Proxmox
Cosas sobre Proxmox
- Git pull, error: server certificate verification failed. CAfile: none CRLfile: none
- [PRIV] Instalar Proxmox desde 0
- LVM Práctico para Proxmox y OVH
- Red OVH vrack para Proxmox 7
- Como arreglar el error Sender address rejected: need fully-qualified address (in reply to RCPT TO command)
- Proxmox, Hetzner, y bloques de Ips adicionales en modo Routed
- Desactivar los mensajes de log en la consola (Proxmox)
- Proxmox: Servicios Colgados - Diagnóstico y Soluciones
- Ampliación de disco (basado en qcow2) en sistema virtualizado KVM (proxmox)
- Ampliación de disco en sistema virtualizado KVM (proxmox)
- IPv6 para VMs en Proxmox sobre OVH bare-metal (NDP proxy)
Git pull, error: server certificate verification failed. CAfile: none CRLfile: none
Introducción
El problema me apareció en un proxmox desactualizado, cuando quise hacer un pull de mis utilidades.
git pull fatal: unable to access 'https://*****.castris.com/root/utilidades.git/': server certificate verification failed. CAfile: none CRLfile: none
Tras verificar que el problema no estaba del lado de mi gitlab, sospeche de la desactualización de Proxmox. Como nunca actualizo un Proxmox, ya la solución de actualizar sólo los ca-certificates y paquetes relacionados, no funcionó opte por una tip rápido.
No actualizo los proxmox, porque desde la versión 3, que ya son años, he tenido 4 incidentes de actualización, con sus correspondientes problemas derivados. Así que prefiero hacer un un turn-over en mi proveedor, coger una máquina nueva cada dos o tres años, y dejarme de tonterías. Atención, a mis máquinas proxmox no se acceden sino es desde mis ips, otra imposición que me puse dado que he visto muchos proxmox hackeados vía web. Así que al estar capado, no tengo miedo a no "actualizar"
Modificación de Git para no verificar ssl
root@pro12:~/utilidades# git config --global http.sslverify false
root@pro12:~/utilidades# git pull
remote: Enumerating objects: 23, done.
remote: Counting objects: 100% (23/23), done.
remote: Compressing objects: 100% (14/14), done.
remote: Total 18 (delta 9), reused 12 (delta 4), pack-reused 0
Unpacking objects: 100% (18/18), done.
From https://gitlab.castris.com/root/utilidades
10bda88..c93d331 master -> origin/master
Updating 10bda88..c93d331
Fast-forward
.gitignore | 2 +
actualiza.sh | 2 +-
basura.sh | 4 +
compress-dovecot.sh | 164 ++++++++++
csf/proxmox.csf.conf | 2678 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
fixpermisions.sh | 164 ++++++++++
6 files changed, 3013 insertions(+), 1 deletion(-)
create mode 100644 compress-dovecot.sh
create mode 100644 csf/proxmox.csf.conf
create mode 100644 fixpermisions.sh
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
[PRIV] Instalar Proxmox desde 0
OVH
Seguridad
mkdir /root/soft;cd /root/soft/; wget https://download.configserver.com/csf.tgz; tar xvfz csf.tgz; cd csf; sh install.sh; cd ..; rm -Rf csf/ csf.tgz; \
echo '.cpanel.net
.googlebot.com
.crawl.yahoo.net
.search.msn.com
.paypal.com
.paypal.es' > /etc/csf/csf.rignore;\
wget -O /etc/csf/csf.conf https://gitlab.castris.com/root/utilidades/-/raw/main/csf/proxmox.csf.conf; \
wget -O /etc/csf/csf.blocklists https://gitlab.castris.com/root/utilidades/-/raw/main/csf/csf.blocklists; \
wget -O /etc/csf/csf.allow ttps://gitlab.castris.com/root/utilidades/-/raw/main/csf/csf.allow; \
wget -O /etc/csf/csf.dyndns https://gitlab.castris.com/root/utilidades/-/raw/main/csf/csf.dyndns
Discos
Utilidades
cd ~ && git clone https://gitlab.castris.com/root/utilidades.git
Red
zabbix
Discos remotos
LVM Práctico para Proxmox y OVH
Introducción
Es un tip que uso para mis necesidades. Entre otras, no uso ZSF por la carga que supone para el sistema, y porque suplo sus bondades por decisión propia con otros mecanismo de salvaguarda.
Cada modelo de máquina de OVH y cada instalación deja diferencias sutiles que pueden hacer que uno tenga que modificar los datos de particiones, discos, interfaces de red.
LVM
En una instalación sin uso de RAID por software del instalador tenemos en la versión del instalador de OVH que instala 7.2-14 de Proxmox un volumen llamado vg en el disco primario
pvs
PV VG Fmt Attr PSize PFree
/dev/nvme0n1p5 vg lvm2 a-- 1.72t 0
lvscan
ACTIVE '/dev/vg/data' [1.72 TiB] inherit
Sobre el cual ha creado un volume llamado vg y un volumen lógico llamado data con el tamaño máximo
Mal por todo, porque asigna todo el espacio y no permite hacer snapshots.
Este modelo no me sirve pues yo nunca uso virtualización por OpenVZ así que hay que eliminar y reconstruir
Copia de la partición
Parada de proxmox
AVISO IMPORTANTE — Proxmox VE 7 y posteriores
/etc/pvees un sistema de ficheros FUSE (pmxcfs) montado porpve-cluster.service. Al pararpve-clusterse desmonta/etc/pveentero, lo que rompe/root/.ssh/authorized_keys— que es un symlink a/etc/pve/priv/authorized_keys. Resultado: sshd deja de aceptar tu clave pública y pierdes el acceso remoto hasta arrancarpve-clusterde nuevo.Para tocar
/var/lib/vz(lo que hace este tip) NO es necesario pararpve-cluster. Basta conpvedaemonypveproxy. Mantenerpve-clusterarriba preserva el acceso SSH durante toda la operación.
Versiones anteriores a la 7
systemctl stop pve-cluster pvedaemon pveproxy pvestatsd
Versiones 7 / 8 / 9 (recomendado)
systemctl stop pvedaemon pveproxy
Si por algún motivo necesitas parar también pve-cluster (raro), hazlo dentro de un único batch que lo levante antes de terminar, y no te desconectes de la sesión SSH viva mientras esté parado:
systemctl stop pve-cluster pvedaemon pveproxy
# ... operaciones rápidas sobre /var/lib/vz ...
systemctl start pve-cluster pvedaemon pveproxy
Copia de /var/lib/vz
mkdir /old_vz
rsync -avv --progress /var/lib/vz/ /old_vz/
umount /var/lib/vz
Debemos por seguridad editar /etc/fstab para eliminar o comentar el punto de montaje de /var/lib/vz/ por si ocurriera algún reinicio por despiste
Eliminación del volumen
lvchange -an /dev/vg/data
lvremove /dev/vg/data
Logical volume "data" successfully removed
Creación de un volumen menor
Por si acaso, un dia queremos una instancia tipo OpenVZ crearemos un volumen lógico pequeño pero suficiente para que esté ahí, por si un día lo queremos usar.
lvcreate -n data --size 20GB vg
WARNING: ext4 signature detected on /dev/vg/data at offset 1080. Wipe it? [y/n]: y
Wiping ext4 signature on /dev/vg/data.
Logical volume "data" created.
pvscan
PV /dev/nvme0n1p5 VG vg lvm2 [1.72 TiB / <1.71 TiB free]
Total: 1 [1.72 TiB] / in use: 1 [1.72 TiB] / in no VG: 0 [0 ]
mkfs.xfs /dev/vg/data
meta-data=/dev/vg/data isize=512 agcount=16, agsize=327680 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=0
data = bsize=4096 blocks=5242880, imaxpct=25
= sunit=32 swidth=32 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Discarding blocks...Done.
Obtención del UUID
blkid
…
/dev/mapper/vg-data: UUID="c0ede30d-f8a6-4897-a392-39c9dfc542a6" BLOCK_SIZE="4096" TYPE="xfs"
Edición de fstab
UUID=c0ede30d-f8a6-4897-a392-39c9dfc542a6 /var/lib/vz xfs defaults 0 0
Restauración de ficheros del directorio
rsync -avv --progress /old_vz/ /var/lib/vz/
systemctl restart pve-cluster pvedaemon pveproxy pvestatsd
Creación de volúmenes LVM
En mi caso, y en este en particular, no deseo ampliar el volumen, sino que prefiero tener 3 volúmenes independientes, por el tipo de máquina que uso y el uso que se va a dar, ya que la velocidad y cargas en el proceso, me son más interesante con 3 volúmenes, que con uno, a la par que la posibilidad de una rotura de LVM es mayor y un riesgo que llevo años sin querer sufrirlo (que alguna vez lo he sufrido) y en los últimos 8 años, no he tenido ningún percance con varias máquinas con este aprovechamiento.
Reconocimiento de discos
fdisk -l
Disk /dev/nvme1n1: 1.75 TiB, 1920383410176 bytes, 3750748848 sectors
Disk model: SAMSUNG MZQL21T9HCJR-00A07
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 131072 bytes / 131072 bytes
Disk /dev/nvme2n1: 1.75 TiB, 1920383410176 bytes, 3750748848 sectors
Disk model: SAMSUNG MZQL21T9HCJR-00A07
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 131072 bytes / 131072 bytes
Disk /dev/nvme0n1: 1.75 TiB, 1920383410176 bytes, 3750748848 sectors
Disk model: SAMSUNG MZQL21T9HCJR-00A07
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 131072 bytes / 131072 bytes
Disklabel type: gpt
Disk identifier: 991EADF9-826A-4A35-B37C-5A1C3D255A5D
Device Start End Sectors Size Type
/dev/nvme0n1p1 2048 1048575 1046528 511M EFI System
/dev/nvme0n1p2 1048576 3145727 2097152 1G Linux filesystem
/dev/nvme0n1p3 3145728 45088767 41943040 20G Linux filesystem
/dev/nvme0n1p4 45088768 47185919 2097152 1G Linux filesystem
/dev/nvme0n1p5 47185920 3750739967 3703554048 1.7T Linux LVM
/dev/nvme0n1p6 3750744752 3750748814 4063 2M Linux filesystem
Partition 6 does not start on physical sector boundary. // No importante
Disk /dev/mapper/vg-data: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 131072 bytes / 131072 bytes
Tenemos pues los discos nvme1n1y nvme2n1 disponibles
Creación de los grupos de volúmenes
Como uso una dinámica de nombres para así hacer más fácil las migraciones entre máquinas Proxmox, haré lo mismo.
Es importante crear los volúmenes de almacenamiento en particiones y no sobre el disco completo.
Partición
Usare mi Parted mejor que fdisk
Creamos las etiquetas
parted -s /dev/nvme1n1 mklabel gpt
parted -s /dev/nvme2n1 mklabel gpt
Creamos las particiones
parted -s /dev/nvme1n1 mkpart primary 0% 100%
parted -s /dev/nvme2n1 mkpart primary 0% 100%
Creación de los volúmenes
vgcreate lvm /dev/nvme1n1p1
Physical volume "/dev/nvme1n1p1" successfully created.
Volume group "lvm" successfully created
vgcreate lvm2 /dev/nvme2n1p1
Physical volume "/dev/nvme2n1p1" successfully created.
Volume group "lvm2" successfully created
pvscan
PV /dev/nvme1n1p1 VG lvm lvm2 [<1.75 TiB / <1.75 TiB free]
PV /dev/nvme2n1p1 VG lvm2 lvm2 [<1.75 TiB / <1.75 TiB free]
PV /dev/nvme0n1p5 VG vg lvm2 [1.72 TiB / <1.71 TiB free]
Total: 3 [<5.22 TiB] / in use: 3 [<5.22 TiB] / in no VG: 0 [0 ]
Final
A partir de aquí, ya tenemos nuestra estructura deseada en LVM para Proxmox.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Red OVH vrack para Proxmox 7
Introducción
El artículo es para un escenario de uso del vrack de OVH en un escenario específico. El alcance es dejar un tip, que uso muy a menudo, y en el que pongo énfasis en poder utilizar asegurándome de que si algo falla, puedo volver atrás con facilidad.
Configurar la red para OVH Rack con Proxmox 7
Copiar configuracion original
rsync -avv /etc/network/interfaces /root/interfaces.bak
Editar la configuración
Editamos la interface que puede ser diferente en cada caso pues con el tiempo cambian, y con los modelos de OVH cambian su forma de conexión a OVH
Es importante entender que hay dos interfaces de red y que esas son las que debemos configurar para usar vrack.
El modelo que uso, es particular, para mis necesidades. Hay muchas formas de configurar la red con vrack dependiendo de que estemos desplegando en nuestra máquina Proxmox y la red que queremos.
auto lo
iface lo inet loopback
iface eno1 inet manual
#auto vmbr0
#iface vmbr0 inet static
# address IP.IP.IP.2/24
# gateway IP.IP.IP.254
# bridge-ports eno1
# bridge-stp off
# bridge-fd 0
# hwaddress XX:XX:XX:XX:XX:XX
# nuevo modelo OVH DHCP
auto vmbr0
iface vmbr0 inet dhcp
address IP.IP.IP.IP/24
gateway IP.IP.IP.254
bridge-ports eno1
bridge-stp off
bridge-fd 0
# for routing
auto vmbr1
iface vmbr1 inet manual
bridge_ports dummy0
bridge_stp off
bridge_fd 0
# Bridge vrack 1.5
auto vmbr2
iface vmbr2 inet manual
bridge_ports eno2
bridge_stp off
bridge_fd 0
Un consejo por si hay que reiniciar y usar el IPMI para arreglarlo si la cosa no ha funcionado. Cambiar la contraseña por una sin signos ya que el IPMI no es precisamente amigable con los teclados nacionales.
Reinicio
Hacemos un shutdown de la máquina, y ya tendríamos nuestra red con vrack instalada.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Como arreglar el error Sender address rejected: need fully-qualified address (in reply to RCPT TO command)
Introducción
Algunas veces tenemos hosts (máquinas) de servicio, como Proxmox, en las que las peculiaridades y operativas, nos dejan con ciertos problemas de envío de correo, como los enviados por root (alertas, etc) que son enviados con el nombre corto de hosten lugar del FQDN. Están configurados con Postfix, y el servidor remoto, no permite este tipo de envío de correos (normal) por lo que debemos hacer un mapping en el servidor que está enviando los correos con el hostname corto.
Jan 29 00:00:19 smtp postfix/smtpd[389410]: NOQUEUE: reject: RCPT from pro18.XXX.XXX[Z.Z.Z.Z]: 504 5.5.2 <root@pro18>: Sender address rejected: need fully-qualified address; from=<root@pro18> to=<sistemas@mydomain.com> proto=ESMTP helo=<pro18.XXX.XXX>
Solución
Crear el fichero /etc/postfix/canonical
@local @pro18.mydomain.tld
@pro18 @pro18.mydomain.tld
Añadir la referencia a este fichero de hash
canonical_maps = hash:/etc/postfix/canonical
Activar el fichero de hash
postmap /etc/postfix/canonical
service postfix restart
Documentación
Postfix :: Canonical address mapping
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Proxmox, Hetzner, y bloques de Ips adicionales en modo Routed
Introducción
Tra una experiencia desastrosa con el proveedor Scaleway y su sistema Elastic Metal decidí que lo mejor era marcharme. Dado que lo único que me queda allí, era una máquina de Proxmox con failover de máquinas en #OVH, revise los requerimientos de tráfico (Hetzner te da solo 20 TB de tráfico de salida) y me sobraba, ya que la mayoría casi 24TB es tráfico de entrada.
Aunque ya había estado allí hace muchos años, nunca lo hice con Proxmox. Os dejo aquí mi experiencia, ya que sus manuales son un poco cuadriculados y ausente para ciertas cosas, y su soporte es nulo, más allá de enviarte a sus manuales.
Casi todos los soportes de grandes proveedores de Hosting y Colo, son parecidos. En cierta manera les entiendo, pero si dan 0 soporte sus manuales tienen que ser impecables.
Proxmox Modo Routed en lugar de bridge
El porqué es claro. Hetzner solo te permite 7 ips por servidor o pasas por caja para coger un bloque, y sus bloques no funcionan en modo bridge.
El modo bridge es como el OVH para IP Failover. Tienes que asignar un MAC vía ticket, robot, api.. El método routed no.
El Manual Hetztner es necesario leerlo, o puedes llevarte una sorpresa.
En mi caso, la instalación estaba clara: Sin raid (por software es una patata, y además, el alcance de este servidor no requiere de raid), modelo de Routed forzado por el sistema de Hetzner para bloques de IPS adicionales.
Bien lo primero que observe y que produjo un choque,m fue que las imágenes de las acciones en el frontend de Proxmox para crear y modificar la red, no concuerdan con lo que luego graba en el fichero /etc/network/interfaces
Además hay algunos puntos sutiles respecto a la notación de algunas IP.
IPV4/CIDR
El ejemplo te puede llevar a error porque te pone un CIDR /26 tanto en el texto como el gráfico, si mayor explicación.
Resulta que Hetzner no te entrega toda la información en su Robot, y por tanto te aconsejo que calcules tu red.
Por si te olvidaste cómo hacerlo mejor te dejo esta calculadora de redes aunque es posible que sea mejor que Hetzner te lo diga en un ticket.
Fichero /etc/network/interfaces
En vez del frontend pasamos a modo shell
Notas sobe algunos elementos usados
- CIDR Classless Inter-Domain Routing
- enp41s0 es la interfaz de red que puede ser distinta según modelo.
source /etc/network/interfaces.d/*
auto lo
iface lo inet loopback
iface lo inet6 loopback
auto enp41s0
iface enp41s0 inet static
address IP_SERVIDOR/CIDR
gateway GATEWAY_IP_SERVIDOR
up route add -net IP_BLOQUE_IPS netmask 255.255.NETMASK_BLOQUE gw IP_SERVIDOR/ dev enp41s0
#Routed mode
iface enp41s0 inet6 static
address SUBNET_IPV6::2/64 # Atención al 2
gateway fe80::1 # Revisar al gateway que te da Hetzner para el bloque IPv6
auto vmbr0
iface vmbr0 inet static
address IP_SERVIDOR/32
bridge-ports none
bridge-stp off
bridge-fd 0
iface vmbr0 inet6 static
address SUBNET_IPV6::2/64
/etc/network/interfaces.d/vm-routes
iface vmbr0 inet static
#up ip route add IP_BLOQUE_IPS/28 dev vmbr0 # no me funciono
up ip route add IP_BLOQUE_IPS.193/32 dev vmbr0
up ip route add BLOQUE_IPS.194/32 dev vmbr0
up ip route add BLOQUE_IPS.195/32 dev vmbr0
up ip route add BLOQUE_IPS.196/32 dev vmbr0
up ip route add BLOQUE_IPS.197/32 dev vmbr0
up ip route add BLOQUE_IPS.198/32 dev vmbr0
up ip route add BLOQUE_IPS.199/32 dev vmbr0
up ip route add BLOQUE_IPS.200/32 dev vmbr0
up ip route add BLOQUE_IPS.201/32 dev vmbr0
up ip route add BLOQUE_IPS.202/32 dev vmbr0
up ip route add BLOQUE_IPS.203/32 dev vmbr0
up ip route add BLOQUE_IPS.204/32 dev vmbr0
up ip route add BLOQUE_IPS.205/32 dev vmbr0
up ip route add BLOQUE_IPS.206/32 dev vmbr0
iface vmbr0 inet6 static
up ip -6 route add SUBNET_IPV6::/64 dev vmbr0
Configserver Firewall
A mi no me gusta nada el firewall que usa Proxmox, así que sigo usando Configserver CSF, pero esto requiere ciertos añadidos
Necesitamos pasarle a CSF la interfaz que hace de Bridge o enrutador.
Para ello añadimos el fichero /etc/csf/csfpre.sh con los siguientes datos.
#!/bin/sh
iptables -A INPUT -i vmbr0 -j ACCEPT
iptables -A OUTPUT -o vmbr0 -j ACCEPT
iptables -A FORWARD -j ACCEPT -p all -s 0/0 -i vmbr0
iptables -A FORWARD -j ACCEPT -p all -s 0/0 -o vmbr0
Y reiniciamos CSF con csf -ra
Ahora el tráfico funcionará hacia los hosts.
VPS KVM
Centos 7
De momento solo he migrado dos máquinas con Centos 7, más adelante pondré los datos de máquinas con modelo Ubuntu y Debian.
cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=none
IPADDR=BLOQUE_IPS.XXX
NETMASK=255.255.255.255
SCOPE="peer IP_SERVIDOR_PROXMOX"
IPV6INIT=no
GATEWAY=peer IP_SERVIDOR_PROXMOX
Nota importante
Tras dos problemas con sod VPS, he encontrado que esta configuración sólo funciona usando NetworkManager. (fecha: 26/02/2023). Espero el lunes o martes tener una respuesta distinta, ya que el NetworkManager nio debe estar axctivo con el pesado de cPanel.
El problema reside en que no levanta la tabla de rutas de forma correcta, por lo que no hay enrutamiento correcto hacia internet
Importante revisar por si venimos de algún proveedor con otro sistema, que no tengan algún fichero de rutas especificado de su despliegue.
Lecturas por si acaso
Por ejemplo si usas un Centos 6 que teneia el sistema udev antiguo, y cargaba las tarejtas de red con su mac
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Desactivar los mensajes de log en la consola (Proxmox)
Introducción
Una de las cosas que hago al comenzar con una nueva máquina de Proxmox, es desactivar la redirección de los mensajes de kernel log hacia la consola virtual. Es una pesadilla si te olvidas de de hacerlo, pues el próximo día que necesites acceder a tu servidor Proxmox, vía KVM a distancia (no la con sola de Proxmox si no la de OVH por ejemplo, la de Hetzner) sufrirás la continua emisión de logs a la consola virtual, lo cual hace muchas veces imnposible el trabajo en la consola.
Solución para desactivar los mensajes del log en la consola virtual
/etc/sysctl.conf
Bien como Proxmox se ejecuta sobre una Debian, edita el fichero /etc/sysctl.conf y dejalo como esta aquí debajo:
# Uncomment the following to stop low-level messages on console
kernel.printk = 3 3 3 3
No necesitas hacer un restart si no quieres.
Puedes activar la configuración como siempre que modificas ese fichero con:
sudo sysctl -p
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Proxmox: Servicios Colgados - Diagnóstico y Soluciones
Descripción del Problema
Proxmox ocasionalmente experimenta un estado donde los servicios del sistema de gestión se "cuelgan", resultando en:
- Frontend web inaccesible o extremadamente lento
- Comandos de Proxmox no responden (pvesh, pvecm, qm, pct)
- VMs/Containers siguen funcionando pero sin gestión
- SSH funciona pero utilidades de Proxmox fallan
- Contenedores fucionales pero lenbtos y pesados sin presentar cargar que lo explique.
Diagnóstico
Verificación del Estado de Servicios
# Comprobar posibles problemas con NFS
df -h
# Comprobar estado de servicios críticos
systemctl status pve-cluster
systemctl status pvedaemon
systemctl status pvestatd
systemctl status pveproxy
# Verificar logs para identificar errores
journalctl -u pve-cluster -f
journalctl -u pvedaemon -f
tail -f /var/log/pve/tasks/active
Indicadores Comunes
- pve-cluster: Estado "failed" o "timeout"
- pvedaemon: No responde a peticiones API
- pveproxy: Error 502/503 en interfaz web
- Alta carga del sistema sin razón aparente
Verificación de Recursos
# Comprobar memoria y CPU
free -h
top -n 1
# Estado del almacenamiento
df -h
iostat -x 1 3
# Conectividad de cluster (si aplica)
pvecm status
Soluciones
Solución Rápida (Restart de Servicios)
# Secuencia de reinicio recomendada
service pve-cluster restart && \
service pvedaemon restart && \
service pvestatd restart && \
service pveproxy restart
# Verificar que los servicios han iniciado correctamente
systemctl status pve-cluster pvedaemon pvestatd pveproxy
Solución Alternativa por Pasos
# Si el comando conjunto falla, reiniciar individualmente
systemctl stop pveproxy
systemctl stop pvestatd
systemctl stop pvedaemon
systemctl stop pve-cluster
# Esperar unos segundos y reiniciar en orden
systemctl start pve-cluster
sleep 5
systemctl start pvedaemon
sleep 3
systemctl start pvestatd
systemctl start pveproxy
Troubleshooting Avanzado
Si pve-cluster no inicia:
# Verificar quorum (en clusters)
pvecm expected 1
# Limpiar archivos de lock problemáticos
rm -f /var/lib/pve-cluster/.pmxcfs.lockfile
systemctl start pve-cluster
Si persisten problemas:
# Reinicio completo del stack de Proxmox
systemctl restart pve-cluster pvedaemon pvestatd pveproxy
# Reinicio completo del stack de Proxmox completo. Opción más dura.
systemctl restart pve-cluster pvedaemon pvestatd pveproxy corosync
# Como último recurso (CUIDADO: puede afectar VMs)
# Si tienes un KVM remoto para la máquina baremetal es el momento de activarl y tenerla abierta
reboot
Prevención
Monitoreo Proactivo
# Script de verificación periódica
#!/bin/bash
services=("pve-cluster" "pvedaemon" "pvestatd" "pveproxy")
for service in "${services[@]}"; do
if ! systemctl is-active --quiet $service; then
echo "$(date): $service is down" >> /var/log/pve-health.log
systemctl restart $service
fi
done
Configuración de Cron
# Añadir al crontab (cada 5 minutos)
*/5 * * * * /path/to/pve-health-check.sh
Causas Comunes
- Sobrecarga de memoria en el host Proxmox
- Problemas de red en configuraciones de cluster
- Almacenamiento lento o con alta latencia
- Actualizaciones parciales o interrumpidas
- Configuraciones de firewall bloqueando puertos internos
- Problemas con monatajes NFS bloquenado el subsistema de ficheros PVE
Puertos Críticos de Proxmox
- 8006: Interfaz web HTTPS
- 5404/5405: Corosync (cluster)
- 111/2049: NFS (si se usa)
- 3128: Proxy de descarga
Logs Importantes
/var/log/pve/tasks/active- Tareas en ejecución/var/log/daemon.log- Servicios del sistema/var/log/pve/cluster.log- Información del clusterjournalctl -u pve-*- Logs específicos de servicios
Notas Adicionales
⚠️ Importante: Los VMs y containers continúan ejecutándose durante estos problemas, solo se ve afectada la gestión.
✅ Tip: Mantener siempre acceso SSH alternativo para poder ejecutar estos comandos de recuperación.
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Ampliación de disco (basado en qcow2) en sistema virtualizado KVM (proxmox)
Contexto
Proceso para ampliar un disco virtual qcow2 en Proxmox cuando el sistema operativo invitado usa LVM y la tabla de particiones GPT no reconoce el nuevo tamaño tras la ampliación.
Escenario inicial
- Disco qcow2 ampliado desde ~36GB a 46GB en Proxmox
- Sistema operativo no reconoce el espacio adicional
- Estructura: sda1 (BIOS boot), sda2 (boot), sda3 (LVM PV)
Síntomas
fdisk /dev/sda
Welcome to fdisk (util-linux 2.39.3).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
GPT PMBR size mismatch (75497471 != 96468991) will be corrected by write.
The backup GPT table is not on the end of the device. This problem will be corrected by write.
This disk is currently in use - repartitioning is probably a bad idea.
It's recommended to umount all file systems, and swapoff all swap
partitions on this disk.
Command (m for help): p
Disk /dev/sda: 46 GiB, 49392123904 bytes, 96468992 sectors
Disk model: QEMU HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: EBD99DE4-BA1E-4F14-9EFF-FE7FE140CF1A
Device Start End Sectors Size Type
/dev/sda1 2048 4095 2048 1M BIOS boot
/dev/sda2 4096 3674111 3670016 1.8G Linux filesystem
/dev/sda3 3674112 75497438 71823327 34.2G Linux filesystem
Command (m for help): q
Observamos el mensaje de problemas y el de la capacidad de discos, que no es renocido pese a que su tamaño si lo es, 46Gib vs 36Gib
Prerequisitos
- Backup: Crear snapshot en Proxmox antes de proceder
- Acceso: Conexión SSH o consola al sistema invitado
- Herramientas: gdisk, parted, lvm2 (generalmente preinstalados)
Proceso paso a paso
1. Verificar estado inicial
❯ pvscan
PV /dev/sda3 VG ubuntu-vg lvm2 [<34.25 GiB / 0 free]
Total: 1 [<34.25 GiB] / in use: 1 [<34.25 GiB] / in no VG: 0 [0 ]
2. Corregir estructura GPT
gdisk /dev/sda
GPT fdisk (gdisk) version 1.0.10
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): v
Problem: The secondary header's self-pointer indicates that it doesn't reside
at the end of the disk. If you've added a disk to a RAID array, use the 'e'
option on the experts' menu to adjust the secondary header's and partition
table's locations.
Warning: There is a gap between the secondary partition table (ending at sector
75497470) and the secondary metadata (sector 75497471).
This is helpful in some exotic configurations, but is generally ill-advised.
Using 'k' on the experts' menu can adjust this gap.
Caution: Partition 3 doesn't end on a 2048-sector boundary. This may
result in problems with some disk encryption tools.
Identified 1 problems!
Command (? for help): x
Expert command (? for help): e
Relocating backup data structures to the end of the disk
Expert command (? for help): w
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y
OK; writing new GUID partition table (GPT) to /dev/sda.
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot or after you
run partprobe(8) or kpartx(8)
The operation has completed successfully.
3. Redimensionar partición
# Expandir la partición al 100% del disco disponible
parted /dev/sda resizepart 3 100%
4. Expandir Physical Volume
# Redimensionar el PV para usar todo el espacio de la partición
❯ pvresize /dev/sda3
Physical volume "/dev/sda3" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
# Verificar el resultado
> pvdisplay /dev/sda3
--- Physical volume ---
PV Name /dev/sda3
VG Name ubuntu-vg
PV Size <44.25 GiB / not usable 16.50 KiB
Allocatable yes (but full)
PE Size 4.00 MiB
Total PE 11327
Free PE 0
Allocated PE 11327
PV UUID NzNz30-KIRH-bWmQ-aSFy-N0mU-x1lt-hQ62uH
5. Expandir Logical Volume y filesystem
# Conocer el VL de aplicación (Pueden ser varios, y cada uno una cnatidad)
❯ lvscan
ACTIVE '/dev/ubuntu-vg/ubuntu-lv' [<34.25 GiB] inherit
# Expandir el LV usando todo el espacio libre disponible (ejemplo)
❯ lvresize --extents +100%FREE --resizefs /dev/ubuntu-vg/ubuntu-lv
Size of logical volume ubuntu-vg/ubuntu-lv changed from <34.25 GiB (8767 extents) to <44.25 GiB (11327 extents).
Logical volume ubuntu-vg/ubuntu-lv successfully resized.
resize2fs 1.47.0 (5-Feb-2023)
Filesystem at /dev/mapper/ubuntu--vg-ubuntu--lv is mounted on /; on-line resizing required
old_desc_blocks = 5, new_desc_blocks = 6
The filesystem on /dev/mapper/ubuntu--vg-ubuntu--lv is now 11598848 (4k) blocks long.
# El flag --resizefs ejecuta automáticamente resize2fs
6. Verificación final
# Verificar espacio disponible
df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ubuntu--vg-ubuntu--lv 44G 32G 10G 77% /
# Vista general de la estructura
lsblk
...
sda 8:0 0 46G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 1.8G 0 part /boot
└─sda3 8:3 0 44.2G 0 part
└─ubuntu--vg-ubuntu--lv 252:0 0 44.2G 0 lvm /
sr0 11:0 1 1024M 0 rom
...
# Verificar estado LVM
vgdisplay
lvdisplay
Mensajes esperados
Durante gdisk verify (v)
Problem: The secondary header's self-pointer indicates that it doesn't reside at the end of the disk
Warning: There is a gap between the secondary partition table and secondary metadata
Caution: Partition 3 doesn't end on a 2048-sector boundary
Nota: Estos son problemas esperados tras ampliar el disco y se corrigen con el comando e en expert mode.
Durante lvresize
Physical volume "/dev/sda3" changed
Size of logical volume changed from <34.25 GiB to <44.25 GiB
resize2fs: on-line resizing required
The filesystem is now XXXXXX (4k) blocks long.
Consideraciones importantes
Seguridad
- Sin downtime: Todo el proceso se ejecuta en caliente
- Solo crecimiento: No se mueven ni reducen datos existentes
- LVM como protección: Añade capa adicional de seguridad
Orden crítico
- Corregir GPT antes que redimensionar particiones
- Redimensionar partición antes que PV
- Expandir PV antes que LV
Troubleshooting común
- "Disk in use" warning: Normal, se puede ignorar en operaciones de crecimiento
- GPT mismatch: Esperado tras resize de qcow2, se corrige con gdisk
- Alignment warnings: Generalmente no críticos en discos virtuales
Comandos de verificación post-proceso
# Verificar que no quedan problemas GPT
gdisk /dev/sda
v
q
# Estado final del disco
fdisk -l /dev/sda
# Estado LVM completo
pvs && vgs && lvs
# Espacio en filesystem
df -h /
Resultado esperado
- Disco reconocido con nuevo tamaño completo
- Sin mensajes de error en GPT
- Espacio adicional disponible en el filesystem raíz
- Sistema operativo funcionando normalmente
- Proceso validado en Ubuntu 22.04 sobre Proxmox VE con discos qcow2
- Generado el 26/09/2025 por Abdelkarim Mateos Sánchez - Administrador de Sistemas
Aviso
Esta documentación y su contenido, no implica que funcione en tu caso o determinados casos. También implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad. El contenido el contenido se entrega, tal y como está, sin que ello implique ningún obligación ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
Ampliación de disco en sistema virtualizado KVM (proxmox)
Introduccion
En un escenario de uso de discos virtuales, como KVM, Proxmox y otros, a veces es necesario una ampliacion del disco. Si usamos LVM esto es posible y sencillo.
Convenciones
Ciertas cosas que hay en esta entrada, asi como en otras, requieren un conocimiento previo. No es un sitio para copiar y pegar sino para entender y hacer
No siempre es el disco vda, no siempre es la particion 1, y asi sucesivamente.
Ampliacion de una disco virtual KVM
La ampliacion de un disco LVM es posible una vez que hemos realizado el cambio virtual del tamano de la unidad LVM.
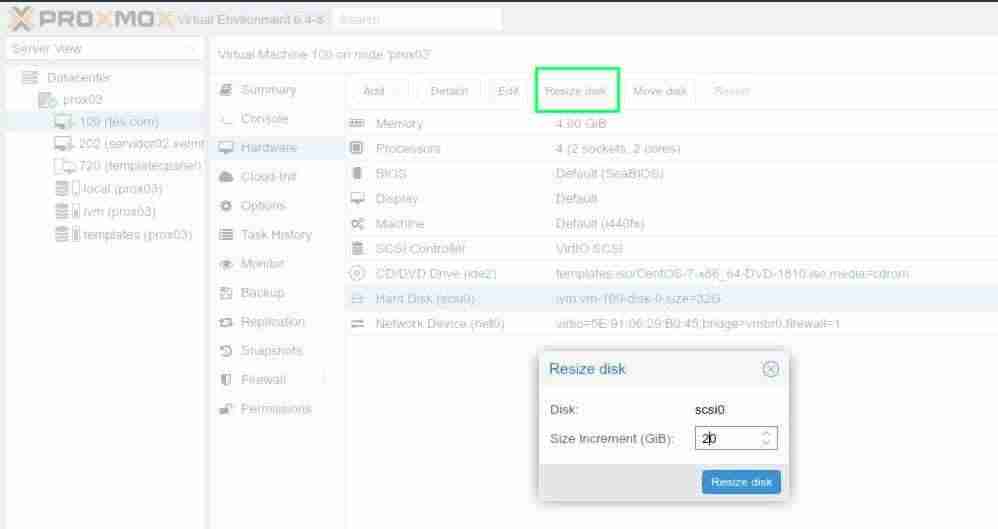
En el caso de Proxmox acudimos a la administracion de nuestro proxmox:
- Seleccionamos el VPS
- Click en **Resize Disk"
- Incrementamos el tamano.
Si el aumento de tamano implica un tamano final mayor de 2 TiB deberas tener el esquema de particiones GPT de lo contrario, tendras que modificar bajo tu responsabilidad el esquema MBR a GPT. Esta entrada no trata de eso, y para ello es aconsejable el uso de Gparted Live, lo cual no siempre es posible.
El articulo interpreta que conoces el uso de ciertos comando, que sustituiran el dispositivo (disco) por el tuyo, y que sabes como obtener el esquema de tu disco (particiones)
Consejo sobre particionamiento durante la instalacion
Es aconsejable el uso de GPT y de ello hablamos en nuestra wiki, Instalacion GPT con el instalador Centos 7 en discos menores de 2 TiB
Verificacion en un KVM basado en LVM
Una vez que hemos ampliado el disco, podemos verificar el cambio de tamano en nuestro VPS. Esto funcionara hasta que reiniciemos la maquina. Despues ya no nos informara.
vda, vdb, sda, ... son nombres de dispositivos. Debes consultar cuales son tus dispositivos de disco usando
fdisk -ly usar el apropiado en el comando
dmesg | grep vda
...
[ 222.436098] vda: detected capacity change from 32212254720 to 37580963840
Imprimir la tabla actual del disco
fdisk -l /dev/vda | grep ^/dev
/dev/vda1 * 2048 1026047 512000 83 Linux
/dev/vda2 1026048 62914559 30944256 8e Linux LVM
Conocer el uso de las particiones en el sistema LVM
pvscan
PV /dev/vda2 VG centos lvm2 [<29,51 GiB / 40,00 MiB free]
Total: 1 [<29,51 GiB] / in use: 1 [<29,51 GiB] / in no VG: 0 [0 ]
lvscan
ACTIVE '/dev/centos/swap' [3,00 GiB] inherit
ACTIVE '/dev/centos/root' [<26,47 GiB] inherit
Metodo rapido y recomendado: growpart (GPT, no interactivo)
Desde hace años existe growpart (paquete cloud-guest-utils en Debian/Ubuntu, cloud-utils-growpart en RHEL/Alma/Rocky), que automatiza en un solo comando lo que en los casos anteriores se hace a mano con parted: extiende la partición para ocupar todo el espacio nuevo y reubica la tabla GPT de respaldo al final del disco (el "Fix" que parted pide de forma interactiva). Es no interactivo, idempotente y seguro sobre particiones en uso, por lo que es la vía preferida en discos GPT.
Para la pila típica disco virtual → partición → PV → VG → LV → XFS, una vez ampliado el disco en Proxmox (Resize Disk), el procedimiento completo en caliente (sin desmontar) es:
# 1. Crecer la partición (ej: partición 1 del disco vdd). growpart reubica el backup GPT solo
growpart /dev/vdd 1
# 2. Extender el Physical Volume de LVM al nuevo tamaño de la partición
pvresize /dev/vdd1
# 3. Extender el Logical Volume con todo el espacio libre del VG
lvextend -l +100%FREE /dev/stor2/stor2_vol
# 4. Crecer el filesystem (XFS crece montado; para EXT4 usar resize2fs)
xfs_growfs /srv/storage2
Ejemplo real de salida (ampliación de /srv/storage2 de 4 TiB a 8 TiB sobre /dev/vdd):
growpart /dev/vdd 1
CHANGED: partition=1 start=2048 old: size=8589932511 end=8589934558 new: size=17179867103 end=17179869150
pvresize /dev/vdd1
Physical volume "/dev/vdd1" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
lvextend -l +100%FREE /dev/stor2/stor2_vol
Size of logical volume stor2/stor2_vol changed from <4.00 TiB to <8.00 TiB.
Logical volume stor2/stor2_vol successfully resized.
xfs_growfs /srv/storage2
data blocks changed from 1073740800 to 2147482624
Por qué funciona en caliente:
growpartusa el ioctlBLKPG_RESIZE_PARTITION, que actualiza una sola partición sin re-leer toda la tabla, así que no falla aunque la partición esté en uso como PV activo de LVM. Y al reubicar él mismo el backup GPT, evita el error típico de responder mal al diálogo interactivo departed. Si el sistema no traegrowpart:apt install cloud-guest-utils(Debian/Ubuntu) odnf install cloud-utils-growpart(RHEL/Alma/Rocky).
Caso 1: Particion primaria con LVM (GPT o MBR simple)
Este es el caso mas comun en instalaciones modernas con GPT.
Ampliar la particion fisica
parted /dev/vda
GNU Parted 3.1
Usando /dev/vda
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 37,6GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Numero Inicio Fin Tamano Typo Sistema de ficheros Banderas
1 1049kB 525MB 524MB primary xfs arranque
2 525MB 32,2GB 31,7GB primary lvm
(parted) resizepart 2 100%
(parted) quit
Asignar el nuevo tamano al volumen fisico de LVM
pvresize /dev/vda2
Physical volume "/dev/vda2" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
Caso 2: Particion extended con logical (MBR clasico)
IMPORTANTE: Algunas instalaciones antiguas (especialmente Debian/Ubuntu) usan esquema MBR con particiones extended y logical. En este caso hay que ampliar DOS particiones en orden.
Ejemplo de estructura:
Number Start End Size Type File system Flags
1 1049kB 512MB 511MB primary ext2 boot
2 513MB 698GB 697GB extended
5 513MB 698GB 697GB logical lvm
Aqui vda2 es un contenedor (extended) y vda5 es la particion real con LVM (logical).
Paso 1: Ampliar la particion extended
parted /dev/vda
(parted) resizepart 2 100%
(parted) quit
Paso 2: Ampliar la particion logical
parted /dev/vda
(parted) resizepart 5 100%
(parted) quit
Verificar que ambas particiones ahora ocupan todo el espacio:
parted /dev/vda print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 752GB
Number Start End Size Type File system Flags
1 1049kB 512MB 511MB primary ext2 boot
2 513MB 752GB 751GB extended
5 513MB 752GB 751GB logical lvm
Paso 3: Redimensionar el Physical Volume
CRITICO: El PV esta en la particion logical (vda5), NO en la extended (vda2):
pvresize /dev/vda5
Physical volume "/dev/vda5" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
Error comun: ejecutar pvresize /dev/vda2 da error "device is too small" porque vda2 es la extended, no contiene el PV.
Paso 4: Verificar el nuevo espacio disponible
vgs
VG #PV #LV #SN Attr VSize VFree
kvm330-vg 1 2 0 wz--n- <699.52g 50g
El VFree muestra el espacio nuevo disponible.
Redimensionar el volumen logico de LVM
Todo para una particion
lvresize --extents +100%FREE --resizefs /dev/centos/root
Size of logical volume centos/root changed from <26,47 GiB (6776 extents) to <31,51 GiB (8066 extents).
Logical volume centos/root successfully resized.
Resize Volumen Logico por tamano exacto a anadir
En un sistema con distintas particiones es diferente:
df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ubuntu--vg-ubuntu--lv 10G 2.7G 7.4G 27% /
/dev/mapper/ubuntu--vg-lv--usr 6.0G 5.6G 450M 93% /usr
/dev/mapper/ubuntu--vg-lv--home 5.0G 88M 5.0G 2% /home
/dev/mapper/ubuntu--vg-lv--var 6.0G 1.3G 4.8G 21% /var
Ampliar solo la particion /usr en 2GB:
lvextend -L+2G /dev/ubuntu-vg/lv-usr
Size of logical volume ubuntu-vg/lv-usr changed from 6.00 GiB to 8.00 GiB.
Logical volume ubuntu-vg/lv-usr successfully resized.
Expandir el sistema de archivos (para XFS):
xfs_growfs /dev/ubuntu-vg/lv-usr
data blocks changed from 1572864 to 2097152
Para EXT4 usar resize2fs o la opcion --resizefs en lvresize.
Mensajes de error comunes
Error en parted: tabla GPT al final del disco
A veces, es posible que tras un acceso con parted a nuestro dispositivo, podemos encontrar mensajes relativos a problemas derivados de los instaladores de Centos, de Ubuntu, segun cuando y como se hizo la particion.
Error: La copia de la tabla GPT no esta al final del disco, como deberia ser.
Arreglar/Fix/Descartar/Ignore/Cancelar/Cancel? Fix
Aviso: Not all of the space available to /dev/vda appears to be used
Arreglar/Fix/Descartar/Ignore? F
Responder Fix a estos mensajes para corregir la tabla GPT.
Con
growpart(ver el método congrowpartmás arriba) este diálogo no aparece: el fix del backup GPT lo realiza automáticamente.
Error pvresize: device is too small
pvresize /dev/vda2
Cannot use /dev/vda2: device is too small (pv_min_size)
0 physical volume(s) resized or updated / 0 physical volume(s) not resized
Este error ocurre cuando se intenta hacer pvresize sobre la particion extended en lugar de la logical. Verificar con pvscan cual es la particion correcta que contiene el Physical Volume.
Actualizacion 2024-03-21
En nuevas versiones de parted, por ejemplo en AlmaLinux 8, no es posible usar el comando interactivo como anteriormente. Debes hacerlo directamente en el shell:
parted /dev/sdx --script resizepart NumeroParticion 100%
Aviso
Esta documentacion y su contenido, no implica que funcione en tu caso o determinados casos. Tambien implica que tienes conocimientos sobre lo que trata, y que en cualquier caso tienes copias de seguridad.
El contenido se entrega, tal y como esta, sin que ello implique ninguna obligacion ni responsabilidad por parte de Castris
Si necesitas soporte profesional puedes contratar con Castris soporte profesional.
IPv6 para VMs en Proxmox sobre OVH bare-metal (NDP proxy)
- Fecha: 2026-05-23
- Autor: Abdelkarim Mateos
- Estado: vigente
- Aplicable a: servidores OVH bare-metal con dos NICs separadas (RISE / Advance / SYS) y Proxmox VE 8/9 como hypervisor KVM
- No aplica: OVH HG (NIC única + vRack en VLAN tagged), OVH Public Cloud, Hetzner Cloud o cualquier proveedor donde el switch del segmento público no haga filtrado por MAC
Nota sobre las direcciones de los ejemplos. Todas las IPv4, IPv6 y MAC que aparecen en este documento son valores de documentación reservados por la IETF: bloque
203.0.113.0/24(RFC 5737, TEST-NET-3) para IPv4 y prefijo2001:db8::/32(RFC 3849) para IPv6. Sustituir por los valores reales del servidor al aplicar. He preservado deliberadamente la topología característica de OVH — gateway IPv6 con muchos hextetsffy fuera del/64ruteado, requiriendoonlink— para que los ejemplos reflejen el comportamiento real. Publicar IPs reales en documentación pública es un señuelo gratuito para scanners — evítalo siempre.
Escenario
Pongo en marcha un OVH RISE-L (Ryzen 9, 128 GB RAM, 2× Intel I210) como host Proxmox VE 9 para alojar máquinas virtuales KVM. La intención: que las VMs tengan IPv6 público aprovechando el /64 que OVH enruta por defecto hacia el MAC del servidor.
El primer intento (asignar a la VM una dirección del /64 con el gateway OVH onlink, igual que se hace en Hetzner Cloud) no funciona — el NDP de la VM al gateway se queda en INCOMPLETE. Este documento explica por qué y cómo se resuelve con NDP proxy (ndppd) más un bridge interno.
Topología hardware OVH RISE
Las gamas RISE / Advance / SYS entregan dos NICs separadas, no agrupadas en LACP, sin bonding. Una va al switch público de OVH, la otra al vRack (red privada / IPs adicionales enrutadas).
| Modelo | Topología NICs |
|---|---|
| RISE / Advance / SYS | 2× NICs separadas — una pública, otra vRack |
| HG (High Grade / Game) | NIC única, vRack en VLAN tagged sobre la misma interfaz |
| Eco | Igual que RISE en topología, con limitaciones de garantía vRack |
En este documento la NIC pública es enp6s0 (mapeada al bridge vmbr0) y la NIC del vRack es enp7s0 (mapeada al bridge vmbr1). Cada modelo usa nombres distintos según firmware/kernel — comprobar con lspci -nn | grep Ether y ip -br link.
Recursos IP del ejemplo (documentación)
vmbr0(pública): IPv4 del bloque que OVH asigna al servidor (203.0.113.10/24) y un/64IPv6 enrutado al MAC del servidor (2001:db8:1:1::/64, gateway2001:db8:1:ffff:ff:ff:ff:ff).vmbr1(vRack): sin IP en el host, bridge limpio. Las VMs cogen IPs de los bloques que el cliente haya pedido enrutar al vRack.
Por qué el approach naive no funciona
Asignar a una VM una IPv6 del /64 con el gateway OVH onlink es lo que recomienda la documentación oficial OVH para el lado guest. Pero falla:
admin@vm:~$ ping6 2001:db8:1:ffff:ff:ff:ff:ff
From 2001:db8:1:1::100 icmp_seq=1 Destination unreachable: Address unreachable
admin@vm:~$ ip -6 neigh show
2001:db8:1:ffff:ff:ff:ff:ff dev eth1 INCOMPLETE
La VM envía una Neighbor Solicitation al gateway y nunca recibe Neighbor Advertisement de vuelta. Causa: el switch del segmento público de OVH hace filtrado por MAC. Solo deja entrar tramas cuyo MAC destino sea el del servidor — la respuesta del gateway, dirigida al MAC de la VM, se descarta en el switch.
En el vRack ese filtrado no está activo (es un L2 abierto, precisamente para esto). Por eso el IPv4 funciona "directo" en el vRack pero el IPv6 del /64 público no.
Arquitectura NDP proxy
La solución estándar es que el host responda NDP por las VMs. Ante el switch OVH solo existe un MAC (el del host); el routing IPv6 a cada VM se hace internamente en el kernel del host:
+--------------------+ +----------------------------+
| OVH router IPv6 | -- L2 --| enp6s0 → vmbr0 |
| ...:ffff:ff:ff::ff | | host: 2001:db8:1:1::1/128 |
+--------------------+ +-------------+--------------+
| kernel IPv6 forwarding
| proxy_ndp + ndppd
v
+----------------------------+
| vmbr2 (sin puerto físico) |
| host: 2001:db8:1:1::ffff/64|
+-------------+--------------+
|
+----------------+----------------+
v v v
VM-A VM-B VM-C
::100/64 ::101/64 ::102/64
gw ::ffff gw ::ffff gw ::ffff
Tres piezas:
- Host con
/128envmbr0— no se queda con el/64entero, solo con una IP propia (típicamente::1/128o::ffff/128). - Bridge interno
vmbr2sin puerto físico, con el/64y una IP que actúa de gateway para las VMs (en este ejemplo::ffff). ndppdescuchando envmbr0— responde a las NDP Solicitations del gateway OVH con el MAC del host para cualquier dirección dentro del/64. El kernel entonces enruta el tráfico haciavmbr2por la tabla v6, y de ahí a la VM correspondiente.
Sysctl obligatorios:
net.ipv6.conf.all.forwarding = 1— sin esto el host descarta paquetes IPv6 destinados a otras IPs.net.ipv6.conf.all.proxy_ndp = 1— habilita la lógica de NDP proxy del kernel.ndppdlo activa al arrancar pero conviene persistirlo por sysctl.
Configuración paso a paso
1. /etc/network/interfaces del host
Stanza relevante (Proxmox autogestiona la primera parte; estas líneas se añaden al final):
# IPv6 NDP-proxy approach
iface vmbr0 inet6 static
address 2001:db8:1:1::1/128
gateway 2001:db8:1:ffff:ff:ff:ff:ff
auto vmbr2
iface vmbr2 inet6 static
address 2001:db8:1:1::ffff/64
bridge-ports none
bridge-stp off
bridge-fd 0
Aplicar con ifreload -a — no hace falta reiniciar.
2. Sysctl persistente
/etc/sysctl.d/99-ipv6-ndp-proxy.conf:
net.ipv6.conf.all.forwarding = 1
net.ipv6.conf.all.proxy_ndp = 1
Aplicar con sysctl --system.
3. Instalar y configurar ndppd
apt-get install -y ndppd
/etc/ndppd.conf:
route-ttl 30000
proxy vmbr0 {
router no
timeout 500
ttl 30000
rule 2001:db8:1:1::/64 {
auto
}
}
Trampa de versión: el ejemplo distribuido en /usr/share/doc/ndppd/ndppd.conf-dist menciona el keyword static como "NEW", pero en la versión que trae Debian 13 Trixie (ndppd 0.2.4) static falla con Failed to load configuration file sin más detalle. Usar auto — funciona y resuelve dinámicamente vía /proc/net/ipv6_route.
Habilitar el servicio:
systemctl enable --now ndppd
systemctl is-active ndppd # debe responder 'active'
journalctl -u ndppd -n 20 # 'Failed to load' = error de sintaxis
4. Configurar las VMs
Por cloud-init en Proxmox:
qm set <VMID> --net1 virtio,bridge=vmbr2
qm set <VMID> --ipconfig1 "ip6=2001:db8:1:1::100/64,gw6=2001:db8:1:1::ffff"
Importante: el gateway de la VM es la IP del host en vmbr2 (::ffff), NO el gateway OVH. La VM rutea hacia el host, el host hace el forwarding hacia OVH.
Para Debian/Ubuntu sin cloud-init, en /etc/network/interfaces de la VM:
iface ens19 inet6 static
address 2001:db8:1:1::100/64
gateway 2001:db8:1:1::ffff
5. CSF (si se usa)
Si el host tiene CSF con IPV6 = "1", CSF deja la cadena FORWARD de ip6tables en policy DROP. Esto rompe el forwarding entre vmbr2 y vmbr0 — las VMs reciben IPv6 pero no pueden enviar.
Añadir un hook persistente en /usr/local/include/csf/post.d/10-ipv6-forward.sh:
#!/bin/sh
ip6tables -A FORWARD -i vmbr2 -o vmbr0 -j ACCEPT
ip6tables -A FORWARD -i vmbr0 -o vmbr2 -j ACCEPT
chmod +x y csf -r. CSF carga post.d/*.sh automáticamente tras cada restart.
Verificación
Desde dentro de una VM con la configuración aplicada:
admin@vm:~$ ip -6 addr show eth1 | grep inet6
inet6 2001:db8:1:1::100/64 scope global
admin@vm:~$ ping6 -c2 2606:4700:4700::1111
PING 2606:4700:4700::1111 56 data bytes
64 bytes from 2606:4700:4700::1111: icmp_seq=1 ttl=58 time=5.13 ms
64 bytes from 2606:4700:4700::1111: icmp_seq=2 ttl=58 time=5.14 ms
admin@vm:~$ ip -6 route show
2001:db8:1:1::/64 dev eth1 proto kernel
default via 2001:db8:1:1::ffff dev eth1 proto static
Desde el host:
# El gateway OVH debe aparecer REACHABLE, no INCOMPLETE
root@host:~$ ip -6 neigh show dev vmbr0 | grep ffff:ff
2001:db8:1:ffff:ff:ff:ff:ff lladdr 02:00:5e:00:00:01 router REACHABLE
# ndppd activo
root@host:~$ pidof ndppd
12345
# La tabla NDP proxy estática puede estar vacía — ndppd responde dinámicamente
root@host:~$ ip -6 neigh show proxy
(vacío)
Trampas conocidas
- Happy Eyeballs ignora
gai.conf. Si necesitas que el host hable solo IPv4 (por ejemplo para queacme.shuse un token Cloudflare con allowlist solo IPv4), el típicoprecedence ::ffff:0:0/96 100en/etc/gai.confno basta:curlcon Happy Eyeballs (RFC 8305) lanza la conexión IPv6 con 200 ms de ventaja y siempre gana contra anycast. Para forzar IPv4 hay que quitar IPv6 del host o usarcurl -4por comando. ndppd staticno funciona en 0.2.4 (Debian 13). Usarauto.- CSF y
FORWARD policy DROP— necesitan hook enpost.d. Sin él, las VMs reciben IPv6 pero no pueden enviar (FORWARD bloquea ambos sentidos para flujos nuevos). qm shutdownfalla sinqemu-guest-agenten la VM. Las imágenes Ubuntu cloud no lo traen instalado por defecto — instalarqemu-guest-agentdentro de la VM si quieres shutdown limpio.- MAC regenerado al cambiar de bridge. Si haces
qm set <VMID> --net1 virtio,bridge=vmbrXsin especificar=<MAC>previo, Proxmox regenera el MAC. Cloud-init reescribe netplan en consecuencia. - Una entrada NDP proxy por VM vs
ndppdpara todo el/64. Si tienes pocas VMs estables, puedes prescindir dendppdy ponerip -6 neigh add proxy <ip> dev vmbr0(comopost-upen la stanza devmbr2). Para entornos dinámicosndppdcon reglaautosobre el/64es más cómodo.
Limitaciones / cuándo NO usar este approach
- OVH HG (NIC única + vRack VLAN): el bridge debe configurarse sobre la subinterfaz tagged, y la dinámica puede diferir. No verificado aquí.
- vRack IPv6 (servicio separado de OVH que enruta un
/56específicamente al vRack): si lo tienes contratado es preferible — las VMs pueden estar directamente envmbr1con un/64propio y sin NDP proxy. Este documento NO cubre ese escenario. - Más de un host con el mismo
/64: el/64IPv6 OVH va enrutado a UN solo MAC. Si quieres HA con failover de IPv6 entre varios servidores necesitas otro patrón (BGP, ULA + NAT66, o IP failover OVH con reasignación manual).
Referencias
- OVH — Configure an IPv6 on a VM — guía oficial OVH (cubre solo el lado guest, no menciona NDP proxy).
- mathieu-gilloots.fr — Installation Proxmox 8 avec IPv6 OVH — referencia detallada del approach NDP proxy con
npd6. - greenhoster.fr — IPv6 dans un vRack OVHcloud — variante con bloque IPv6 vRack
/56. - RFC 5737 y RFC 3849 — rangos reservados para documentación (IPv4 e IPv6).
man ndppd.confy/usr/share/doc/ndppd/ndppd.conf-dist.
Documento generado: 2026-05-23 — Abdelkarim Mateos / AichaDigital