 26/09/2025 por Abdelkarim Mateos Sánchez - Administrador de Sistemas
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Ampliación de disco en sistema virtualizado KVM (proxmox)
Introduccion
En un escenario de uso de discos virtuales, como KVM, Proxmox y otros, a veces es necesario una ampliacion del disco. Si usamos LVM esto es posible y sencillo.
Convenciones
Ciertas cosas que hay en esta entrada, asi como en otras, requieren un conocimiento previo. No es un sitio para copiar y pegar sino para entender y hacer
No siempre es el disco vda, no siempre es la particion 1, y asi sucesivamente.
Ampliacion de una disco virtual KVM
La ampliacion de un disco LVM es posible una vez que hemos realizado el cambio virtual del tamano de la unidad LVM.
En el caso de Proxmox acudimos a la administracion de nuestro proxmox:
- Seleccionamos el VPS
- Click en **Resize Disk"
- Incrementamos el tamano.
Si el aumento de tamano implica un tamano final mayor de 2 TiB deberas tener el esquema de particiones GPT de lo contrario, tendras que modificar bajo tu responsabilidad el esquema MBR a GPT. Esta entrada no trata de eso, y para ello es aconsejable el uso de Gparted Live, lo cual no siempre es posible.
El articulo interpreta que conoces el uso de ciertos comando, que sustituiran el dispositivo (disco) por el tuyo, y que sabes como obtener el esquema de tu disco (particiones)
Consejo sobre particionamiento durante la instalacion
Es aconsejable el uso de GPT y de ello hablamos en nuestra wiki, Instalacion GPT con el instalador Centos 7 en discos menores de 2 TiB
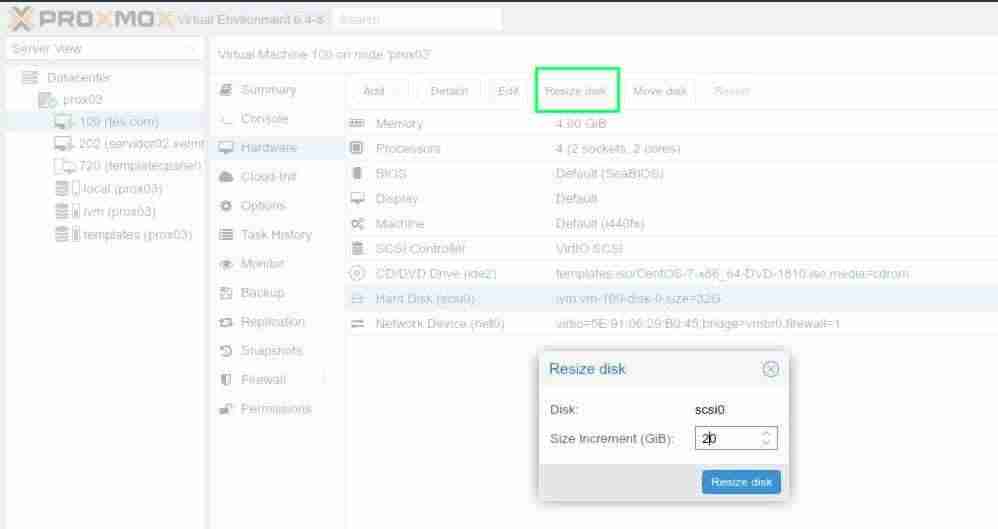
Verificacion en un KVM basado en LVM
Una vez que hemos ampliado el disco, podemos verificar el cambio de tamano en nuestro VPS. Esto funcionara hasta que reiniciemos la maquina. Despues ya no nos informara.
vda, vdb, sda, ... son nombres de dispositivos. Debes consultar cuales son tus dispositivos de disco usando
fdisk -ly usar el apropiado en el comando
dmesg | grep vda
...
[ 222.436098] vda: detected capacity change from 32212254720 to 37580963840
Imprimir la tabla actual del disco
fdisk -l /dev/vda | grep ^/dev
/dev/vda1 * 2048 1026047 512000 83 Linux
/dev/vda2 1026048 62914559 30944256 8e Linux LVM
Conocer el uso de las particiones en el sistema LVM
pvscan
PV /dev/vda2 VG centos lvm2 [<29,51 GiB / 40,00 MiB free]
Total: 1 [<29,51 GiB] / in use: 1 [<29,51 GiB] / in no VG: 0 [0 ]
lvscan
ACTIVE '/dev/centos/swap' [3,00 GiB] inherit
ACTIVE '/dev/centos/root' [<26,47 GiB] inherit
Metodo rapido y recomendado: growpart (GPT, no interactivo)
Desde hace años existe growpart (paquete cloud-guest-utils en Debian/Ubuntu, cloud-utils-growpart en RHEL/Alma/Rocky), que automatiza en un solo comando lo que en los casos anteriores se hace a mano con parted: extiende la partición para ocupar todo el espacio nuevo y reubica la tabla GPT de respaldo al final del disco (el "Fix" que parted pide de forma interactiva). Es no interactivo, idempotente y seguro sobre particiones en uso, por lo que es la vía preferida en discos GPT.
Para la pila típica disco virtual → partición → PV → VG → LV → XFS, una vez ampliado el disco en Proxmox (Resize Disk), el procedimiento completo en caliente (sin desmontar) es:
# 1. Crecer la partición (ej: partición 1 del disco vdd). growpart reubica el backup GPT solo
growpart /dev/vdd 1
# 2. Extender el Physical Volume de LVM al nuevo tamaño de la partición
pvresize /dev/vdd1
# 3. Extender el Logical Volume con todo el espacio libre del VG
lvextend -l +100%FREE /dev/stor2/stor2_vol
# 4. Crecer el filesystem (XFS crece montado; para EXT4 usar resize2fs)
xfs_growfs /srv/storage2
Ejemplo real de salida (ampliación de /srv/storage2 de 4 TiB a 8 TiB sobre /dev/vdd):
growpart /dev/vdd 1
CHANGED: partition=1 start=2048 old: size=8589932511 end=8589934558 new: size=17179867103 end=17179869150
pvresize /dev/vdd1
Physical volume "/dev/vdd1" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
lvextend -l +100%FREE /dev/stor2/stor2_vol
Size of logical volume stor2/stor2_vol changed from <4.00 TiB to <8.00 TiB.
Logical volume stor2/stor2_vol successfully resized.
xfs_growfs /srv/storage2
data blocks changed from 1073740800 to 2147482624
Por qué funciona en caliente:
growpartusa el ioctlBLKPG_RESIZE_PARTITION, que actualiza una sola partición sin re-leer toda la tabla, así que no falla aunque la partición esté en uso como PV activo de LVM. Y al reubicar él mismo el backup GPT, evita el error típico de responder mal al diálogo interactivo departed. Si el sistema no traegrowpart:apt install cloud-guest-utils(Debian/Ubuntu) odnf install cloud-utils-growpart(RHEL/Alma/Rocky).
Caso 1: Particion primaria con LVM (GPT o MBR simple)
Este es el caso mas comun en instalaciones modernas con GPT.
Ampliar la particion fisica
parted /dev/vda
GNU Parted 3.1
Usando /dev/vda
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 37,6GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Numero Inicio Fin Tamano Typo Sistema de ficheros Banderas
1 1049kB 525MB 524MB primary xfs arranque
2 525MB 32,2GB 31,7GB primary lvm
(parted) resizepart 2 100%
(parted) quit
Asignar el nuevo tamano al volumen fisico de LVM
pvresize /dev/vda2
Physical volume "/dev/vda2" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
Caso 2: Particion extended con logical (MBR clasico)
IMPORTANTE: Algunas instalaciones antiguas (especialmente Debian/Ubuntu) usan esquema MBR con particiones extended y logical. En este caso hay que ampliar DOS particiones en orden.
Ejemplo de estructura:
Number Start End Size Type File system Flags
1 1049kB 512MB 511MB primary ext2 boot
2 513MB 698GB 697GB extended
5 513MB 698GB 697GB logical lvm
Aqui vda2 es un contenedor (extended) y vda5 es la particion real con LVM (logical).
Paso 1: Ampliar la particion extended
parted /dev/vda
(parted) resizepart 2 100%
(parted) quit
Paso 2: Ampliar la particion logical
parted /dev/vda
(parted) resizepart 5 100%
(parted) quit
Verificar que ambas particiones ahora ocupan todo el espacio:
parted /dev/vda print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 752GB
Number Start End Size Type File system Flags
1 1049kB 512MB 511MB primary ext2 boot
2 513MB 752GB 751GB extended
5 513MB 752GB 751GB logical lvm
Paso 3: Redimensionar el Physical Volume
CRITICO: El PV esta en la particion logical (vda5), NO en la extended (vda2):
pvresize /dev/vda5
Physical volume "/dev/vda5" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
Error comun: ejecutar pvresize /dev/vda2 da error "device is too small" porque vda2 es la extended, no contiene el PV.
Paso 4: Verificar el nuevo espacio disponible
vgs
VG #PV #LV #SN Attr VSize VFree
kvm330-vg 1 2 0 wz--n- <699.52g 50g
El VFree muestra el espacio nuevo disponible.
Redimensionar el volumen logico de LVM
Todo para una particion
lvresize --extents +100%FREE --resizefs /dev/centos/root
Size of logical volume centos/root changed from <26,47 GiB (6776 extents) to <31,51 GiB (8066 extents).
Logical volume centos/root successfully resized.
Resize Volumen Logico por tamano exacto a anadir
En un sistema con distintas particiones es diferente:
df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ubuntu--vg-ubuntu--lv 10G 2.7G 7.4G 27% /
/dev/mapper/ubuntu--vg-lv--usr 6.0G 5.6G 450M 93% /usr
/dev/mapper/ubuntu--vg-lv--home 5.0G 88M 5.0G 2% /home
/dev/mapper/ubuntu--vg-lv--var 6.0G 1.3G 4.8G 21% /var
Ampliar solo la particion /usr en 2GB:
lvextend -L+2G /dev/ubuntu-vg/lv-usr
Size of logical volume ubuntu-vg/lv-usr changed from 6.00 GiB to 8.00 GiB.
Logical volume ubuntu-vg/lv-usr successfully resized.
Expandir el sistema de archivos (para XFS):
xfs_growfs /dev/ubuntu-vg/lv-usr
data blocks changed from 1572864 to 2097152
Para EXT4 usar resize2fs o la opcion --resizefs en lvresize.
Mensajes de error comunes
Error en parted: tabla GPT al final del disco
A veces, es posible que tras un acceso con parted a nuestro dispositivo, podemos encontrar mensajes relativos a problemas derivados de los instaladores de Centos, de Ubuntu, segun cuando y como se hizo la particion.
Error: La copia de la tabla GPT no esta al final del disco, como deberia ser.
Arreglar/Fix/Descartar/Ignore/Cancelar/Cancel? Fix
Aviso: Not all of the space available to /dev/vda appears to be used
Arreglar/Fix/Descartar/Ignore? F
Responder Fix a estos mensajes para corregir la tabla GPT.
Con
growpart(ver el método congrowpartmás arriba) este diálogo no aparece: el fix del backup GPT lo realiza automáticamente.
Error pvresize: device is too small
pvresize /dev/vda2
Cannot use /dev/vda2: device is too small (pv_min_size)
0 physical volume(s) resized or updated / 0 physical volume(s) not resized
Este error ocurre cuando se intenta hacer pvresize sobre la particion extended en lugar de la logical. Verificar con pvscan cual es la particion correcta que contiene el Physical Volume.
Actualizacion 2024-03-21
En nuevas versiones de parted, por ejemplo en AlmaLinux 8, no es posible usar el comando interactivo como anteriormente. Debes hacerlo directamente en el shell:
parted /dev/sdx --script resizepart NumeroParticion 100%
Aviso
Esta documentacion y su contenido, no implica que funcione en tu caso o determinados casos. Tambien implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad.
El contenido se entrega, tal y como esta, sin que ello implique ninguna obligacion ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
IPv6 para VMs en Proxmox sobre OVH bare-metal (NDP proxy)
- Fecha: 2026-05-23
- Autor: Abdelkarim Mateos
- Estado: vigente
- Aplicable a: servidores OVH bare-metal con dos NICs separadas (RISE / Advance / SYS) y Proxmox VE 8/9 como hypervisor KVM
- No aplica: OVH HG (NIC única + vRack en VLAN tagged), OVH Public Cloud, Hetzner Cloud o cualquier proveedor donde el switch del segmento público no haga filtrado por MAC
Nota sobre las direcciones de los ejemplos. Todas las IPv4, IPv6 y MAC que aparecen en este documento son valores de documentación reservados por la IETF: bloque
203.0.113.0/24(RFC 5737, TEST-NET-3) para IPv4 y prefijo2001:db8::/32(RFC 3849) para IPv6. Sustituir por los valores reales del servidor al aplicar. He preservado deliberadamente la topología característica de OVH — gateway IPv6 con muchos hextetsffy fuera del/64ruteado, requiriendoonlink— para que los ejemplos reflejen el comportamiento real. Publicar IPs reales en documentación pública es un señuelo gratuito para scanners — evítalo siempre.
Escenario
Pongo en marcha un OVH RISE-L (Ryzen 9, 128 GB RAM, 2× Intel I210) como host Proxmox VE 9 para alojar máquinas virtuales KVM. La intención: que las VMs tengan IPv6 público aprovechando el /64 que OVH enruta por defecto hacia el MAC del servidor.
El primer intento (asignar a la VM una dirección del /64 con el gateway OVH onlink, igual que se hace en Hetzner Cloud) no funciona — el NDP de la VM al gateway se queda en INCOMPLETE. Este documento explica por qué y cómo se resuelve con NDP proxy (ndppd) más un bridge interno.
Topología hardware OVH RISE
Las gamas RISE / Advance / SYS entregan dos NICs separadas, no agrupadas en LACP, sin bonding. Una va al switch público de OVH, la otra al vRack (red privada / IPs adicionales enrutadas).
| Modelo | Topología NICs |
|---|---|
| RISE / Advance / SYS | 2× NICs separadas — una pública, otra vRack |
| HG (High Grade / Game) | NIC única, vRack en VLAN tagged sobre la misma interfaz |
| Eco | Igual que RISE en topología, con limitaciones de garantía vRack |
En este documento la NIC pública es enp6s0 (mapeada al bridge vmbr0) y la NIC del vRack es enp7s0 (mapeada al bridge vmbr1). Cada modelo usa nombres distintos según firmware/kernel — comprobar con lspci -nn | grep Ether y ip -br link.
Recursos IP del ejemplo (documentación)
vmbr0(pública): IPv4 del bloque que OVH asigna al servidor (203.0.113.10/24) y un/64IPv6 enrutado al MAC del servidor (2001:db8:1:1::/64, gateway2001:db8:1:ffff:ff:ff:ff:ff).vmbr1(vRack): sin IP en el host, bridge limpio. Las VMs cogen IPs de los bloques que el cliente haya pedido enrutar al vRack.
Por qué el approach naive no funciona
Asignar a una VM una IPv6 del /64 con el gateway OVH onlink es lo que recomienda la documentación oficial OVH para el lado guest. Pero falla:
admin@vm:~$ ping6 2001:db8:1:ffff:ff:ff:ff:ff
From 2001:db8:1:1::100 icmp_seq=1 Destination unreachable: Address unreachable
admin@vm:~$ ip -6 neigh show
2001:db8:1:ffff:ff:ff:ff:ff dev eth1 INCOMPLETE
La VM envía una Neighbor Solicitation al gateway y nunca recibe Neighbor Advertisement de vuelta. Causa: el switch del segmento público de OVH hace filtrado por MAC. Solo deja entrar tramas cuyo MAC destino sea el del servidor — la respuesta del gateway, dirigida al MAC de la VM, se descarta en el switch.
En el vRack ese filtrado no está activo (es un L2 abierto, precisamente para esto). Por eso el IPv4 funciona "directo" en el vRack pero el IPv6 del /64 público no.
Arquitectura NDP proxy
La solución estándar es que el host responda NDP por las VMs. Ante el switch OVH solo existe un MAC (el del host); el routing IPv6 a cada VM se hace internamente en el kernel del host:
+--------------------+ +----------------------------+
| OVH router IPv6 | -- L2 --| enp6s0 → vmbr0 |
| ...:ffff:ff:ff::ff | | host: 2001:db8:1:1::1/128 |
+--------------------+ +-------------+--------------+
| kernel IPv6 forwarding
| proxy_ndp + ndppd
v
+----------------------------+
| vmbr2 (sin puerto físico) |
| host: 2001:db8:1:1::ffff/64|
+-------------+--------------+
|
+----------------+----------------+
v v v
VM-A VM-B VM-C
::100/64 ::101/64 ::102/64
gw ::ffff gw ::ffff gw ::ffff
Tres piezas:
- Host con
/128envmbr0— no se queda con el/64entero, solo con una IP propia (típicamente::1/128o::ffff/128). - Bridge interno
vmbr2sin puerto físico, con el/64y una IP que actúa de gateway para las VMs (en este ejemplo::ffff). ndppdescuchando envmbr0— responde a las NDP Solicitations del gateway OVH con el MAC del host para cualquier dirección dentro del/64. El kernel entonces enruta el tráfico haciavmbr2por la tabla v6, y de ahí a la VM correspondiente.
Sysctl obligatorios:
net.ipv6.conf.all.forwarding = 1— sin esto el host descarta paquetes IPv6 destinados a otras IPs.net.ipv6.conf.all.proxy_ndp = 1— habilita la lógica de NDP proxy del kernel.ndppdlo activa al arrancar pero conviene persistirlo por sysctl.
Configuración paso a paso
1. /etc/network/interfaces del host
Stanza relevante (Proxmox autogestiona la primera parte; estas líneas se añaden al final):
# IPv6 NDP-proxy approach
iface vmbr0 inet6 static
address 2001:db8:1:1::1/128
gateway 2001:db8:1:ffff:ff:ff:ff:ff
auto vmbr2
iface vmbr2 inet6 static
address 2001:db8:1:1::ffff/64
bridge-ports none
bridge-stp off
bridge-fd 0
Aplicar con ifreload -a — no hace falta reiniciar.
2. Sysctl persistente
/etc/sysctl.d/99-ipv6-ndp-proxy.conf:
net.ipv6.conf.all.forwarding = 1
net.ipv6.conf.all.proxy_ndp = 1
Aplicar con sysctl --system.
3. Instalar y configurar ndppd
apt-get install -y ndppd
/etc/ndppd.conf:
route-ttl 30000
proxy vmbr0 {
router no
timeout 500
ttl 30000
rule 2001:db8:1:1::/64 {
auto
}
}
Trampa de versión: el ejemplo distribuido en /usr/share/doc/ndppd/ndppd.conf-dist menciona el keyword static como "NEW", pero en la versión que trae Debian 13 Trixie (ndppd 0.2.4) static falla con Failed to load configuration file sin más detalle. Usar auto — funciona y resuelve dinámicamente vía /proc/net/ipv6_route.
Habilitar el servicio:
systemctl enable --now ndppd
systemctl is-active ndppd # debe responder 'active'
journalctl -u ndppd -n 20 # 'Failed to load' = error de sintaxis
4. Configurar las VMs
Por cloud-init en Proxmox:
qm set <VMID> --net1 virtio,bridge=vmbr2
qm set <VMID> --ipconfig1 "ip6=2001:db8:1:1::100/64,gw6=2001:db8:1:1::ffff"
Importante: el gateway de la VM es la IP del host en vmbr2 (::ffff), NO el gateway OVH. La VM rutea hacia el host, el host hace el forwarding hacia OVH.
Para Debian/Ubuntu sin cloud-init, en /etc/network/interfaces de la VM:
iface ens19 inet6 static
address 2001:db8:1:1::100/64
gateway 2001:db8:1:1::ffff
5. CSF (si se usa)
Si el host tiene CSF con IPV6 = "1", CSF deja la cadena FORWARD de ip6tables en policy DROP. Esto rompe el forwarding entre vmbr2 y vmbr0 — las VMs reciben IPv6 pero no pueden enviar.
Añadir un hook persistente en /usr/local/include/csf/post.d/10-ipv6-forward.sh:
#!/bin/sh
ip6tables -A FORWARD -i vmbr2 -o vmbr0 -j ACCEPT
ip6tables -A FORWARD -i vmbr0 -o vmbr2 -j ACCEPT
chmod +x y csf -r. CSF carga post.d/*.sh automáticamente tras cada restart.
Verificación
Desde dentro de una VM con la configuración aplicada:
admin@vm:~$ ip -6 addr show eth1 | grep inet6
inet6 2001:db8:1:1::100/64 scope global
admin@vm:~$ ping6 -c2 2606:4700:4700::1111
PING 2606:4700:4700::1111 56 data bytes
64 bytes from 2606:4700:4700::1111: icmp_seq=1 ttl=58 time=5.13 ms
64 bytes from 2606:4700:4700::1111: icmp_seq=2 ttl=58 time=5.14 ms
admin@vm:~$ ip -6 route show
2001:db8:1:1::/64 dev eth1 proto kernel
default via 2001:db8:1:1::ffff dev eth1 proto static
Desde el host:
# El gateway OVH debe aparecer REACHABLE, no INCOMPLETE
root@host:~$ ip -6 neigh show dev vmbr0 | grep ffff:ff
2001:db8:1:ffff:ff:ff:ff:ff lladdr 02:00:5e:00:00:01 router REACHABLE
# ndppd activo
root@host:~$ pidof ndppd
12345
# La tabla NDP proxy estática puede estar vacía — ndppd responde dinámicamente
root@host:~$ ip -6 neigh show proxy
(vacío)
Trampas conocidas
- Happy Eyeballs ignora
gai.conf. Si necesitas que el host hable solo IPv4 (por ejemplo para queacme.shuse un token Cloudflare con allowlist solo IPv4), el típicoprecedence ::ffff:0:0/96 100en/etc/gai.confno basta:curlcon Happy Eyeballs (RFC 8305) lanza la conexión IPv6 con 200 ms de ventaja y siempre gana contra anycast. Para forzar IPv4 hay que quitar IPv6 del host o usarcurl -4por comando. ndppd staticno funciona en 0.2.4 (Debian 13). Usarauto.- CSF y
FORWARD policy DROP— necesitan hook enpost.d. Sin él, las VMs reciben IPv6 pero no pueden enviar (FORWARD bloquea ambos sentidos para flujos nuevos). qm shutdownfalla sinqemu-guest-agenten la VM. Las imágenes Ubuntu cloud no lo traen instalado por defecto — instalarqemu-guest-agentdentro de la VM si quieres shutdown limpio.- MAC regenerado al cambiar de bridge. Si haces
qm set <VMID> --net1 virtio,bridge=vmbrXsin especificar=<MAC>previo, Proxmox regenera el MAC. Cloud-init reescribe netplan en consecuencia. - Una entrada NDP proxy por VM vs
ndppdpara todo el/64. Si tienes pocas VMs estables, puedes prescindir dendppdy ponerip -6 neigh add proxy <ip> dev vmbr0(comopost-upen la stanza devmbr2). Para entornos dinámicosndppdcon reglaautosobre el/64es más cómodo.
Limitaciones / cuándo NO usar este approach
- OVH HG (NIC única + vRack VLAN): el bridge debe configurarse sobre la subinterfaz tagged, y la dinámica puede diferir. No verificado aquí.
- vRack IPv6 (servicio separado de OVH que enruta un
/56específicamente al vRack): si lo tienes contratado es preferible — las VMs pueden estar directamente envmbr1con un/64propio y sin NDP proxy. Este documento NO cubre ese escenario. - Más de un host con el mismo
/64: el/64IPv6 OVH va enrutado a UN solo MAC. Si quieres HA con failover de IPv6 entre varios servidores necesitas otro patrón (BGP, ULA + NAT66, o IP failover OVH con reasignación manual).
Referencias
- OVH — Configure an IPv6 on a VM — guía oficial OVH (cubre solo el lado guest, no menciona NDP proxy).
- mathieu-gilloots.fr — Installation Proxmox 8 avec IPv6 OVH — referencia detallada del approach NDP proxy con
npd6. - greenhoster.fr — IPv6 dans un vRack OVHcloud — variante con bloque IPv6 vRack
/56. - RFC 5737 y RFC 3849 — rangos reservados para documentación (IPv4 e IPv6).
man ndppd.confy/usr/share/doc/ndppd/ndppd.conf-dist.
Documento generado: 2026-05-23 — Abdelkarim Mateos / AichaDigital
NFS cliente en un sistema linux (rpm o debian)
Descripción
Para montar un cliente NFS, es decir, para que en un sistema podamos montar un path remoto de un servidor NFS necesitamos instalar el cliente NFS.
Atención este artículo es un tip rápido sin entrar en cómo se debe configurar el servidor, ni que puertos abrir en el firewall.
Instalación cliente
Centos 7
yum install nfs-utils; systemctl enable rpcbind; systemctl start rpcbind
Debian
apt-get install portmap nfs-common
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
SSH
SSH es el protocolo que nospermite conectar de forma remota ay segura a nuestra máquinas.
Unable to negotiate with X.X.X.X.X port YY: no matching host key type found. Their offer: ssh-rsa,ssh-dss
Introduccón
Es un extraño error que veces puede acontecer caubndo conectamos a determinados sistemas que han sido actualizados o no, que difieren de la norma general, o entran en conflicto con nuestro cliente SSH por ausencia o defecto de configuración.
Edición y lectura necesaria hasta el final 21/07/2022
ssh root@remotehost -p2244
Unable to negotiate with 99.99.99.99 port 2244: no matching host key type found. Their offer: ssh-rsa,ssh-dss
Con debug
OpenSSH_8.9p1 Ubuntu-3, OpenSSL 3.0.2 15 Mar 2022
debug1: Reading configuration data /home/abkrim/.ssh/config
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: /etc/ssh/ssh_config line 19: include /etc/ssh/ssh_config.d/*.conf matched no files
debug1: /etc/ssh/ssh_config line 21: Applying options for *
debug3: expanded UserKnownHostsFile '~/.ssh/known_hosts' -> '/home/abkrim/.ssh/known_hosts'
debug3: expanded UserKnownHostsFile '~/.ssh/known_hosts2' -> '/home/abkrim/.ssh/known_hosts2'
debug2: resolving "remotehost" port 2244
debug3: resolve_host: lookup remotehost:2244
debug3: ssh_connect_direct: entering
debug1: Connecting to remotehost [99.99.99.99] port 2244.
debug3: set_sock_tos: set socket 3 IP_TOS 0x10
debug1: Connection established.
debug1: identity file /home/abkrim/.ssh/id_rsa type 0
debug1: identity file /home/abkrim/.ssh/id_rsa-cert type -1
debug1: identity file /home/abkrim/.ssh/id_ecdsa type -1
debug1: identity file /home/abkrim/.ssh/id_ecdsa-cert type -1
debug1: identity file /home/abkrim/.ssh/id_ecdsa_sk type -1
debug1: identity file /home/abkrim/.ssh/id_ecdsa_sk-cert type -1
debug1: identity file /home/abkrim/.ssh/id_ed25519 type -1
debug1: identity file /home/abkrim/.ssh/id_ed25519-cert type -1
debug1: identity file /home/abkrim/.ssh/id_ed25519_sk type -1
debug1: identity file /home/abkrim/.ssh/id_ed25519_sk-cert type -1
debug1: identity file /home/abkrim/.ssh/id_xmss type -1
debug1: identity file /home/abkrim/.ssh/id_xmss-cert type -1
debug1: identity file /home/abkrim/.ssh/id_dsa type -1
debug1: identity file /home/abkrim/.ssh/id_dsa-cert type -1
debug1: Local version string SSH-2.0-OpenSSH_8.9p1 Ubuntu-3
debug1: Remote protocol version 2.0, remote software version OpenSSH_5.3
debug1: compat_banner: match: OpenSSH_5.3 pat OpenSSH_5* compat 0x0c000002
debug2: fd 3 setting O_NONBLOCK
debug1: Authenticating to remotehost:2244 as 'root'
debug3: put_host_port: [remotehost]:2244
debug3: record_hostkey: found key type RSA in file /home/abkrim/.ssh/known_hosts:57
debug3: load_hostkeys_file: loaded 1 keys from [remotehost]:2244
debug1: load_hostkeys: fopen /home/abkrim/.ssh/known_hosts2: No such file or directory
debug1: load_hostkeys: fopen /etc/ssh/ssh_known_hosts: No such file or directory
debug1: load_hostkeys: fopen /etc/ssh/ssh_known_hosts2: No such file or directory
debug3: order_hostkeyalgs: prefer hostkeyalgs: rsa-sha2-512-cert-v01@openssh.com,rsa-sha2-256-cert-v01@openssh.com,rsa-sha2-512,rsa-sha2-256
debug3: send packet: type 20
debug1: SSH2_MSG_KEXINIT sent
debug3: receive packet: type 20
debug1: SSH2_MSG_KEXINIT received
debug2: local client KEXINIT proposal
debug2: KEX algorithms: curve25519-sha256,curve25519-sha256@libssh.org,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,sntrup761x25519-sha512@openssh.com,diffie-hellman-group-exchange-sha256,diffie-hellman-group16-sha512,diffie-hellman-group18-sha512,diffie-hellman-group14-sha256,ext-info-c
debug2: host key algorithms: rsa-sha2-512-cert-v01@openssh.com,rsa-sha2-256-cert-v01@openssh.com,rsa-sha2-512,rsa-sha2-256,ssh-ed25519-cert-v01@openssh.com,ecdsa-sha2-nistp256-cert-v01@openssh.com,ecdsa-sha2-nistp384-cert-v01@openssh.com,ecdsa-sha2-nistp521-cert-v01@openssh.com,sk-ssh-ed25519-cert-v01@openssh.com,sk-ecdsa-sha2-nistp256-cert-v01@openssh.com,ssh-ed25519,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521,sk-ssh-ed25519@openssh.com,sk-ecdsa-sha2-nistp256@openssh.com
debug2: ciphers ctos: chacha20-poly1305@openssh.com,aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com
debug2: ciphers stoc: chacha20-poly1305@openssh.com,aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com
debug2: MACs ctos: umac-64-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,hmac-sha1-etm@openssh.com,umac-64@openssh.com,umac-128@openssh.com,hmac-sha2-256,hmac-sha2-512,hmac-sha1
debug2: MACs stoc: umac-64-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,hmac-sha1-etm@openssh.com,umac-64@openssh.com,umac-128@openssh.com,hmac-sha2-256,hmac-sha2-512,hmac-sha1
debug2: compression ctos: none,zlib@openssh.com,zlib
debug2: compression stoc: none,zlib@openssh.com,zlib
debug2: languages ctos:
debug2: languages stoc:
debug2: first_kex_follows 0
debug2: reserved 0
debug2: peer server KEXINIT proposal
debug2: KEX algorithms: diffie-hellman-group-exchange-sha256,diffie-hellman-group-exchange-sha1,diffie-hellman-group14-sha1,diffie-hellman-group1-sha1
debug2: host key algorithms: ssh-rsa,ssh-dss
debug2: ciphers ctos: aes128-ctr,aes192-ctr,aes256-ctr,arcfour256,arcfour128,aes128-cbc,3des-cbc,blowfish-cbc,cast128-cbc,aes192-cbc,aes256-cbc,arcfour,rijndael-cbc@lysator.liu.se
debug2: ciphers stoc: aes128-ctr,aes192-ctr,aes256-ctr,arcfour256,arcfour128,aes128-cbc,3des-cbc,blowfish-cbc,cast128-cbc,aes192-cbc,aes256-cbc,arcfour,rijndael-cbc@lysator.liu.se
debug2: MACs ctos: hmac-md5,hmac-sha1,umac-64@openssh.com,hmac-sha2-256,hmac-sha2-512,hmac-ripemd160,hmac-ripemd160@openssh.com,hmac-sha1-96,hmac-md5-96
debug2: MACs stoc: hmac-md5,hmac-sha1,umac-64@openssh.com,hmac-sha2-256,hmac-sha2-512,hmac-ripemd160,hmac-ripemd160@openssh.com,hmac-sha1-96,hmac-md5-96
debug2: compression ctos: none,zlib@openssh.com
debug2: compression stoc: none,zlib@openssh.com
debug2: languages ctos:
debug2: languages stoc:
debug2: first_kex_follows 0
debug2: reserved 0
debug1: kex: algorithm: diffie-hellman-group-exchange-sha256
debug1: kex: host key algorithm: (no match)
Unable to negotiate with 99.99.99.99 port 24: no matching host key type found. Their offer: ssh-rsa,ssh-dss
Solución
en nuestra fichero ~/.ssh/config (si no existe podemo crearlo) añadimos.
HostKeyAlgorithms ssh-rsa
PubkeyAcceptedKeyTypes ssh-rsa
Problemas
Tras el uso de este tip, al día siguiente aparecio una serie de problemas en el que me fallaban las conexiones a todas mis maquinas via ssh, no pudiendo logearme.
No Kerberos credentials available (default cache: FILE:/tmp/krb5cc_1000)
Tras una busqueda en internet niguna de las opciones me parecia correcta y algo me indicaba que la salida por la tangente de la edición del config de mi cliente ssh era la raíz del problema, desactive las valores indicados.
Y todo volvio a funcionar de nuevo.
Asi que dejo el tip, porque es posible que ayude a alguien, en ambos sentidos, y proque espero tener un hueco (que dificil) para ponerme con este problema y verlo en amplitud.
Agradecimientos
Iba con prisa y no pude pararme mucho, hasta que un dia el problema ya empezo a ser pesado. Gracias How To Configure Custom Connection Options for your SSH Client donde se explica superbien como configurar el fichero ~/.ssh/config por hosts, y cadauno con sus cosas.
En mi caso tenia un fichero para conectarme rápidamente a los mas de 200 servidores que manejo, pero ahora los que me dan problema puedo llamarlos con
sshdirectemente.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
PasswordAuthentication yes pero no funciona
PasswordAuthentication yes pero no funciona
Uno de los problemas de los avances rápidos es que muchas veces pasamos de lego por la lectura de los changelogs. Y este es uno de ellos.
Se instaló el servidor Ubuntu 22.04 sin acceso ssh por contraseña, y una vez instalado se decidió habilitarlo. Nada más fácil que como siempre que añadir o editar la línea PasswordAuthentication yes en el fichero de configuración y reiniciar el servicio SSH.
Pero no, no funciona.
Dos opciones a elegir
Opción 1
Deshabilitar el include a los ficheros en el directorio /etc/ssh/sshd_config.d/ editando el fichero /etc/ssh/sshd_config en la línea que lo incluye # Include /etc/ssh/sshd_config.d/*.conf
Opción 2
Editar el fichero que contiene la línea PasswordAuthentication no ya que como norma general el include está al final, por lo que los valores existentes son sustituidos por los que existan en estos ficheros, cambiandolo por PasswordAuthentication yes
Esta es mala praxis pues el objeto de este método es sencillo, evitar que en las actualizaciones dejemos de lado la actualización de los ficheros de configuración, para no destruir nuestros cambios. Mucho mejor, usar este aprovechamiento, para poner nuestros valores en aquellas configuraciones existentes, que como norma general, no recibirán cambios.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Cambiar el puerto SSH en Ubuntu 24.04 y Debian Bookworm
Introducción
Cada un tiempo salen cambios, y en la época que vivimos son muy a menudo, y alguno, incluso olvidamos los tiempos de Slackware o mas duro aun, una Gentoo o un Linux From Scratch.
Uno de esos cambios que viene en las ultimas estables de Debian y derivados es uno que puede despistarte con el cambio de puerto para SSH.
En el caso de Redhat/CentOs y derivadas el lío sería otro pero también existe.
Cambiar el puerto SSH en Ubuntu 24.04 /Debian Bookworn
Debian puede variar algo, pero la idea es la misma.
La cuestión esta en que al margen de el cambio de la clave Port al puerto deseado en el fichero /etc/ssh/sshd_config necesitamos unos pasos adicionales.
Si echamos una vista al systemd de nuestra distro Ubuntu vemos dos entradas para ssh siendo la interesante /etc/systemd/system/ssh.service.requires
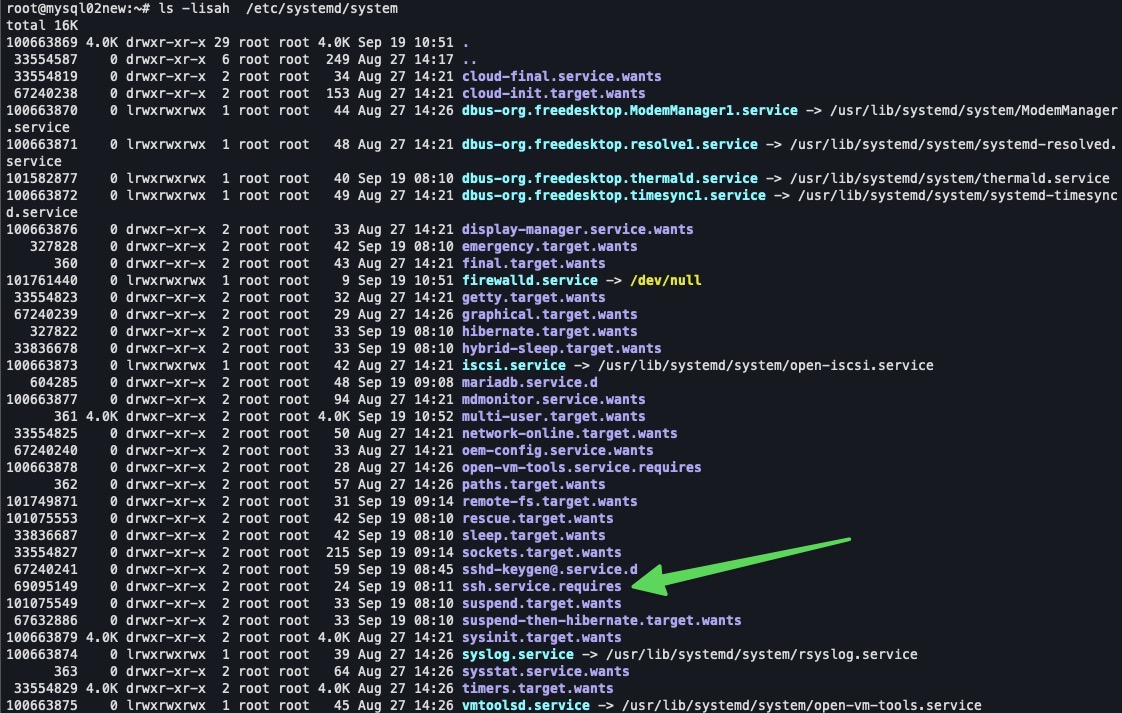

Editemos /etc/systemd/system/ssh.service.requires/ssh.socket
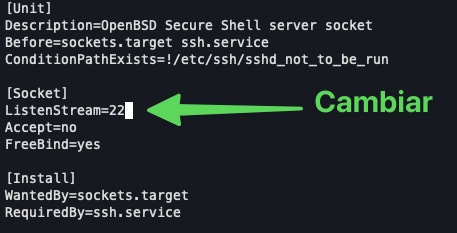
Y despues editemos /etc/ssh/sshd_config
Port 0000 # 0000 es el número del puerto deseado y libre
Así que se trata de editar la clave ListenStream con el mismo puerto que hemos puesto en la configuración de SSHD.
No olvides que esto es después de que al cambiar el valor de
Portno te funcione 😊
Después es lo habitual en systemd por que hay que hacer un reload tras los cambios en systemd
systemctl daemon-reload
systemctl restart ssh
No olvides el firewall 😊😊😊
Cambiar también en SSHD (Editado: 6/3/25)
Algunos me han preguntado, y si es cierto que también hay que cambiar el puerto en el fichero /etc/ssh/sshd_conf
Port XXXXX
Compatibilidad con Ubuntu 22.04 (Editado: 18/07/25)
Ubuntu 22.04 incluye soporte completo para ambos métodos pero usa el servicio tradicional por defecto.
Verificar tu configuración actual
systemctl status ssh.socket
Si muestra "inactive (dead)": Usas el método tradicional
En este caso solo necesitas:
# Editar configuración SSH
sudo nano /etc/ssh/sshd_config
# Cambiar: Port 2222
# Reiniciar servicio
sudo systemctl restart ssh.service
# Verificar
sudo ss -tlnp | grep :2222
Para migrar a formato socket (recomendado para consistencia)
# Verificar archivos disponibles
ls -la /lib/systemd/system/ssh*
# Migrar a socket systemd
sudo systemctl stop ssh.service
sudo systemctl disable ssh.service
# Configurar socket con puerto personalizado
sudo systemctl edit ssh.socket
Añadir en el editor:
[Socket]
ListenStream=
ListenStream=2222
# Editar configuración SSH
sudo nano /etc/ssh/sshd_config
# Port 2222
# Activar socket
sudo systemctl daemon-reload
sudo systemctl enable ssh.socket
sudo systemctl start ssh.socket
# Verificar migración exitosa
sudo systemctl status ssh.socket
sudo ss -tlnp | grep :2222
Ventaja de la migración: Consistencia con Ubuntu 24.04+ y mejor gestión de recursos.
Agradecimientos
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Apagando fuegos
A veces hay cosas que son propias de un bombero de sistemas
Kernel panic: /init: conf/conf.d/zz-resume-auto: line 1: syntax error: unexpected "("
Introducción
Nada peor que un kernel panic en un sistema linux y más si este esta en producción.
Que malo es tener servidores baremetal en lugar de virtualizar con KVM. Sonbre todo para el corazón.
Me llamo un cliente, para apagar el fuego. Centralita de rendimiento espectacular (Dos a tres mil euros la hora de facturación por lineas). Como parta estar offline. E infraestructura sin HA o cuando menos espejos de backup.
Ya me han pedido presupuesto.
Lo primero que se observa en Google o DuckDuckGo es que es un problema recurrente con distintos sabores o variantes.
Pero lo que nos queda claro es que no se trata de encontrar ese fichero sino de otra cosa.
Estamos en OVH así que vamos a abrir un IPMI para tratar de entrar en modo rescate.
Al rescate
Consola remota IPMI de OVH
Bueno la ilusión se nos fue, cuando vimos que el administrador del equipo, tenia configurado de tal forma no visualizar el screen de arranque, sino entrar directamente al trapo con la carga del kernel (Muy mal compañero).
Tampoco el IPMI nos permitía una comunicación correcta del teclado, para forzar la pantalla de inicio, asi que opte por un arranque en modo rescue de OVH basado en una Debian 11.
Modo rescue
Lo primero es ver que tenemos con un fdisk
root@rescue-customer-eu ~# fdisk -l
/dev/nvme0n1p1 2048 1048575 1046528 511M EFI System
/dev/nvme0n1p2 1048576 999161855 998113280 476G Linux RAID
/dev/nvme0n1p3 999161856 1000210431 1048576 512M Linux filesystem
/dev/nvme0n1p4 1000211120 1000215182 4063 2M Linux filesystem
Que bonito, un RAID por software en un sistema en producción de ese nivel.
Vemos que nos cuenta
root@rescue-customer-eu ~ # mdadm --examine --scan
ARRAY /dev/md/md2 metadata=1.2 UUID=f3f612c5:98f99127:fd587ee0:8dc97d19 name=md2
root@rescue-customer-eu ~ # mount /dev/md/md2 /mnt
mount: /mnt: special device /dev/md/md2 does not exist.
Limpieza con update-initramfs
Bien, vamos a montarlo en modo chroot para poder limpiar el problema
root@rescue-customer-eu ~ # cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [multipath] [faulty]
md127 : active (auto-read-only) raid1 nvme0n1p2[1]
498924544 blocks super 1.2 [2/1] [_U]
bitmap: 4/4 pages [16KB], 65536KB chunk
unused devices: <none>
¿Porqué?
Basado en la salida de cat /proc/mdstat, parece que el dispositivo RAID que se ha ensamblado automáticamente al intentar arrancar el sistema en modo rescate es /dev/md127 y no /dev/md/md2 como se esperaba inicialmente. Esto puede suceder a veces, donde el número de dispositivo RAID puede cambiar dependiendo de cómo y cuándo se ensambla el RAID durante el arranque del sistema.
La salida muestra que el dispositivo /dev/md127 es un RAID 1 (espejo) y actualmente está en modo "auto-read-only" con uno de los dos discos funcionando (indicado por [2/1] [_U], donde _U significa que un disco está faltante o no está funcionando).
Problemas a la vista con el raid. Continuar con algunas propuestas no tiene sentido, cuando el raid esta mal, pues se trata de trabajar con el grub y sin el raid consistente, ni lo intentes.
update-grub
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.10.0-28-amd64
Found initrd image: /boot/initrd.img-5.10.0-28-amd64
/usr/sbin/grub-probe: error: disk `mduuid/f3f612c598f99127fd587ee08dc97d19' not found.
/usr/sbin/grub-probe: error: disk `mduuid/f3f612c598f99127fd587ee08dc97d19' not found.
/usr/sbin/grub-probe: error: disk `mduuid/f3f612c598f99127fd587ee08dc97d19' not found.
Found linux image: /boot/vmlinuz-5.10.0-27-amd64
Found initrd image: /boot/initrd.img-5.10.0-27-amd64
/usr/sbin/grub-probe: error: disk `mduuid/f3f612c598f99127fd587ee08dc97d19' not found.
/usr/sbin/grub-probe: error: disk `mduuid/f3f612c598f99127fd587ee08dc97d19' not found.
Found linux image: /boot/vmlinuz-5.10.0-19-amd64
Found initrd image: /boot/initrd.img-5.10.0-19-amd64
/usr/sbin/grub-probe: error: disk `mduuid/f3f612c598f99127fd587ee08dc97d19' not found.
/usr/sbin/grub-probe: error: disk `mduuid/f3f612c598f99127fd587ee08dc97d19' not found.
done
En este punto decir que algunos de los tips de google, sobre este tema, podrán ser validos en determinadas circunstancias pero aquí, con un raid por software la cosa estaba más clara.
Vamos a ensamblar manualmente el array.
ATENCION ⚠️ Lo que se hace, se hace en una máquina con backups, y consciente de lo que haces y de que puede pasar de todo. No soy responsable delos copy & paste sin tener ni idea de sistemas.
mdadm --assemble /dev/md/md2 --uuid f3f612c5:98f99127:fd587ee0:8dc97d19
Después vamos a ver el estado. Es necesario porque lo que haremos después no funcionaria, por los errores que ya tuvimos.
root@rescue-customer-eu:/# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [multipath] [faulty]
md127 : active raid1 nvme1n1p2[0] nvme0n1p2[1]
498924544 blocks super 1.2 [2/1] [_U]
[===>.................] recovery = 19.6% (98150912/498924544) finish=32.4min speed=205769K/sec
bitmap: 4/4 pages [16KB], 65536KB chunk
Bien esperaremos hasta que acabe
Si tienes un gran tamaño de discos, tardará. Si tienes discos mecanicos, y raid soft, mejor date una vuelta.
Montemos en chroot cuando termine.
mount /dev/md127 /mnt
mount -t proc /proc /mnt/proc
mount -t sysfs /sys /mnt/sys
mount --rbind /dev /mnt/dev
mount --make-rslave /mnt/dev
chroot /mnt /bin/bash
Ahora ya puedes hacer un update-grub o editar el fichero por ejemplo para tener la venta splash del arranque para poder elegir un kernel o el modo rescue, etc.
En mi caso sirvió el update-grub
update-grub
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.10.0-28-amd64
Found initrd image: /boot/initrd.img-5.10.0-28-amd64
Found linux image: /boot/vmlinuz-5.10.0-27-amd64
Found initrd image: /boot/initrd.img-5.10.0-27-amd64
Found linux image: /boot/vmlinuz-5.10.0-19-amd64
Found initrd image: /boot/initrd.img-5.10.0-19-amd64
done
Si estas en un entorno UEFI de arranque, tendrás que asegurarte. de que estas apuntando correctamente
Desmontado
exit
umount /mnt/sys
umount /mnt/proc
umount /mnt/dev
umount /mnt/boot
Y finalmente desactivar el kernel rescue de OVH y hacer un shutdown.
In Sha Allah... y a disfrutar de tu máquina.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
your CPU is missing AVX instruction set flag para instalar mongoDb Jetbackup entre otros
Introducción
A veces, como administrador de sistemas, me sorprende la dirección que está tomando el software de uso común, comenzando a enfrentar los mismos problemas que JavaScript y otros lenguajes para cumplir con expectativas inusuales.
Lo menciono porque tener que depender de ciertos conjuntos de instrucciones del procesador y habilidades de hardware específicas del modelo de procesador empieza a complicar las cosas.
En el caso presentado, se trata de un problema para la instalación de Jetbackup (ver comentario) que requiere MongoDB, el cual necesita las banderas AVX.
Con Jetbackup ya me he llevado unas cuantas sorpresas, como por ejemplo que se "olvida" indicar claramente en la zona de venta qué sistemas operativos están soportados como destino. Entre otras cosas, BusyBox no es compatible con rsync, aunque decían que lo era con SFTP y tampoco lo es.
Proxmox y su virtualización
En mi caso, era un servidor VPS sobre un Proxmox con 48 x AMD EPYC 7413 24-Core Processor, relativamente moderno, que sí tiene dichas instrucciones:
grep -o 'avx' /proc/cpuinfo
avx
avx
...
## Una linea más por cada core
Asi que teniendo una versión de Proxmox 7.2.14 me limite a usar cpu: host en el modelo de procesador del KVM.
root@ cat /etc/pve/qemu-server/<KVM_ID>.conf | grep host
cpu: host
En versiones más modernas de Proxmox, puedes usar en este caso EPYC-v3 (disponible en el desplegable de Procesadores de una KVM), que se ajustaría mejor.
Desde hace 15 años que uso Proxmox dejé de actualizarlo. Lo tengo cerrado por firewall completamente (denegar todo y autorizar lo necesario por IP) y cada dos años cambio la máquina y con el cambio la versión. Ya me llevé muchos disgustos con las actualizaciones.
Aviso
Esta documentación y su contenido no implican que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido se entrega tal y como está, sin ninguna obligación ni responsabilidad por parte de Castris.
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Nginx
Nginx, para servidores con multiples vhosts a pelo (sin panel) + PHP-FPM
Nginx
Instalado de forma oficial siguiendo la ruta de instalación estándar de Ubuntu.
Mejoras sobre la configuración original
A continuación se describen las mejoras implementadas sobre la configuración estándar. Estas optimizaciones se centran en:
- Reducción del TTFB (Time To First Byte)
- Refuerzo de seguridad (especialmente en ciphers)
- Optimización de rendimiento general
Las directivas que comienzan con # comentario son personalizaciones, ya sea por adición o modificación.
user www-data;
worker_processes auto;
worker_rlimit_nofile 65535; # Incrementa el límite de archivos abiertos
# load_module modules/ngx_http_modsecurity_module.so;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
include /etc/nginx/modules-enabled/*.conf;
# Configuración optimizada de eventos
events {
worker_connections 1024;
use epoll; # Método eficiente para Linux
multi_accept on; # Acepta múltiples conexiones por proceso
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
## Mejoras de rendimiento y seguridad probadas durante años
sendfile on; # Optimiza el envío de archivos
tcp_nopush on; # Optimiza paquetes TCP
tcp_nodelay on; # Reduce latencia
client_header_timeout 60s; # Tiempo máximo para recibir cabeceras
client_body_timeout 60s; # Tiempo máximo para recibir cuerpo
client_header_buffer_size 2k; # Tamaño del buffer para cabeceras
client_body_buffer_size 256k; # Tamaño del buffer para el cuerpo
client_max_body_size 256m; # Tamaño máximo de petición
large_client_header_buffers 4 8k; # Buffers para cabeceras grandes
send_timeout 60s; # Tiempo máximo de envío
keepalive_timeout 30s; # Tiempo máximo de conexión persistente
reset_timedout_connection on; # Libera conexiones que expiran
server_tokens off; # Oculta la versión de Nginx
server_name_in_redirect off; # No incluye nombre del servidor en redirecciones
server_names_hash_max_size 512; # Tamaño máximo de la tabla hash
server_names_hash_bucket_size 512; # Tamaño del bucket hash
# Compresión para optimizar el tráfico
gzip on; # Activa la compresión
gzip_static on; # Busca versiones pre-comprimidas
gzip_vary on; # Añade cabecera Vary
gzip_comp_level 6; # Nivel de compresión (equilibrio rendimiento/tamaño)
gzip_min_length 1024; # Tamaño mínimo para comprimir
gzip_buffers 16 8k; # Buffers para compresión
gzip_types text/plain text/css text/javascript text/js text/xml application/json application/javascript application/x-javascript application/xml application/xml+rss application/x-font-ttf image/svg+xml font/opentype;
gzip_proxied any; # Comprime respuestas proxy
gzip_disable "MSIE [1-6]\."; # Desactiva para IEs antiguos
# Configuración de proxy
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass_header Set-Cookie;
proxy_buffers 32 4k;
proxy_connect_timeout 30s;
proxy_send_timeout 90s;
proxy_read_timeout 90s;
# Configuración para Cloudflare (actualizada: 28/09/2023)
# Permite identificar la IP real del visitante detrás de Cloudflare
set_real_ip_from 103.21.244.0/22;
set_real_ip_from 103.22.200.0/22;
set_real_ip_from 103.31.4.0/22;
set_real_ip_from 104.16.0.0/13;
set_real_ip_from 104.24.0.0/14;
set_real_ip_from 108.162.192.0/18;
set_real_ip_from 131.0.72.0/22;
set_real_ip_from 141.101.64.0/18;
set_real_ip_from 162.158.0.0/15;
set_real_ip_from 172.64.0.0/13;
set_real_ip_from 173.245.48.0/20;
set_real_ip_from 188.114.96.0/20;
set_real_ip_from 190.93.240.0/20;
set_real_ip_from 197.234.240.0/22;
set_real_ip_from 198.41.128.0/17;
#set_real_ip_from 2400:cb00::/32; # IPv6 (comentados por compatibilidad)
#set_real_ip_from 2606:4700::/32;
#set_real_ip_from 2803:f800::/32;
#set_real_ip_from 2405:b500::/32;
#set_real_ip_from 2405:8100::/32;
#set_real_ip_from 2c0f:f248::/32;
#set_real_ip_from 2a06:98c0::/29;
real_ip_header CF-Connecting-IP;
# Configuración SSL que cumple con PCI Compliance
# Basado en https://blog.ss88.us/secure-ssl-https-nginx-vestacp
ssl_protocols TLSv1.2 TLSv1.3; # Elimina protocolos obsoletos (SSLv3)
ssl_prefer_server_ciphers on;
ssl_session_cache shared:SSL:10m;
ssl_ciphers "EECDH+ECDSA+AESGCM EECDH+aRSA+AESGCM EECDH+ECDSA+SHA384 EECDH+ECDSA+SHA256 EECDH+aRSA+SHA384 EECDH+aRSA+SHA256 EECDH+aRSA+RC4 EECDH EDH+aRSA RC4 !aNULL !eNULL !LOW !3DES !MD5 !EXP !PSK !SRP !DSS !MEDIUM";
#ssl_ciphers ECDHE-RSA-AES256-GCM-SHA512:DHE-RSA-AES256-GCM-SHA512:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384;
ssl_dhparam dh4096.pem;
ssl_ecdh_curve secp384r1;
ssl_session_tickets off;
ssl_stapling on;
ssl_stapling_verify on;
resolver 1.1.1.1 8.8.8.8 valid=300s;
resolver_timeout 5s;
add_header Strict-Transport-Security "max-age=63072000; includeSubdomains; preload";
add_header X-Frame-Options SAMEORIGIN;
add_header X-Content-Type-Options nosniff;
# Configuración de caché
# IMPORTANTE: Verificar permisos y propiedad de los directorios
# Especialmente útil en entornos con alta carga de solicitudes
proxy_cache_path /var/cache/nginx levels=2 keys_zone=cache:10m inactive=60m max_size=1024m;
proxy_cache_key "$host$request_uri $cookie_user";
proxy_temp_path /var/cache/nginx/temp;
proxy_ignore_headers Expires Cache-Control;
proxy_cache_use_stale error timeout invalid_header http_502;
proxy_cache_valid any 1d;
# Bypass de caché para sesiones activas
map $http_cookie $no_cache {
default 0;
~SESS 1;
~wordpress_logged_in 1;
}
# Configuración de caché de archivos
open_file_cache max=10000 inactive=30s;
open_file_cache_valid 60s;
open_file_cache_min_uses 2;
open_file_cache_errors off;
# Configuración de cabeceras y expiración
# Mapa de tiempos de expiración según tipo de contenido
map $sent_http_content_type $expires {
default off;
text/html epoch; # No cachear HTML (dinámico)
text/css max; # Cachear CSS al máximo
application/javascript max; # Cachear JS al máximo
~image/ max; # Cachear imágenes al máximo
}
##
# Configuración de Hosts Virtuales
##
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
Permisos y propiedad del caché de Nginx
Para que Nginx funcione correctamente con la configuración de caché definida, los directorios implicados deben tener los permisos y propiedad adecuados:
Propiedad (Owner y Grupo)
-
Propietario: El usuario con el que se ejecuta Nginx (típicamente
www-dataen Ubuntu) -
Grupo: El grupo correspondiente (típicamente
www-dataen Ubuntu)
Permisos recomendados
-
/var/cache/nginx: 750 (drwxr-x---) -
/var/cache/nginx/temp: 750 (drwxr-x---)
Comandos para establecer estos permisos
# Crear los directorios si no existen
mkdir -p /var/cache/nginx/temp
# Establecer la propiedad correcta
chown -R www-data:www-data /var/cache/nginx
# Establecer los permisos adecuados
chmod 750 /var/cache/nginx
chmod 750 /var/cache/nginx/temp
Estos permisos garantizan que los directorios sean accesibles únicamente por el usuario que ejecuta Nginx, mejorando la seguridad del sistema al evitar accesos no autorizados a posible información sensible almacenada en caché.
Configuración de los Virtual Hosts
Existen dos enfoques para gestionar los archivos de configuración de hosts virtuales:
1. Enfoque centralizado (recomendado para entornos de producción)
Los archivos de configuración se colocan en /etc/nginx/sites-available/ y se enlazan simbólicamente a /etc/nginx/sites-enabled/:
ln -s /etc/nginx/sites-available/domain.tld.conf /etc/nginx/sites-enabled/
Ventajas:
- Mayor control y seguridad
- Centralización de configuraciones
- Facilita auditorías de seguridad
- Previene cambios accidentales por usuarios sin privilegios
2. Enfoque por usuario (útil en entornos único administrador)
Los archivos se colocan en directorios de usuario y se enlazan a la configuración principal.
Limitaciones:
- Los usuarios sin acceso
sudono podrán:- Validar configuraciones con
nginx -t - Recargar el servicio con
systemctl reload nginx - Reiniciar el servicio con
systemctl restart nginx
- Validar configuraciones con
Configuración inicial (pre-certificado)
Antes de obtener el certificado SSL, se debe crear un archivo de configuración sin asignación específica de puertos. Certbot (Let's Encrypt) se encargará de esto durante el proceso de certificación.
Ejemplo:
server {
server_name domain.tld www.domain.tld;
root /home/user/web/domain.tld/domain/dist; # Ruta para despliegues JS/VUE/React
index index.html;
# Es ALTAMENTE RECOMENDABLE activar estas cabeceras de seguridad
add_header X-Frame-Options "SAMEORIGIN";
add_header X-Content-Type-Options "nosniff";
charset utf-8;
## Logs ubicados en la carpeta del usuario para facilitar su acceso
access_log /home/user/logs/web/domain.tld.log combined;
error_log /home/user/logs/web/domain.tld.error.log error;
expires $expires; # Utiliza la variable map definida en nginx.conf
# Si has compilado y tienes operativo mod_security, descomenta la línea siguiente
# include /etc/nginx/modsec/active.conf;
location = /favicon.ico {
log_not_found off;
access_log off;
}
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
#error_page 404 /index.php;
location / {
root /home/user/web/domain.tld/domain/dist/;
index index.html;
try_files $uri $uri/ /index.html; # Configuración para SPAs (React, Vue, etc.)
#try_files $uri $uri/ =404; # Alternativa para sitios estáticos
location ~* ^.+\.(jpeg|jpg|png|gif|bmp|ico|svg|css|js)$ {
access_log off;
log_not_found off;
expires max;
}
}
# Bloqueo de archivos de configuración sensibles
location ~* "/\.(htaccess|htpasswd|env)$" {
deny all;
return 404;
}
# Bloqueo de archivos y directorios ocultos
location ~ /\.(?!well-known).* {
deny all;
}
}
Configuración de la variable $expires
Esta variable se declara mediante la directiva map en el archivo nginx.conf. Si no está declarada, su uso generará un error.
map $sent_http_content_type $expires {
default off;
text/html epoch; # No cachear HTML (fecha 1/1/1970)
text/css max; # Cachear CSS al máximo
application/javascript max; # Cachear JS al máximo
~image/ max; # Cachear imágenes al máximo
}
Buena práctica: Después de cada modificación, ejecutar
nginx -tpara verificar la sintaxis de la configuración antes de recargar el servicio.
Certificados con Certbot
Certbot ya viene instalado en la mayoría de distribuciones modernas. Para nuevas instalaciones, su manual oficial proporciona instrucciones detalladas.
Se recomienda crear certificados específicos por dominio en lugar de certificados wildcard:
certbot --nginx -d domain.tld -d www.domain.tld
Nota: En sistemas con restricciones de red, es necesario abrir temporalmente los puertos 80 y 443 durante el proceso de renovación.
PHP
Instalado desde el repositorio de Ondrej Surý, específicamente la versión PHP-FPM.
Ubicaciones importantes:
- Configuración de pools:
/etc/php/X.X/fpm/pool.d/www.conf(donde X.X es la versión de PHP) - Configuración general:
/etc/php/X.X/fpm/php.ini
Configuración crítica para logging
Es esencial modificar la configuración del pool para activar el registro de errores:
- Editar
/etc/php/X.X/fpm/pool.d/www.confy cambiar:catch_workers_output = yes
Sin esta modificación, PHP-FPM no registrará correctamente los errores en los logs de los dominios virtuales, lo que puede dificultar enormemente la depuración. Para más información, consulte PHP log cuando usamos PHP-FPM con host virtuales.
JIT Compiler
PHP 8.x introduce el compilador JIT (Just-In-Time), que puede mejorar significativamente el rendimiento en determinados escenarios. Sin embargo, puede presentar desafíos durante el desarrollo activo con cambios frecuentes.
Para más información sobre la activación y configuración del JIT, consulte Activar PHP8.2 JIT Compiler.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Gestión de Versiones de PHP en Raspberry Pi
Contexto
Cuando tienes múltiples versiones de PHP instaladas en tu Raspberry Pi (especialmente usando el repositorio de Ondrej), necesitas poder cambiar entre ellas según los requisitos de cada proyecto.
Verificación inicial
Antes de configurar cualquier opción, verifica el estado actual:
# Ver versiones de PHP instaladas
ls /usr/bin/php*
# Ver paquetes PHP instalados
apt list --installed | grep php
# Verificar versión actual
php -v
Ejemplo: Instalación de PHP 8.3 (si no está presente)
Es un ejemplo, no es para un copy & paste
# Actualizar repositorios
sudo apt update
# Instalar PHP 8.3 y módulos esenciales
sudo apt install php8.3 php8.3-cli php8.3-common php8.3-curl php8.3-mbstring php8.3-mysql php8.3-xml
# Extensiones adicionales comunes
sudo apt install php8.3-gd php8.3-zip php8.3-intl php8.3-bcmath php8.3-sqlite3
Opción 1: Cambio Global con update-alternatives
Descripción
Cambia la versión predeterminada de PHP para todo el sistema usando el sistema de alternativas de Debian.
Configuración
# Registrar las versiones disponibles
sudo update-alternatives --install /usr/bin/php php /usr/bin/php8.3 83
sudo update-alternatives --install /usr/bin/php php /usr/bin/php8.4 84
# Seleccionar la versión deseada
sudo update-alternatives --config php
Uso
# Cambiar versión interactivamente
sudo update-alternatives --config php
# Verificar cambio
php -v
Ventajas
- Cambio persistente entre sesiones
- Fácil de cambiar cuando necesites
- Afecta a todos los scripts y herramientas que usan
php
Desventajas
- Cambio global afecta todo el sistema
- Puede romper scripts que dependen de una versión específica
- Requiere privilegios administrativos
Opción 2: Configuración por Sesión/Proyecto
Descripción
Configura temporalmente una versión específica de PHP solo para la sesión actual o proyecto específico.
Método A: Alias temporal
# Crear alias para la sesión actual
alias php='/usr/bin/php8.3'
# Verificar
php -v
# El alias se pierde al cerrar la terminal
Método B: Script de configuración de proyecto
Crea un archivo setup-php.sh en tu directorio de proyecto:
#!/bin/bash
# setup-php.sh
echo "Configurando entorno PHP 8.3 para el proyecto"
# Crear aliases temporales
alias php='php8.3'
alias composer='php8.3 /usr/local/bin/composer'
# Verificar configuración
echo "Versión PHP activa:"
php8.3 -v
# Opcional: exportar variables de entorno
export PHP_VERSION=8.3
export PHP_BINARY=/usr/bin/php8.3
# Iniciar shell con configuración
bash
Uso:
# Ejecutar el script de configuración
source ./setup-php.sh
# O hacer ejecutable y ejecutar
chmod +x setup-php.sh
./setup-php.sh
Método C: Configuración en .bashrc del proyecto
# En el directorio del proyecto, crear .bashrc local
echo 'alias php="php8.3"' > .bashrc
echo 'alias composer="php8.3 /usr/local/bin/composer"' >> .bashrc
# Cargar configuración
source .bashrc
Ventajas
- No afecta el sistema globalmente
- Configuración específica por proyecto
- Fácil de revertir
Desventajas
- Configuración temporal (se pierde al cerrar terminal)
- Requiere configuración manual para cada proyecto
- Puede ser inconsistente entre sesiones
Opción 3: Uso Directo de Versión Específica
Descripción
Usa directamente los ejecutables específicos de cada versión sin cambiar configuraciones globales.
Uso en scripts
# En lugar de usar 'php', usar directamente la versión
php8.3 script.php
# Para servidor de desarrollo
php8.3 -S localhost:8000
# Para composer
php8.3 /usr/local/bin/composer install
Configuración de shebang en scripts PHP
#!/usr/bin/php8.3
<?php
// Tu código aquí
Crear wrapper scripts
Crea un directorio para scripts wrapper:
# Crear directorio para wrappers
mkdir -p ~/bin
# Crear wrapper para PHP 8.3
cat > ~/bin/php83 << 'EOF'
#!/bin/bash
exec /usr/bin/php8.3 "$@"
EOF
# Hacer ejecutable
chmod +x ~/bin/php83
# Añadir al PATH (en ~/.bashrc)
echo 'export PATH="$HOME/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
Uso:
# Usar wrapper
php83 script.php
php83 -S localhost:8000
Ventajas
- Control total sobre qué versión usar
- No requiere configuración global
- Explícito y claro en scripts
Desventajas
- Más verboso
- Necesitas recordar usar la versión correcta
- Herramientas como Composer pueden requerir configuración adicional
Recomendaciones por Caso de Uso
Para desarrollo personal con un proyecto principal
Usar Opción 1 (update-alternatives)
- Cambio fácil y persistente
- Bueno cuando trabajas principalmente con una versión
Para múltiples proyectos con diferentes versiones
Usar Opción 2 (configuración por proyecto)
- Flexibilidad máxima
- Cada proyecto mantiene su configuración
Para scripts de producción o automatización
Usar Opción 3 (uso directo)
- Máxima claridad y control
- Sin dependencias de configuración del sistema
Verificación y Troubleshooting
# Verificar versión activa
php -v
# Verificar módulos instalados
php -m
# Verificar configuración de PHP
php --ini
# Ver todas las versiones disponibles
ls -la /usr/bin/php*
# Verificar composer con versión específica
php8.3 /usr/local/bin/composer --version
Notas Importantes
-
Módulos y extensiones: Cada versión de PHP tiene sus propios módulos. Asegúrate de instalar las extensiones necesarias para cada versión.
-
Composer: Si usas Composer, puede necesitar configuración específica:
# Reinstalar composer para PHP 8.3 php8.3 -r "copy('https://getcomposer.org/installer', 'composer-setup.php');" php8.3 composer-setup.php -
Servidor web: Si usas Apache o Nginx, la configuración del servidor web es independiente de la versión de CLI.
-
Herramientas de desarrollo: IDEs y editores pueden necesitar configuración específica para reconocer la versión correcta.
Esta documentación te permitirá elegir la estrategia más adecuada según tus necesidades específicas de desarrollo.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Configuración correcta de Let's Encrypt en Webmin con
Problema común tras instalación de Webmin
Webmin puede venir con certificados SSL preconfigurados (autofirmados) que interfieren con la configuración correcta de Let's Encrypt, causando errores como:
Unable to change the --key-type of this certificate because --reuse-key is set
Diagnóstico inicial
1. Verificar certificados existentes
certbot certificates
2. Identificar conflictos en Webmin
- Ir a Webmin Configuration → SSL Encryption
- Verificar si hay certificados autofirmados que no se pueden eliminar desde la interfaz
Solución paso a paso
Paso 1: Limpieza desde línea de comandos
Si existe un certificado conflictivo, eliminarlo completamente:
# Listar certificados actuales
certbot certificates
# Eliminar certificado problemático (reemplazar con tu dominio)
certbot delete --cert-name tu-dominio.com
Importante: Certbot preguntará confirmación. Responder Y para continuar.
Paso 2: Configuración en Webmin
- Ir a Webmin Configuration → SSL Encryption
- Seleccionar "Let's Encrypt certificate"
- Método de validación crítico: Seleccionar "Certbot built-in webserver"
- Esta opción es más robusta
- Evita conflictos de directorio
- Maneja automáticamente puertos 80/443
- Introducir tu dominio
- Hacer click en "Request Certificate"
Paso 3: Verificación
# Verificar que el certificado se creó correctamente
certbot certificates
# Verificar que Webmin está usando el certificado correcto
systemctl status webmin
¿Por qué "Certbot built-in webserver"?
Ventajas sobre "Other webserver document directory":
- Sin conflictos de directorio: No depende de configuraciones de Apache/Nginx
- Control total: Certbot maneja temporalmente los puertos necesarios
- Más limpio: Evita interferencias con otros servicios web
- Mayor éxito: Funciona incluso cuando hay configuraciones SSL complejas
Desventajas:
- Downtime mínimo: Detiene temporalmente el servicio web (segundos)
- Puertos requeridos: Necesita acceso libre a puertos 80 y 443
Configuración de renovación automática
Months between automatic renewal 2
Renovación manual
# Forzar renovación (si faltan menos de 30 días)
certbot renew --force-renewal
# Renovación específica de un dominio
certbot certonly --standalone -d tu-dominio.com --force-renewal
Mejores prácticas
Antes de solicitar certificado:
- DNS configurado: Asegurar que el dominio apunta al servidor
- Firewall: Puertos 80 y 443 abiertos
- Limpieza: Eliminar certificados conflictivos
Configuración recomendada:
- Método: Certbot built-in webserver
- Renovación: Automática (certbot.timer)
- Monitoreo: Verificar expiración mensualmente
Comandos de verificación regular:
# Estado general
certbot certificates
# Próximas renovaciones
certbot renew --dry-run
# Logs de renovación
tail -f /var/log/letsencrypt/letsencrypt.log
Última actualización: Septiembre 2025
Testeado en: Webmin 2.x, Ubuntu/Debian
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Cosas de relays y postfix
Usado en muchos de mis sistemas, aqui algunos tips para smart y postfix
Postfix Smart Relay en casos de bloqueo puerto 25 - Configuración Completa
Escenario
Servidor sin panel de control que necesita enviar correos electrónicos (alertas, notificaciones) pero tiene el puerto 25 bloqueado por el ISP (Hetzner). Solución mediante smart relay a otro servidor Postfix actuando como gateway de salida.
Configuración Postfix Smart Relay - Puerto 25 Bloqueado
Escenario
Servidor sin panel de control que necesita enviar correos electrónicos (alertas, notificaciones) pero tiene el puerto 25 bloqueado por el ISP (Hetzner). Solución mediante smart relay a otro servidor Postfix actuando como gateway de salida.
Arquitectura
[Servidor Origen] --puerto 587--> [Smart Relay] --puerto 25--> [Internet]
(puerto 25 capado) (múltiples ubicaciones)
Configuración del Servidor Origen (Cliente)
1. Instalación básica
apt-get install postfix mailutils
2. Configuración main.cf
# /etc/postfix/main.cf
# ⚠️ CRÍTICO: Verificar sintaxis exacta - errores tipográficos causan bucles
myhostname = alerts.tudominio.com
mydomain = tudominio.com
myorigin = alerts.tudominio.com # Debe coincidir exactamente con DKIM
# Smart relay
relayhost = [ip-smart-relay]:587
# Configuración local mínima
inet_interfaces = loopback-only
mydestination = localhost, localhost.localdomain
local_recipient_maps =
local_transport = error:local mail delivery is disabled
# ⚠️ IMPORTANTE: Incluir TODAS las IPs que pueden enviar bounces
mynetworks = 127.0.0.0/8 [::1]/128 [IP-smart-relay]
# TLS para conexión al smart relay
smtp_use_tls = yes
smtp_tls_security_level = encrypt
# ⚠️ NUEVO: Transport maps para evitar bucles de bounces
transport_maps = hash:/etc/postfix/transport
3. Transport maps (CRÍTICO para evitar bucles)
# /etc/postfix/transport
# Mantener correos hacia el propio dominio locales para evitar bucles
alerts.tudominio.com local:
# Compilar
postmap /etc/postfix/transport
4. Aliases básicos
# /etc/aliases
root: sysadmin@tudominio.com
postmaster: sysadmin@tudominio.com
# Usuario para descartar bounces automáticos
devnull: /dev/null
# Aplicar cambios
newaliases
postfix reload
Configuración del Smart Relay
1. Configuración main.cf del smart relay
# /etc/postfix/main.cf
# Configuración básica
myhostname = smart-relay.tudominio.com
mydomain = tudominio.com
# ⚠️ CRÍTICO: Permitir relay desde IPs específicas
mynetworks = 127.0.0.0/8 [::1]/128 [IP-cliente-1] [IP-cliente-2]
# Configuración de relay
smtpd_relay_restrictions = permit_mynetworks permit_sasl_authenticated defer_unauth_destination
# TLS
smtpd_use_tls = yes
smtpd_tls_cert_file = /etc/ssl/certs/ssl-cert-snakeoil.pem
smtpd_tls_key_file = /etc/ssl/private/ssl-cert-snakeoil.key
2. Puerto alternativo en master.cf
# /etc/postfix/master.cf
# Puerto estándar
smtp inet n - y - - smtpd
# Puerto alternativo para clientes con puerto 25 capado
587 inet n - y - - smtpd
-o smtpd_client_restrictions=permit_mynetworks,reject
-o smtpd_tls_security_level=encrypt
3. Gestión de bounces (Prevención de bucles)
# /etc/aliases en smart relay
devnull: /dev/null
bounces: /dev/null
# Aplicar
newaliases
Configuración DNS y Autenticación
1. SPF Record
; Para el dominio principal
tudominio.com. IN TXT "v=spf1 ip4:ip-smart-relay-1 ip4:ip-smart-relay-2 -all"
; Para subdominios específicos (IMPORTANTE)
alerts.tudominio.com. IN TXT "v=spf1 ip4:ip-smart-relay-1 ip4:ip-smart-relay-2 -all"
2. DKIM Configuration
# Instalar herramientas DKIM
apt-get install opendkim opendkim-tools
# Generar claves
opendkim-genkey -t -s mail -d alerts.tudominio.com
# ⚠️ IMPORTANTE: El selector debe coincidir con el dominio usado en myorigin
3. DMARC Policy
_dmarc.tudominio.com. IN TXT "v=DMARC1; p=quarantine; rua=mailto:dmarc-reports@tudominio.com"
Resolución de Problemas Críticos
1. Bucles de correo ("too many hops")
Síntoma: Error 5.4.0 "too many hops" Causa: Correos hacia el propio dominio van al smart relay y vuelven
Solución:
# /etc/postfix/transport en servidor origen
alerts.tudominio.com local:
# Recompilar
postmap /etc/postfix/transport
systemctl reload postfix
2. "Relay access denied"
Síntoma: 454 4.7.1 Relay access denied Causa: IP del cliente no está en mynetworks del smart relay
Diagnóstico:
# En smart relay, verificar qué IP se conecta
grep "connect from" /var/log/mail.log | grep [IP-problema]
# Verificar configuración actual
postconf mynetworks
Solución: Añadir IP faltante a mynetworks
3. Alias no funciona
Síntoma: Los alias no se aplican correctamente Causa común: Errores tipográficos en myorigin
Diagnóstico:
# Verificar que el alias funciona
postalias -q root /etc/aliases
# ⚠️ VERIFICAR EXACTITUD de myorigin
postconf myorigin
# Común: "alertas" vs "alerts", ".co" vs ".com"
4. DKIM/DMARC failures
Síntoma: Correos marcados como spam Causa: Desalineación entre From domain y SPF/DKIM
Solución: Asegurar que myorigin coincide exactamente con dominio DKIM
Testing y Verificación
1. Test de funcionamiento básico
# Test desde línea de comandos
echo "Test desde $(hostname)" | mail -s "Test Relay" destino@gmail.com
# Verificar logs inmediatamente
tail -f /var/log/mail.log
2. Test de alias
# Envío a root debe ir al alias configurado
echo "Test alias" | mail -s "Test root alias" root
# Verificar en logs que va al destino correcto
3. Verificación DNS
# SPF
dig TXT alerts.tudominio.com
# DKIM
dig TXT mail._domainkey.alerts.tudominio.com
# DMARC
dig TXT _dmarc.tudominio.com
Errores Comunes y Soluciones
❌ Error: myorigin con tipografías
# MAL
myorigin = alertas.avanzait.co # ← error tipográfico
# BIEN
myorigin = alerts.avanzait.com
❌ Error: mynetworks incompleto
# MAL - falta IP del smart relay
mynetworks = 127.0.0.0/8
# BIEN - incluye smart relay para bounces
mynetworks = 127.0.0.0/8 [IP-smart-relay]
❌ Error: Sin transport maps
Sin transport maps, los correos al propio dominio crean bucles.
✅ Configuración correcta
# main.cf
transport_maps = hash:/etc/postfix/transport
# /etc/postfix/transport
alerts.tudominio.com local:
Configuración para Aplicaciones Específicas
Zabbix
# Media Type configuración
SMTP server: localhost
Port: 25
Email: root@alerts.tudominio.com
Authentication: None
Security: None
CSF (ConfigServer Firewall)
Los correos de sistema funcionarán automáticamente una vez configurados los alias correctamente. Eso incluye pruebas de concepto, avisos de CSF, etc.
Aplicaciones web (PHP/Python)
// PHP
ini_set('SMTP', 'localhost');
ini_set('smtp_port', 25);
Monitoreo y Mantenimiento
1. Script de monitoreo de colas
#!/bin/bash
# /usr/local/bin/check-mail-queue.sh
QUEUE_SIZE=$(mailq | tail -1 | awk '{print $5}' | tr -d ')')
if [ "$QUEUE_SIZE" -gt 50 ]; then
echo "ALERT: Mail queue size: $QUEUE_SIZE" | \
mail -s "Mail Queue Alert" admin@tudominio.com
fi
2. Verificación periódica de configuración
#!/bin/bash
# Verificar configuraciones críticas
echo "=== Verificación Postfix ==="
echo "myorigin: $(postconf myorigin)"
echo "relayhost: $(postconf relayhost)"
echo "mynetworks: $(postconf mynetworks)"
echo "transport_maps: $(postconf transport_maps)"
3. Backup de configuración
# Script de backup
tar -czf /backup/postfix-config-$(date +%Y%m%d).tar.gz \
/etc/postfix/ \
/etc/aliases \
/etc/opendkim/ 2>/dev/null
Lista de Verificación Pre-Producción
-
myoriginsin errores tipográficos -
mynetworksincluye todas las IPs necesarias -
transport_mapsconfigurado para evitar bucles - Aliases funcionando (
postalias -q root /etc/aliases) - SPF record publicado
- DKIM keys generados y DNS configurado
- DMARC policy establecida
- Test de envío exitoso
- Logs sin errores de relay
- Smart relay acepta conexiones del cliente
Troubleshooting Rápido
Bucle detectado
- Verificar
myorigin(sin typos) - Configurar
transport_maps - Verificar
mynetworksen ambos servidores
Alias no funciona
- Verificar
/etc/aliases - Ejecutar
newaliases - Verificar con
postalias -q
Relay denied
- Verificar IP real de conexión en logs
- Añadir IP a
mynetworksdel smart relay - Reload postfix
Aviso Legal
Esta documentación se proporciona "tal como está" sin garantías. Se recomienda realizar pruebas exhaustivas y mantener copias de seguridad.
Para soporte profesional: Castris Soporte
Zabbix
Cosas de zabbix
Mysql-MariaDB
Recuperación de MariaDB - Tablas del Sistema Corruptas
Incidente Crítico
- Fecha: 17 de octubre de 2025
- Sistema: MariaDB 11.8.3-MariaDB-ubu2404
- Severidad: ⚠️ Crítica – Servicio no inicia
- Nivel técnico: Administrador de Sistemas Avanzado (leer notas finales)
1. Resumen del Problema
El servidor MariaDB no inicia debido a corrupción de tablas del sistema.
Error principal: Tablas de sistema implicadas en el fallo múltiple
2025-10-17 6:27:08 3 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:27:08 3 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:27:08 3 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:27:08 3 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:27:08 3 [ERROR] mariadbd: Table './sitelight2_ma3/ma_api_token_table' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/column_stats'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/columns_priv'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/event'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/func'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/global_priv'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/help_category'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/help_keyword'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/help_relation'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/help_topic'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/index_stats'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/proc'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/procs_priv'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/proxies_priv'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/roles_mapping'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/tables_priv'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/time_zone'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/time_zone_leap_second'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/time_zone_name'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/time_zone_transition'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/time_zone_transition_type'
2025-10-17 6:27:12 4 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/global_priv'
2025-10-17 6:28:01 5 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:28:01 5 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:28:01 5 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:28:01 5 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:28:01 5 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:28:01 5 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:28:01 5 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:28:01 5 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:29:01 6 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:29:01 6 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:29:01 6 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:29:01 6 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:29:01 6 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:29:01 6 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:29:01 6 [ERROR] mariadbd: Got error '144 "Table is crashed and last repair failed"' for './mysql/table_stats'
2025-10-17 6:29:01 6 [ERROR] mariadbd: Table 'table_stats' is marked as crashed and last (automatic?) repair failed
2025-10-17 6:29:24 43 [Note] Found 15228 of 2114 rows when repairing './sitelight2_ma3/ma_api_token_table'
2025-10-17 6:29:29 150 [Note] Found 3138 of 2928 rows when repairing './sitelight2_matest/ma_bug_file_table'
Tablas afectadas:
mysql.pluginmysql.serversmysql.dbmysql.proxies_priv- ...
2. Estado del Servicio
Active: failed (Result: exit-code)
Main PID: 1101684 (code=exited, status=1/FAILURE)
Status: "MariaDB server is down"
3. Análisis Preliminar
3.1. Secuencia del log:
- Inicio normal de InnoDB: buffer pool y undo tablespaces OK
- Resize de redo log: 96MB → 16MB (LSN=1718365178)
- Socket creado en 0.0.0.0:3306
- Falla: Error 144 al abrir tablas de privilegios
- MariaDB aborta
3.2. Características del entorno:
- Motor tablas sistema: InnoDB (no MyISAM)
- Buffer pool: 64MB
- Instrucciones CPU: AVX512
- I/O: io_uring
- Rollback segments: 128 (en 3 undo tablespaces)
3.3. Causas probables:
- Apagado inesperado del sistema
- Fallos de disco (errores I/O)
- Falta de espacio en disco (Confirmado)
- Corrupción de memoria
- Bug en proceso de resize de redo log
4. Plan de Corrección
FASE 1: Diagnóstico Inicial
# 1. Chequear integridad del sistema
df -h /var/lib/mysql
dmesg | grep -i "error\|i/o"
smartctl -H /dev/sda
# 2. Revisar logs
tail -200 /var/log/mysql/error.log
# 3. Confirmar tipo de archivos
cd /var/lib/mysql/mysql/
ls -lh *.ibd | head -20
FASE 2: Backup Preventivo
Importante: Realizar backup completo antes de realizar cambios.
Opción A local si hay espacio en disco
Crea archivo de recuperación:
# 1. Verificar espacio disponible
df -h /var/lib/
du -sh /var/lib/mysql/
# 2. Realizar backup
cd /var/lib/
tar -czf mysql-backup-$(date +%Y%m%d-%H%M%S).tar.gz mysql/
# 3. Verificar integridad del backup
tar -tzf mysql-backup-*.tar.gz | head -20
Se entiende que el motor de bases de datos MySQL|MariaDB no esta activo
Opción B: Backup Remoto on-the-fly (Espacio local insuficiente)
- **Escenario: **Incidente causado por falta de espacio en disco, ahora solventado pero insuficiente para crear backup local.
- Requisito: SSH configurado con autenticación por llave pública. Comando único (one-liner):
systemctl stop mariadb && cd /var/lib/ && tar -czf - mysql/ | ssh usuario@servidor-remoto "cat > /backups/mysql-$(hostname)-$(date +%Y%m%d-%H%M%S).tar.gz"
Variantes
# Con progreso visual (requiere pv)
systemctl stop mariadb && cd /var/lib/ && tar -czf - mysql/ | pv | ssh usuario@servidor-remoto "cat > /backups/mysql-$(hostname)-$(date +%Y%m%d-%H%M%S).tar.gz"
# Con compresión paralela (requiere pigz, más rápido)
systemctl stop mariadb && cd /var/lib/ && tar -cf - mysql/ | pigz | ssh usuario@servidor-remoto "cat > /backups/mysql-$(hostname)-$(date +%Y%m%d-%H%M%S).tar.gz"
# Con SSH optimizado para transferencia rápida
systemctl stop mariadb && cd /var/lib/ && tar -czf - mysql/ | ssh -c aes128-gcm@openssh.com -o Compression=no usuario@servidor-remoto "cat > /backups/mysql-$(hostname)-$(date +%Y%m%d-%H%M%S).tar.gz"
Verificación del remoto
# Listar archivo creado
ssh usuario@servidor-remoto "ls -lh /backups/mysql-*"
# Verificar integridad
ssh usuario@servidor-remoto "tar -tzf /backups/mysql-*.tar.gz | head -20"
FASE 3: Arranque en Modo Recovery (innodb_force_recovery)
c# Crear archivo de configuración de recuperación
cat > /etc/my.cnf.d/recovery.cnf << 'EOF'
[mysqld]
innodb_force_recovery = 1
EOF
# Intentar inicio
systemctl start mariadb
systemctl status mariadb
Aumenta el valor de innodb_force_recovery (1→6) si sigue fallando.
Referencia rápida:
| Valor | Función |
|---|---|
| 1 | Ignora páginas corruptas |
| 2 | Deshabilita hilos en background |
| 3 | No ejecuta rollback de transacciones |
| 4 | No merge de insert buffer |
| 5 | No escaneo undo log |
| 6 | No aplica redo log (Modo Solo Lectura Crítico) |
FASE 4: Reparación de Tablas
Con servidor en recovery se aconseja el script si hay muchas tablas
Se puede modificar para añadir las tablas que pudieran faltar en el ejemplo
#!/bin/bash
# Script de reparación masiva de tablas MariaDB
# Usar con MariaDB ya iniciado en modo recovery
# reparir_mariadb.sh
set -e
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
echo -e "${GREEN}=== Script de reparación masiva MariaDB ===${NC}\n"
# Verificar que MySQL esté corriendo
if ! mysqladmin ping &>/dev/null; then
echo -e "${RED}ERROR: MariaDB no está corriendo${NC}"
echo "Asegúrate de que esté iniciado en modo recovery"
exit 1
fi
# Conectar a MySQL y obtener lista de todas las tablas corruptas
echo -e "${YELLOW}Identificando tablas corruptas...${NC}"
# Crear script SQL temporal
cat > /tmp/repair_all.sql << 'SQLEOF'
-- Seleccionar base de datos mysql
USE mysql;
-- Intentar reparar todas las tablas del sistema
REPAIR TABLE column_stats;
REPAIR TABLE columns_priv;
REPAIR TABLE db;
REPAIR TABLE event;
REPAIR TABLE func;
REPAIR TABLE general_log;
REPAIR TABLE global_priv;
REPAIR TABLE gtid_slave_pos;
REPAIR TABLE help_category;
REPAIR TABLE help_keyword;
REPAIR TABLE help_relation;
REPAIR TABLE help_topic;
REPAIR TABLE host;
REPAIR TABLE index_stats;
REPAIR TABLE innodb_index_stats;
REPAIR TABLE innodb_table_stats;
REPAIR TABLE plugin;
REPAIR TABLE proc;
REPAIR TABLE procs_priv;
REPAIR TABLE proxies_priv;
REPAIR TABLE roles_mapping;
REPAIR TABLE servers;
REPAIR TABLE slow_log;
REPAIR TABLE table_stats;
REPAIR TABLE tables_priv;
REPAIR TABLE time_zone;
REPAIR TABLE time_zone_leap_second;
REPAIR TABLE time_zone_name;
REPAIR TABLE time_zone_transition;
REPAIR TABLE time_zone_transition_type;
REPAIR TABLE transaction_registry;
REPAIR TABLE user;
-- Mostrar estado
SELECT 'Reparación de tablas del sistema completada' AS Status;
SQLEOF
# Ejecutar reparación
echo -e "${YELLOW}Ejecutando reparación de tablas del sistema...${NC}"
mysql -u root < /tmp/repair_all.sql 2>&1 | tee /tmp/repair_output.log
# Reparar tablas de todas las bases de datos
echo -e "\n${YELLOW}Obteniendo lista de todas las bases de datos...${NC}"
DBS=$(mysql -u root -Bse "SHOW DATABASES;" 2>/dev/null | grep -v -E "^(information_schema|performance_schema|sys)$")
for db in $DBS; do
echo -e "\n${GREEN}=== Procesando base de datos: $db ===${NC}"
# Obtener tablas de esta BD
TABLES=$(mysql -u root -D "$db" -Bse "SHOW TABLES;" 2>/dev/null)
if [ -z "$TABLES" ]; then
echo -e "${YELLOW} No hay tablas en $db${NC}"
continue
fi
for table in $TABLES; do
echo -n " Reparando $db.$table ... "
# Intentar reparar
RESULT=$(mysql -u root -D "$db" -e "REPAIR TABLE \`$table\`;" 2>&1)
if echo "$RESULT" | grep -q "OK\|Already up to date"; then
echo -e "${GREEN}OK${NC}"
else
echo -e "${RED}FAILED${NC}"
echo "$RESULT" >> /tmp/repair_failed.log
fi
done
done
# Resumen
echo -e "\n${GREEN}=== Resumen de reparación ===${NC}"
echo -e "Log completo: /tmp/repair_output.log"
if [ -f /tmp/repair_failed.log ]; then
echo -e "${RED}Tablas que fallaron: /tmp/repair_failed.log${NC}"
echo -e "\n${YELLOW}Tablas con errores:${NC}"
cat /tmp/repair_failed.log
else
echo -e "${GREEN}Todas las tablas reparadas exitosamente${NC}"
fi
# Optimizar tablas después de reparar
echo -e "\n${YELLOW}¿Deseas optimizar todas las tablas? (s/n)${NC}"
read -r optimize
if [ "$optimize" = "s" ]; then
echo -e "${YELLOW}Optimizando tablas...${NC}"
for db in $DBS; do
echo -e "${GREEN}Optimizando base de datos: $db${NC}"
TABLES=$(mysql -u root -D "$db" -Bse "SHOW TABLES;" 2>/dev/null)
for table in $TABLES; do
echo -n " Optimizando $db.$table ... "
mysql -u root -D "$db" -e "OPTIMIZE TABLE \`$table\`;" &>/dev/null && echo -e "${GREEN}OK${NC}" || echo -e "${YELLOW}SKIP${NC}"
done
done
fi
echo -e "\n${GREEN}=== Proceso completado ===${NC}"
echo -e "${YELLOW}Siguiente paso: Detener modo recovery y reiniciar MariaDB normalmente${NC}"
# Limpiar
rm -f /tmp/repair_all.sql
FASE 5: Salida del Modo Recovery y Upgrade de Sistema
rm -f /etc/my.cnf.d/recovery.cnf
systemctl restart mariadb
mysql_upgrade --force -u root -p # Importante tras desastre con tablas de sistemas
systemctl restart mariadb
systemctl status mariadb
mysql -u root -e "SELECT VERSION(); SHOW DATABASES;"
5. Contingencias
En caso de no finalizar la solución propuesta es hora de tirar de backups.
A) Instancia nueva y recuperación manual
tar -czf mysql-critical-backup-$(date +%Y%m%d-%H%M%S).tar.gz /var/lib/mysql/
mv /var/lib/mysql /var/lib/mysql.corrupted
mysql_install_db --user=mysql --datadir=/var/lib/mysql
systemctl start mariadb
# Restaurar datos desde backup/ibd/dump si es posible
B) Recuperar desde backup externo
systemctl stop mariadb
rm -rf /var/lib/mysql
tar -xzf /ruta/al/backup.tar.gz -C /var/lib/
chown -R mysql:mysql /var/lib/mysql
systemctl start mariadb
6. Verificación Post-Recuperación
mysqlcheck --all-databases --check -u root -p
mysql -u root -e "USE mysql; SHOW TABLES;"
mysql -u root -e "SELECT user,host FROM mysql.user;"
tail -100 /var/log/mysql/error.log | grep -i error
Realizar prueba de conexión desde aplicaciones (paneles de control, etc)
7. Notas y Referencias Técnicas
- Desde MariaDB 10.4 las tablas del sistema usan InnoDB, myisamchk ya no es válido
innodb_force_recoveryes crítico en estos casos [Referencia][1]- Logs principales:
/var/log/mysql/error.log,journalctl -u mariadb.service,/var/log/syslog
Herramientas avanzadas:
innochecksum /var/lib/mysql/mysql/db.ibd
innochecksum /var/lib/mysql/ib_logfile0
mysql -u root -e "SELECT * FROM information_schema.innodb_sys_tables WHERE name LIKE 'mysql/%';"
Notas finales
Este documento, requiere cierto grado de madurez en la administración de sistemas.
No es apto para un copy & paste
Referencias
Documento actualizado: 17 de octubre de 2025
Autoría: Administración de Sistemas – Abdelkarim Mateos
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Utilidades
Un paquete de utulidades para la administracion de sistemas, con foco en backups de diversos tipos y sitauaciones.
Sistema de backup pull para Proxmox VE
Sistema de backup basado en snapshots LVM para maquinas virtuales en Proxmox VE. Utiliza una arquitectura pull donde el servidor de storage inicia las conexiones SSH hacia Proxmox y tira de los datos. El servidor Proxmox nunca tiene acceso de escritura al storage.
Motivacion
El modelo tradicional push (Proxmox envia al storage) tiene un problema de seguridad critico: si el servidor Proxmox es comprometido, el atacante tiene credenciales SSH con acceso de escritura al storage y puede destruir todos los backups.
Con el modelo pull:
- Proxmox no conoce las credenciales del storage
- Proxmox no puede escribir ni borrar en el storage
- Solo el storage decide cuando y que se respalda
- Un Proxmox comprometido no puede destruir los backups existentes
Arquitectura
A partir de v2.0.0 el flujo es por VM en vez de por disco individual. Para VMs con multiples discos, todos los snapshots se crean atomicamente antes de transferir cualquier dato, garantizando consistencia temporal. Desde v2.1.0, un lock distribuido permite que multiples storages respalden el mismo Proxmox sin colisiones.
Storage Server Proxmox Server
| |
|-- ssh "list" ------------------------>| (inventario de VMs)
|<-- CSV: vmid,status,vg,lv,size -------|
| |
| Para cada VM: |
|-- ssh "snapshot-vm <vmid> <pct> |
| <caller_id> <lock_ttl>" ------>| (lock distribuido + snapshots atomicos)
|<-- manifest: snap_name,vg,lv,size ----|
| |
| Para cada disco en manifest: |
|-- ssh "stream-disk <vg> <snap>" ----->| (stream comprimido dd|pigz)
|<------------ compressed stream -------|
|-- verifica PIPESTATUS + tamano |
| |
| Si TODOS los discos OK: |
|-- mv atomico incoming/ -> snapshots/ |
|-- prune copias antiguas |
| |
| Si ALGUN disco falla: |
|-- elimina TODO incoming/ de esta VM |
|-- backup previo en snapshots/ intacto |
| |
| SIEMPRE: |
|-- ssh "cleanup-vm <vmid> |
| <caller_id>" ----------------->| (elimina snapshots + libera lock)
Consistencia multi-disco (v2.0.0)
El problema que resuelve v2.0.0: en versiones anteriores, los snapshots se creaban uno a uno (snapshot disk0 → transfer disk0 → cleanup disk0 → snapshot disk1 → transfer disk1). Para VMs con multiples discos, los snapshots capturaban diferentes instantes, produciendo backups inconsistentes.
La solucion:
-
snapshot-vmcrea TODOS los snapshots en sucesion rapida (milisegundos entre ellos) -
Si algun snapshot falla, rollback automatico de los ya creados
-
Los streams se transfieren secuencialmente pero desde snapshots del mismo instante
-
cleanup-vmelimina todos los snapshots al final
Semantica all-or-nothing
- Un backup parcial de VM es inutil (disk0 de hoy y disk1 de ayer)
snapshots/siempre contiene conjuntos completos- Si ANY disco falla: se borra todo el incoming de esa VM, el backup anterior queda intacto
- Prune solo ejecuta tras exito total
Validacion de integridad (v2.1.2)
La compresion se realiza on-the-fly en el pipeline SSH: dd if=/dev/vg/snap bs=16M | pigz -c -p4 -3. Los errores del pipeline se detectan via PIPESTATUS inmediatamente. No se ejecuta verificacion post-transferencia (pigz -t) porque:
- Re-leer ficheros de 93GB+ desde disco mecanico (30-40 MB/s) tarda 40-50 minutos
- Es redundante: si el pipeline falla, PIPESTATUS lo captura
- La verificacion de integridad de backups pertenece a auditorias periodicas, no al flujo diario
Lock distribuido (v2.1.0)
Cuando multiples storages respaldan el mismo Proxmox, un lock distribuido previene colisiones:
- Ficheros lock en
/run/pull-backup/vm-{vmid}.locken Proxmox - Adquisicion atomica via
ln(hard link, falla con EEXIST si ya existe) - Contenido:
caller_id, timestamp, TTL - VM bloqueada por otro storage: skip limpio (exit 80,
VM_LOCKED) - Locks expirados (mas antiguos que
lock_ttl) se limpian automaticamente - Solo el caller que creo el lock puede liberarlo
Configuracion: caller_id (unico por storage) y lock_ttl (segundos) en pull-backup.cfg. Sin caller_id, el lock se desactiva (modo single-storage).
Componentes
| Componente | Version | Ubicacion | Funcion |
|---|---|---|---|
proxmox-backup-helper.sh |
2.1.1 | Proxmox: ~/utilidades/proxmox-backup/pull/ (repo clonado) |
Manejador SSH restringido con 13 comandos, lock distribuido |
proxmox-pull-backup.sh |
2.1.2 | Storage: ~/utilidades/proxmox-backup/pull/ (repo clonado) |
Orquestador de backups (flujo por VM, lock distribuido) |
proxmox-pull-restore.py |
1.0.0 | Storage: mismo directorio | Herramienta de restauracion (Python 3.6+) |
backup-access-shell.sh |
1.0.0 | Storage: mismo directorio | Shell de solo lectura para restore |
install-pull-backup.sh |
1.0.0 | Storage: mismo directorio | Instalador automatizado |
IMPORTANTE: Todos los scripts se ejecutan desde el repo clonado (~/utilidades/proxmox-backup/pull/). Nunca copiar a /usr/local/bin/ ni a otra ruta del sistema. Un git pull actualiza todo.
Requisitos previos
- Proxmox: Version 7.x, 8.x o 9.x con almacenamiento LVM
- Storage: Servidor Linux con espacio suficiente
- Ambos servidores:
pigzinstalado (apt-get install pigz) - Storage: Python 3.6+ (solo stdlib, sin dependencias externas)
- Red: Acceso SSH desde storage hacia Proxmox
Instalacion
Paso 1: Clonar el repositorio en ambos servidores
En Proxmox (como root):
cd ~
git clone <url-del-repo> utilidades
En storage (como usuario de backup, NO root):
cd ~
git clone <url-del-repo> utilidades
Paso 2: Instalar pigz en ambos servidores
apt-get install -y pigz
Paso 3: Generar clave SSH y configurar acceso
En el storage:
cd ~/utilidades/proxmox-backup/pull
mkdir -p keys
ssh-keygen -t ed25519 -f keys/id_pull_backup -N "" -C "pull-backup@$(hostname)"
Copiar la clave publica al Proxmox con restriccion command=:
# En /root/.ssh/authorized_keys del Proxmox:
command="/root/utilidades/proxmox-backup/pull/proxmox-backup-helper.sh",no-port-forwarding,no-X11-forwarding,no-agent-forwarding,no-pty ssh-ed25519 AAAA... pull-backup@mystor01
Paso 4: Crear la configuracion
cd ~/utilidades/proxmox-backup/pull
cp config/pull-backup.cfg.example config/pull-backup.cfg
cp config/proxmox_hosts.cfg.example hosts/proxmox_hosts.cfg
Editar config/pull-backup.cfg:
# Directorios
incoming_dir="/srv/storage/backups_kvm/incoming"
final_dir="/srv/storage/backups_kvm/snapshots"
# Retencion
numcopias=3
# Snapshots
snapshot_pct=15 # Porcentaje del LV para snapshot
default_vm_scope="all" # "all" = descubre todas las VMs; "none" = requiere filtro
# Rendimiento
min_speed_mbs=150 # MB/s minimos esperados (para timeout dinamico)
min_free_gb=500 # GB libres requeridos (ademas del tamano estimado)
ssh_timeout=30 # Timeout SSH en segundos
# Lock distribuido (v2.1.0+, obligatorio si hay multiples storages)
caller_id="mystor01" # Identificador unico de este storage
lock_ttl=7200 # TTL del lock en segundos (2h)
# Permisos de ficheros
file_owner="backupuser:backupuser" # chown tras escribir
# Notificaciones (solo en errores)
correo="admin@example.com"
Editar hosts/proxmox_hosts.cfg:
# name,host,port,key_file,disks_file
myprox01,10.0.0.1,22,keys/id_pull_backup,
El campo disks_file es opcional desde v2.0.0. Con default_vm_scope="all", el orquestador descubre automaticamente todas las VMs activas.
Paso 5: Crear directorios de datos
mkdir -p /srv/storage/backups_kvm/incoming
mkdir -p /srv/storage/backups_kvm/snapshots
mkdir -p ~/utilidades/proxmox-backup/pull/logs
Paso 6: Verificar conectividad
cd ~/utilidades/proxmox-backup/pull
./proxmox-pull-backup.sh --host myprox01 --verbose --dry-run
Paso 7: Configurar cron
# Backup diario a las 02:00 UTC
crontab -e
0 2 * * * ~/utilidades/proxmox-backup/pull/proxmox-pull-backup.sh >> ~/utilidades/proxmox-backup/pull/logs/cron.log 2>&1
IMPORTANTE con multiples storages: escalonar los crons con al menos 15 minutos de diferencia. Aunque el lock distribuido previene colisiones, la separacion temporal reduce contention.
Actualizacion
cd ~/utilidades
git pull
No requiere reinicio. Los scripts se invocan frescos en cada ejecucion.
Uso diario
Ejecutar backup manual
cd ~/utilidades/proxmox-backup/pull
# Dry-run (no ejecuta nada, muestra lo que haria)
./proxmox-pull-backup.sh --host myprox01 --verbose --dry-run
# Backup real de todas las VMs de un host
./proxmox-pull-backup.sh --host myprox01 --verbose
# Backup de una VM especifica
./proxmox-pull-backup.sh --host myprox01 --vm 104 --verbose
# Backup de varias VMs (separadas por coma o repetido)
./proxmox-pull-backup.sh --host myprox01 --vm 104,203 --verbose
# Backup de todos los hosts configurados
./proxmox-pull-backup.sh --verbose
Listar backups disponibles
python3 proxmox-pull-restore.py --config config/pull-backup.cfg list
# Filtrar por host
python3 proxmox-pull-restore.py --config config/pull-backup.cfg list --host myprox01
# Filtrar por VM
python3 proxmox-pull-restore.py --config config/pull-backup.cfg list --vm 316
Restaurar una VM
Escenario A: la VM existe y esta parada (sobreescribe los discos):
python3 proxmox-pull-restore.py --config config/pull-backup.cfg \
restore --host myprox01 --vm 316 --data-only
Escenario B: la VM no existe (crea LV, config y restaura datos):
python3 proxmox-pull-restore.py --config config/pull-backup.cfg \
restore --host myprox01 --vm 316 --from-scratch
Restaurar desde una fecha concreta:
python3 proxmox-pull-restore.py --config config/pull-backup.cfg \
restore --host myprox01 --vm 316 --date 2026-02-08
Restaurar varias VMs en paralelo:
python3 proxmox-pull-restore.py --config config/pull-backup.cfg \
restore --host myprox01 --vm 316 900 --workers 2
IMPORTANTE: el argumento --config va ANTES del subcomando (list, restore).
Modelo de seguridad
Lado Proxmox
El helper (proxmox-backup-helper.sh) se ejecuta exclusivamente via la restriccion command= en authorized_keys. Esto significa que cualquier conexion SSH con esa clave ejecuta el helper, ignorando el comando solicitado por el cliente.
El helper valida cada argumento con expresiones regulares estrictas:
- Volume groups: solo alfanumericos, guiones y guiones bajos
- Logical volumes: solo patron
vm-\d+-disk-\d+ - Snapshot names: solo patron
snap-\d+-disk\d+ - VMIDs: solo numeros entre 100 y 999999
- Snapshot porcentaje: solo numeros entre 1 y 100
- caller_id: solo alfanumericos, guiones y guiones bajos (v2.1.0)
Comandos no reconocidos se rechazan con error. Todas las operaciones se registran en syslog.
Lado Storage
El storage inicia todas las conexiones. Proxmox nunca se conecta al storage para los backups. El unico acceso inverso (Proxmox hacia storage) es para restore, y se canaliza a traves de backup-access-shell.sh que solo permite operaciones de lectura (pigz -dc, ls, test, cat, du) y valida rutas con readlink -f contra symlinks maliciosos.
Estructura de ficheros
En el servidor de storage
~/utilidades/proxmox-backup/pull/
proxmox-pull-backup.sh # Orquestador v2.1.2
proxmox-pull-restore.py # Herramienta de restore
backup-access-shell.sh # Shell read-only
install-pull-backup.sh # Instalador
config/
pull-backup.cfg # Configuracion principal (gitignored)
pull-backup.cfg.example # Template (versionado)
hosts/
proxmox_hosts.cfg # Inventario de hosts (gitignored)
disks_myprox01.txt # (Opcional) filtro de discos (gitignored)
keys/
id_pull_backup # Clave privada SSH (gitignored)
id_pull_backup.pub # Clave publica SSH (gitignored)
logs/
pull-backup-YYYY-MM-DD.log # Log diario (gitignored)
cron.log # Log de cron (gitignored)
En el servidor Proxmox
~/utilidades/proxmox-backup/pull/
proxmox-backup-helper.sh # Helper restringido v2.1.1
/root/.ssh/authorized_keys # Clave con command=
/run/pull-backup/ # Lock files distribuidos (runtime)
Directorio de backups
/srv/storage/backups_kvm/
incoming/ # Transferencias en curso
snapshots/
kvm-104-disk0.2026-02-26-10-00-12.gz # Disco 0 comprimido
kvm-104-disk1.2026-02-26-10-00-12.gz # Disco 1 (mismo timestamp)
kvm-104.conf.2026-02-26-10-00-12 # Config de la VM
Nomenclatura de ficheros
kvm-{vmid}-disk{N}.{YYYY-MM-DD-HH-MM-SS}.gz # Discos
kvm-{vmid}.conf.{YYYY-MM-DD-HH-MM-SS} # Configuraciones
Comandos del helper
El helper v2.1.1 acepta 13 comandos, todos validados con regex:
| Comando | Argumentos | Funcion |
|---|---|---|
list |
(ninguno) | Lista VMs activas con discos LVM |
list-all |
(ninguno) | Lista TODAS las VMs (incluidas paradas) |
list-snapshots |
(ninguno) | Lista snapshots activos (deteccion de huerfanos) |
snapshot-vm |
vmid porcentaje [force] [caller_id] [lock_ttl] |
Adquiere lock distribuido (si caller_id), crea snapshots atomicos de TODOS los discos. Devuelve manifest |
stream-disk |
vg snap_name |
Envia stream comprimido (dd | pigz) de un snapshot |
cleanup-vm |
vmid [caller_id] |
Elimina TODOS los snapshots de una VM y libera lock |
check-lock |
vmid |
Verifica estado del lock distribuido de una VM (v2.1.0) |
snapshot |
vg lv porcentaje [force] |
(Deprecated) Crea snapshot individual y envia stream |
cleanup |
vg snap_name |
Elimina un snapshot LVM individual |
config |
vmid |
Devuelve el fichero de configuracion de la VM |
restore |
vg lv |
Recibe stream comprimido y lo escribe al disco |
create-disk |
vg nombre size_gb |
Crea un nuevo volumen logico |
restore-config |
vmid |
Recibe y escribe la config de la VM |
Formato del manifest (snapshot-vm)
# snap_name,vg,lv,size_gb
snap-104-disk0,pve,vm-104-disk-0,150
snap-104-disk1,pve,vm-104-disk-1,125
Opciones del orquestador
proxmox-pull-backup.sh [--config <path>] [--host <name>] [--vm <vmid>[,<vmid>...]] [--dry-run] [--force] [--verbose]
--config <path> Fichero de configuracion (default: ./config/pull-backup.cfg)
--host <name> Backup solo este host (default: todos los hosts)
--vm <vmid>[,<vmid>...] Backup solo estas VMs (separadas por coma, repetible)
--dry-run Muestra lo que haria sin ejecutar
--force Auto-limpieza de snapshots huerfanos en Proxmox
--verbose Salida detallada
Parametros de configuracion
| Parametro | Default | Descripcion |
|---|---|---|
incoming_dir |
(obligatorio) | Directorio temporal para transferencias en curso |
final_dir |
(obligatorio) | Directorio final de backups |
numcopias |
3 | Copias a retener por disco |
snapshot_pct |
15 | Porcentaje del LV para snapshot |
default_vm_scope |
"all" | "all" = descubre todas las VMs; "none" = requiere filtro |
min_speed_mbs |
150 | MB/s minimos esperados (para timeout dinamico) |
min_free_gb |
1024 | GB libres minimos en storage (ademas del tamano estimado) |
force_orphan_cleanup |
0 | Auto-limpiar snapshots huerfanos (1 = activado) |
caller_id |
"" | Identificador de este storage (obligatorio para multi-storage) |
lock_ttl |
7200 | TTL del lock distribuido en segundos |
file_owner |
"" | user:group para chown tras escritura (ej: backupuser:backupuser) |
correo |
"" | Email para notificaciones de error (nunca en exito) |
ssh_timeout |
30 | Timeout de conexion SSH en segundos |
Funcionalidades avanzadas
Descubrimiento dinamico (v2.0.0)
Con default_vm_scope="all" en la config, el orquestador descubre automaticamente todas las VMs activas usando el comando list del helper. Los ficheros disks_*.txt pasan a ser opcionales (filtro de exclusion, no inventario obligatorio).
Timeout dinamico
El timeout de cada transferencia se calcula automaticamente segun el tamano del disco:
timeout = (tamano_disco_gb * 1024) / min_speed_mbs
Con un minimo de 300 segundos. Para un disco de 150GB a 150 MB/s el timeout es ~17 minutos.
Deteccion de snapshots huerfanos
Antes de procesar cada host, el orquestador ejecuta list-snapshots y compara con los snapshots esperados. Los huerfanos (de ejecuciones previas fallidas) se limpian automaticamente si force_orphan_cleanup=1.
Estimacion de tamano
Si existe un backup previo del mismo disco, se usa su tamano como estimacion. Si no, se estima el 50% del tamano raw del disco. Esto se usa para la verificacion de espacio libre.
Reintentos
Si un backup falla, se reintenta una vez tras 10 minutos de espera. Solo se reporta error si el segundo intento tambien falla. Si falla el reintento, la VM completa se marca como fallida (all-or-nothing).
Pruning automatico
Tras completar los backups, se mantienen solo las ultimas numcopias copias de cada disco. Las configs asociadas a backups eliminados tambien se limpian.
Rendimiento validado
Produccion (marzo 2026, v2.1.2)
| VM | Discos | Comprimido | Tiempo total | Velocidad | Ruta |
|---|---|---|---|---|---|
| KVM 104 | 2 (150+125 GB) | 93 GB | 14.5 min | 106-111 MB/s | avanza01 → stor01avanzait |
| KVM 203 | 2 (85+50 GB) | 39 GB | ~12 min | 56-76 MB/s | avanza01 → stor01avanzait |
| KVM 100 | 1 (620 GB) | 415 GB | 30 min | 233 MB/s | indivaprox0 → localstor (local) |
| KVM 101 | 1 (260 GB) | 114 GB | 10 min | 187 MB/s | indivaprox0 → localstor (local) |
Mejora v2.1.2: La eliminacion de la verificacion pigz -t post-transferencia redujo el tiempo total de KVM 104 de ~61 min (v2.0.0) a ~14.5 min — aceleracion de 4x. La integridad de la compresion se valida on-the-fly via PIPESTATUS del pipeline dd | pigz.
Staging (febrero 2026)
| Operacion | Disco | Tiempo | Velocidad | Resultado |
|---|---|---|---|---|
| Backup | 5GB | 11s | 6 MB/s | 73MB comprimido |
| Restore data-only | 5GB | 10s | 7 MB/s | OK |
| Restore from-scratch | 5GB | 9s | 7 MB/s | LV + config + datos |
| Deteccion huerfanos | -- | instantaneo | -- | Auto-limpieza |
| Pruning 4 a 3 copias | -- | <1s | -- | Retencion exacta |
Despliegues actuales
| Storage | Host Proxmox | VMs | Cron (UTC) | Version |
|---|---|---|---|---|
| localstor (stor00) | indivaprox0 | KVM 100 (1d, 620GB), KVM 101 (1d, 260GB) | 22:00 VM100, 23:15 VM101 | v2.1.2 |
| stor01 | indivaprox0 | todas (dynamic discovery) | 02:00 | v2.1.2 |
| stor01avanzait | avanza01 | KVM 104 (2d), KVM 203 (2d) | 10:00 | v2.1.2 |
Troubleshooting
El backup genera un fichero .gz invalido
Causa: Los comandos lvcreate/lvremove escriben mensajes a stdout que contaminan el stream gzip.
Solucion: Verificar que el helper redirige stdout de lvm a stderr (>&2). Actualizar el helper a v2.1.1+.
VM bloqueada por otro storage (exit 80)
Causa: Otro storage esta respaldando esa VM. El lock distribuido (v2.1.0) previene la colision.
Solucion: Es un comportamiento correcto. La VM se salta limpiamente y se respalda en la siguiente ejecucion. Si el lock es huerfano (proceso anterior murio), esperar a que expire el TTL (default 2h) o limpiar manualmente:
ssh -i keys/id_pull_backup proxmox "cleanup-vm <vmid> <caller_id>"
Snapshot/lock huerfano tras matar un proceso
Causa: Si se mata el proceso del orquestador (kill -9), pueden quedar snapshots y locks huerfanos en Proxmox.
Solucion: Limpiar manualmente:
ssh -i keys/id_pull_backup proxmox "cleanup-vm <vmid> <caller_id>"
Timeout en backups de discos grandes
Causa: El timeout dinamico depende de min_speed_mbs en la config.
Solucion: Reducir min_speed_mbs si la red es lenta. Por ejemplo, para 50 MB/s reales:
min_speed_mbs=40 # Dejar margen del 20%
Snapshot overflow (snap_percent=100)
Causa: El disco recibe mas escrituras de las esperadas durante la transferencia, llenando el snapshot COW.
Solucion: Aumentar snapshot_pct en la config (default: 15). Para VMs con alta actividad de I/O, usar 20-25.
El restore dice "pigz: unrecognized format"
Causa: El fichero .gz esta corrupto.
Solucion: Rehacer el backup con el helper v2.1.1+.
Repositorio
El codigo fuente esta en el repositorio utilidades bajo proxmox-backup/pull/.
Documentacion completa: proxmox-backup/README.md y proxmox-backup/docs/SPEC-pull-backup-architecture.md.
Historial de versiones
| Version | Fecha | Cambio principal |
|---|---|---|
| 2.1.2 | 2026-03-02 | Eliminada verificacion pigz -t post-transferencia (aceleracion 4x en disco mecanico) |
| 2.1.1 | 2026-03-01 | 9 bugs corregidos: race condition TOCTOU en lock, set +e en pipelines, globals stale, etc. |
| 2.1.0 | 2026-03-01 | Lock distribuido para prevencion de colisiones multi-storage |
| 2.0.0 | 2026-02-26 | Snapshots atomicos multi-disco, flujo per-VM, all-or-nothing, snapshot-vm/stream-disk/cleanup-vm |
| 1.4.0 | 2026-02-09 | Multi-VM filter, dynamic discovery |
| 1.1.0 | 2026-02-08 | Fix stdout pollution en helper, validacion staging |
| 1.0.0 | 2026-02-08 | Primera version funcional |
Ultima actualizacion
- Fecha: 2026-03-02
- Version: 2.1.2
- Autor: Abkrim